介绍
数字信号处理 (DSP) 是处理信号和数据的专用方法,其目的在于加强并修改这些信号。数字信号处理也用于分析信号以确定特定的信息内容。DSP主要用于处理真实世界的信号。这些信号可由数字序列进行转化和表示。我们后来使用数学方法处理信号,从信号中提取特定信息或以某种方式转化信号。
DSP在实时嵌入式系统中非常普遍,在这种系统中,计算的及时性与准确性同样重要。DSP 在这些环境中非常普遍,因为其根据设计,能够非常迅速地执行常见的信号处理操作。DSP 的可编程性允许应用随着时间的推移而不断变化发展,从而为应用供应商提供了众多优势。进行 DSP 编程需要熟悉应用、DSP 硬件架构以及用于编写高效实时软件、并能满足系统最终期限的代码生成工具。
本文是两篇文章中的第一篇,将探讨 DSP 某些重要的软件与系统优化技术,并将解释采用强大处理器开发高效嵌入式应用的某些指导原则。
优化的第一条规则--不要!
在开始任何优化工作之前,您必须了解自己的方向。从性能角度讲,所有软件都是不同的!您必须首先理解瓶颈在哪里。一旦您已经对应用进行了描述,那么接下来就可以开始调整代码。描述应用是指衡量代码每部分所需的时间(或所用的存储器空间或功耗)。软件的某些部分仅执行一次(如初始化)或有限的次数。花很多时间优化这部分代码是不明智的,因为这样做所得的总体节约是相对有限的。很可能的情况是,软件的某些部分会执行许多次,尽管代码本身很短,但执行代码的事实常常说明代码的整体周期需时不菲。如果您能够从这部分代码中节约哪怕一两个周期,那么所得到的节约也会相当显著。在调整并优化进程时,这就是您应当花时间开展工作的地方。
存储器的依赖性
处理器在存储器中存储指令和数据。尽管人们已经创建了许多具有创新性的方法以从存储器中获取指令和数据,但访问指令和数据时总会有性能损失。这就是纯粹的开销了。只要能够减少等待指令或数据存取的时间,不管怎么样,都能够改善应用的整体性能。举例而言,硬件高速缓冲系统将会尽可能多的指令靠近CPU,从而实现快速存取,通常只需一个周期即可,业经验证这能够改善整体性能。DSP 拥有片上存储器,其可存储数据与指令。但数据和指令不能自动放置于片上存储器中。编程员必须对此进行管理,只要管理有效,DSP 就可以利用片上存储器显著提高性能。
嵌入式系统存储器等级中有若干层次(见图1)。第一层是芯片寄存器。这部分存储器用于保存临时和中间数据。编译器在调度指令时使用寄存器。该存储器是速度最快、价格最昂贵的(器件上的寄存器越多,器件体积就越大,这意味着硅晶片上的器件减少,也就是说用更多的硅芯片获得相同数量的器件,您应该明白我的意思吧)。存储器的下一层是高速缓冲系统。它也是即快速又昂贵,用于将指令和数据在使用指令和/或数据前移至靠近 CPU 处。存储器的再下一层是"外部"或"片外"存储器。该存储器会比其他存储器类型的速度慢,而且价格也较便宜。这一般是不使用(存储期限较长)数据和指令时保存的地方。从该存储器存取信息包括更多的信号交换和控制,因此也需要更多时间。实时嵌入式设计人员的主要目的是使您将用到的任何东西尽可能靠近 CPU。这意味着需要从外部存储器获取信息,使其进入速度更快的存储器,并使用诸如直接存储器存取(DMA)等技术,以及编译或架构技术。

为了增强采用流水线操作概念的处理器性能,我们使用了硬件架构技术。流水线处理器的原则与汽车装配线没什么两样。每辆汽车都通过装配线被一步步组装起来。许多辆车同时在装配线上,每辆车位于装配过程的不同环节。在装配线末端会出现一辆新车,紧接着还有另一辆新车跟进,以此类推。人们早就发现,在前一辆车完成之前即开始下一辆新车的装配工作,这种做法的成本效益要高得多。在流水线处理器中,情况也是如此。流水线处理器可在前一项任务完成前开始新任务。完成率就是传入新指令的速率。如图 2a 和 2b 所示,指令的完成时间没有改变。但指令的完成率提高了。
为了进一步改善性能,我们可以使用多个流水线。该方法称作超标量,其进一步利用了平行的概念(见图 2c)。如今某些高性能数字信号处理器(如 Intel i860)就有一个超标量设计。

