1 主要技术
1.1 virtio缓存队列
Virtio 是半虚拟化 hypervisor中位于设备之上的抽象层, 为异构多核间数据通信提供了最低层的实现。它使用了两个基于异步通知的缓存队列( 一个用于向协处理核发送数据,一个用于从协处理核接收数据)和散列表用于与远程异构处理器进行数据通信。每个缓存队列最多包含有512个缓存,每个缓存的大小限制在512字节以内,缓冲池里面存放着通信数据。为了最大程度减少共享内存,采用环形散列表,散列表每个表项包括了缓存的物理地址和缓存的大小,散列表存放在内存特定地址中,主处理核与协处理核基于互斥机制的共享内存方式进行访问,如图1所示:

图1 异构多核间访问virtio缓存池示意图
采用共享环形散列表进行异构处理核间数据通信的好处主要有几个方面:
1)采用散列表表项表示数据缓存可以减小共享内存区域的大小,提高系统内存使用率,同时允许变长数据传输。
2)采用中断方式通知目的处理器散列表的变化,减少了处理器盲目等待时间,提高了处理器的利用率
3)允许同时传输多个缓存数据,提高了系统通信的吞吐率
1.2 RPMsg消息框架
RPMsg(Remote processor Messaging) 是一个基于virtio技术的用于处理器核间数据通信的消息框架,提供协处理核上电复位管理、消息通信等功能。
1.2.1 协处理核复位管理
主要负责加载程序执行体到协处理核的运行内存中、设置负责虚拟地址映射到物理地址MMU单元,当协处理核遇段错误或内部代码异常时,需要输出直观的出错信息并且提供了恢复机制使得协处理核可以重新使用。
1.2.2 消息通信
RPMsg消息框架是基于virtio缓存队列实现的主处理核和协处理核间进行消息通信框架,RPMsg向系统注册了一条消息总线,并为每个M3协处理核创建相应的总线设备,而多个客户端驱动程序也注册在该消息总线上并分配一个本地地址端口src和远程地址端口dst,当客户端驱动需要发送消息时,会把消息封装成virtio缓存并添加到缓存队列中以完成消息的发送, 当消息总线接收到协处理器送到的消息时会根据消息地址端口dst合理的派送给客户驱动程序进行处理。其示意图如图2所示:
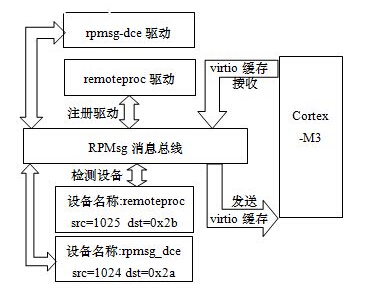
图2 RPMsg消息总线工作示意图
1.3 IVA-HD加速引擎
H.264/MPEG-4 Part 10 是由ITU-T 视频编码专家组和ISO/IEC 运动图像专家组 (MPEG) 联合提出的高度压缩数字视频编解码器标准,被广泛应用于网络流媒体资源、HDTV 等方面。与之前MPEG4、H263 等标准相比,H.264 具有低码率、高画质、高压缩率和高可靠性等特点,适用于干扰严重、丢包率高的信道中传输。
H264解码流程如图3所示,解码器从网络抽象层NAL中接收输入的数据帧,进过熵解码、重新排列后得到量化系数矩阵X,量化系数矩阵在经过反量化和空间变换后得到计算残差Dn,同时通过运动补偿和帧间预测或帧内预测得到预测快Pn, 将Pn和Dn相加结果uFn经过环路滤波得到输出缓存图像Fn。
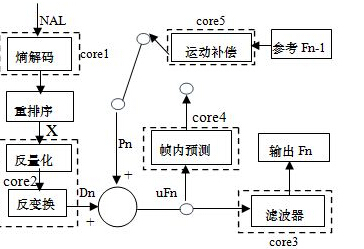
图3 H264解码器工作流程
IVA-HD引擎是针对嵌入式平台进行多媒体编解码加速而设计的第三代硬件加速引擎,其支持H264、MPEG4、MPEG2、H263等常见的视频编解码标准。为了释放CPU,让其更有效的进行数据准备和逻辑功能控制,IVA-HD集成了7个硬件加速引擎,他们和H264解码各个功能模块所对应关系在图3中用虚线框表示,其中加速引擎名称core1-5所对应的模块功能分别是: 熵解码、反量化和反变换、环路滤波、帧内预测、运动补偿。
2 系统设计
全高清H264解码任务由主处理器Cortex-A9和协助处理器Cortex-M3共同完成,Cortex-A9主要负责从多媒体文件中或网络数据流中进行数据的读取、多媒体数据包过滤分离视频流和音频流、构建RPMsg控制消息进过virtio缓存封装发送给协处理核Cortex-M3以设置IVA-HD加速引擎的控制参数、向协处理器发送多媒体数据包进行H264解码、在协处理器完成解码任务后接收图像并通过DRM API及KMS 模块绘制到屏幕上。
平台上有两个Cortex-M3处理核,分为Sys M3和App M3,都运行TI BIOS实时操作系统,其中Sys M3主要负责创建与Cortex-A9通信的virtio缓存队列,对程序执行流程和CPU负载情况进行记录,接收A9发过来的缓存数据并进行参数解析,同时根据缓存中dst参数分派缓存到App M3的相应消息链表中。而App M3协处理器则完成实际的解码工作,App M3将通过运用于嵌入式平台的Codec Engine来完成对IVA-HD加速引擎的操作。App M3将提取消息链表中消息请求相应设置IVA-HD加速引擎的状态和初始化参数,在进行实际解码时会通过codec Engine 来调用IVA-HD加速引擎来完成解码任务并将解码结果通过 缓存队列发送回Cortex-A9处理器。整个系统解码的框架图如图4所示:
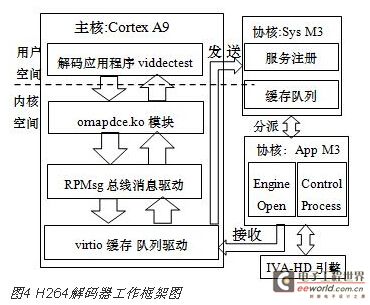
3 系统实现
3.1 Cortex-A9软件实现
Cortex-A9运行Linux操作系统,包括内核模块omapdce.ko和virtio缓存、RPMsg总线驱动程序设计和ffmpeg多媒体库及DRM显示接口调用.3.1.1 virtio缓存队列实现
Virtio缓存队列以共享散列表的方式和协处理器进行数据通信,通过中断方式通知对方散列表的添加,包括以下几个方面:
1)Irq_require()注册中断函数,Register_bus_type(“virtio”)向系统注册virtio总线
2)Regsiter_virtio_driver(&virtio_driver)向virtio总线注册一个驱动客户端,用于创建向RPMsg总线注册的设备。
3)系统在发现协处理器后将通过register_virtio_device(&virtio_device)向virtio总线注册一个设备,设备内部含有创建virtio缓存队列的函数指针
4)virtio_bus->match(&virtio_device,&virtio_driver)函数将匹配virtio_driver与virtio_device是否合适,如果匹配成功,virtio_driver->probe(virtio_device)来创建send_virqueue、recv_virqueue及注册到RPMsg的rpmsg_device,。这样virtio缓存队列就和RPMsg总线联系在一起。
3.1.2 RPMsg消息框架实现
RPMsg总线将挂载许多rpmsg_driver和rpmsg_device,和rpmsg_driver都有本地端口src和目的端口dst属性,每次发送消息时会调用