图2. 非流水线、流水线和超标量执行时间表

具备多个独立执行单元的 DSP 利用平行同时执行多个独立指令,这将为性能改善提供立竿见影的效果。关键在于找到彼此独立的"n"个不同指令。有时,我们通过硬件完成此工作,有时则通过软件来完成(编译)。超长指令字(VLIW)处理器(如 TI 的 C6200 DSP 系列产品)使用编译技术可以在 8 个独立的处理器执行单元上调度最多 8 个彼此独立的指令。指令间的数据依赖性常常将此限制在最高速率之下,但还是能够实现显著的性能。许多情况下,我们可以重新构建算法,以利用架构的优势,从而实现多执行单元的优势。
较之于流水线处理器而言,超标量架构可提供更多的并行处理能力。但是,如果算法或函数不能利用此并行功能的话,那么多余的管道将得不到使用,就会降低能够实现的并行量。编写用作快速运行于流水线处理器上的算法不一定能在超标量处理器上同样高效运行。举例而言,我们可以看看图 4a 所示的算法。该算法的编写利用了流水线处理器的优势。这是在串行处理器上计算多项式的常见方法,因为它不必再计算 p**8, p**7 等。这节约了周期和存储中间值的寄存器。
但就超标量器件而言,这并不是计算表达式的最佳方法。算法中的括号限制了编译器顺序计算表达式的功能。这也使得并行功能无法发挥。如果我们将此表达式分解为几个独立的表达式,那么编译器就可以在超标量器件的并行管道上以任何方便的顺序来安排这些独立的表达式。这样进行的计算利用了较少的指令周期,而采用了更多的寄存器(如图 4b 所示)。
上述实例说明了为什么编程人员必须了解器件架构、编译器以及算法,从而确定执行任何特定函数的最快方法。我们将讨论利用上述高性能设备加速函数计算的其他方法。
rp = (((((((R8*p + R7) * p + R6) * p + R5) * p + R4) * p + R3) * p + R2) * p + R1) * p
图 4a)
p2 = p * p
p3 = p * p * p
.
.
p8 = p * p * p * p * p * p * p * p
---------------------------------------------
R1p1 = R1 * p
R2p2 = R2 * p2
.
.
R8p8 = R8 * p8
----------------------------------------------
rp = 0.0F
rp += R1p1
.
.
rp += R8p8
图 4b)
图4. a)、编写可快速运行于流水线处理器上的算法。B)、 相同算法经修改后在超标量处理器上快速运行。
直接存储器存取
直接存储器存取 (DMA)是无 CPU 介入情况下访问存储器的一种方式。外设用于向内存直接写入并导出数据,这就减轻了 CPU 的负担。DMA 就是另一种类型的CPU,其唯一作用就是快速移动数据,其优势则在于 CPU 可以向 DMA 发出一些指令移动数据,随后就可以再进行原本的工作。DMA 在 CPU 运行的同时移动数据(图 5)。这实际就是另一种利用器件内置并行功能的方法。DMA 在复制大量数据时非常有用。较小的数据块无法受益,因为还要考虑到 DMA 的设置和开销时间,反倒不如直接使用 CPU 合适。但如果明智使用的话,DMA 可以节约大量时间。

图 5. 使用 DMA 而非 CPU 能够显著提升性能
由于访问外部存储器会带来很大的性能损失,且占用 CPU 的代价不菲,因此只要有可能,就应采用 DMA。最好是在实际需要数据前就启动 DMA 操作。这让CPU 同时也有工作可做,且不用强制应用等待数据的移动。随后,当确实需要数据时,数据就已经就位了。应用应当进行检查,以确认操作成功,这将要求检查寄存器。如果操作提前完成,这将对寄存器进行一次查询,但不会产生大量工作,占用宝贵的处理时间。
DMA 的常见用法是将数据移入或移出芯片。CPU 访问片上存储器的速度大大快于其访问片外或外部存储器的速度。将尽可能多的数据放于芯片上是提高性能的最佳途径。如果被处理的数据不能全部同时放于芯片上(如大型阵列),那么数据可使用 DMA 成块地移入或移出芯片。所有数据传输都可在后台进行,同时 CPU 对数据进行实际处理。片上存储器的智能管理和布局可以减少数据必须移入、移出存储器的次数。就如何使用片上存储器开发出智能计划,在这项工作上投入时间和精力是值得的。总体而言,规则就是使用 DMA 将数据移入、移出片上存储器并在芯片上生成结果(图 6)。由于成本和空间原因,大多数 DSP 不具备很多芯片上存储器。这要求编程人员协调算法,以高效利用现有的片上存储器。
为使用 DMA 测量代码确实会产生一些性能损失。根据应用使用 DMA 的多少,代码大小会上升。如果全面启用 DMA,我们曾遇到过代码大小增长 50% 的情况。使用 DMA 还增加了复杂性和应用的同步化。只有在要求高吞吐量的情况下才应使用 DMA。但是,片上存储器的智能布局和使用以及明智地使用 DMA 能够消除大多数访问片外存储器所带来的性能损失。

图 6. 使用 DMA 将数据移入、移出芯片的模板
等待状态与探询
就像存储器和CPU一样,可将DMA视为资源。在DMA操作进行过程中,应用可以等待DMA传输完成,也可以继续处理应用的另一部分,直到数据传输完成为止。每种方法都有其优势和劣势。如果应用等待DMA传输完成,那么它必须探询DMA硬件状态寄存器,直至对比特的设置完成。这要求CPU在循环操作中检查DMA状态寄存器,从而导致浪费宝贵的CPU周期。 如果传输较短,那么这只需几个周期就可完成,等等也是值得的。如果数据传输较长,应用工程师可能希望使用同步化机制,如在传输完成时发出信号标志一样。在这种情况下,应用会在传输发生时通过系统等待信号标志。该应用将与另一个准备运行的应用进行交换。任务交换也会导致开销,因此如果任务交换产生的开销大于对DMA完成进行简单探询带来的开销,那么就不应进行任务交换。等待时间取决于被传输数据的数量。
图7显示了检查传输长度并执行DMA探询操作(如果只需要传输几个字的话)或信号标志等待操作(对较大型数据传输而言)的一些代码。数据大小"平衡"长度取决于处理器以及接口结构,应当建立起原型,以确定最佳大小。
图8显示了等待操作的代码。在这种情况下,应用将进行SEM_pend操作,以等待DMA传输的完成。通过暂时中止当前执行的任务并交换到另一项任务以进行其他处理,可使应用能够进行其他有意义的工作。当操作系统中止一项任务而开始执行另一项任务时,会导致一定量的开销。开销量的大小取决于DSP和操作系统。
图9显示了探询操作的代码。在该例中,应用将继续探询DMA完成状态寄存器以获知操作是否完成。这要求使用CPU来进行探询操作。这样做使CPU无法进行其他有意义的工作。如果传输足够短,那么CPU只需在短时间内探寻状态寄存器,这种方法也就可以更有效。
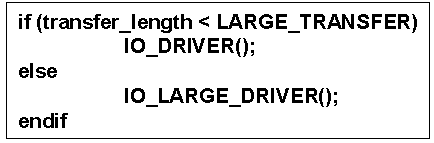
图7. 检查传输长度并调用驱动程序功能的代码片段,其将探询DSP状态寄存器中的DMA完成位,抑或等待操作系统信号标志。
最后决策建立于数据传输数量以及CPU探询必须进行多少周期的基础上。如果探询所需时间少于操作系统交换任务并开始执行新任务的开销,那么这种方法就会更有效。

图 8. 等待 DMA 完成信号标志的代码片段?
图9. 探询 DMA 是否完成的代码片段
内存的管理
DSP 最重要的资源之一就是其本身片上或内部的存储器。这是大多数计算将发生的地方,因为访问该存储器比访问片外或外部存储器要快得多。由于许多 DSP 因为决定不可预见性的缘故都不具备数据高速缓冲存储器,因此软件设计人员将 DSP 内存看作是一种由程序员管理的高速缓冲存储器。与程序员不能控制的处理器硬件高速缓冲存储器数据以提高性能不同,DSP 内部数据存储器在DSP程序员的完全控制之下。使用 DMA,数据可以在后台进出内存,基本或完全不受DSP CPU的干预。如果管理正确有效的话,内存会成为非常有价值的资源。
安排好内存的使用并随时管理数据进入内存的地点,这是相当重要的。考虑到用于众多应用的有限内存量,并非所有的程序数据都能在应用执行时间中储存于内存中。随着时间的推移,数据将被移至内存中,进行处理,可能会被重新使用,并在不需要时移至外部存储器中。图10显示了内部 DSP 存储器在应用执行时可能的存储器映射情况。在应用执行时,不同的数据结构将移至片上存储器中,并最终移出芯片保存到外部存储器中,或在不需要时在内存中将其覆盖。

图10. 必须由程序员管理的 DSP 内存
结论
直接存储器存取 (DMA) 是无需 CPU 干预而访问存储器的一种方法。外设用于向内存直接写入并导出数据,这就减轻了 CPU 的负担。DMA 只是另一种类型的CPU,其唯一作用就是快速移动数据,优势则在于 CPU 可以向 DMA 发出一些指令移动数据,随后就可以再进行原本的工作。程序员应当充分利用 DMA 的功能,特别是对 DSP 系统中常见的、数据强度大的数字处理应用更是如此。DMA能够大大减轻 CPU 的负担,并有助于高效管理数据。
下一次,我们将讨论其他一些利用 DSP 器件架构,并使用编译器调度高效代码的DSP 优化技术,其也能显著改善性能。具体的课题将包括软件流水线和循环展开技术。
参考书目
《TMS320C62X 程序员指南》,德州仪器,1997 年;
《计算机架构,量化的方法》,作者:John L Hennesey 和 David A Patterson , Morgan Kaufmann Publishers 公司1990 年版权所有,Palo Alto, CA。
上一篇:基于TMS320DM642的农药喷洒系统
下一篇:调度器在DSP编程中的应用
推荐阅读最新更新时间:2024-05-13 18:13

- 热门资源推荐
- 热门放大器推荐
 ICCV2023论文汇总:Embodied Vision: Active Agents, Simulation(具身视觉:主动代理、模拟)
ICCV2023论文汇总:Embodied Vision: Active Agents, Simulation(具身视觉:主动代理、模拟) 嵌入式系统软硬件协同设计教程:基于Xilinx Zynq-7000 (符意德)
嵌入式系统软硬件协同设计教程:基于Xilinx Zynq-7000 (符意德) 嵌入式网络那些事:LwIP协议深度剖析与实战演练
嵌入式网络那些事:LwIP协议深度剖析与实战演练










 京公网安备 11010802033920号
京公网安备 11010802033920号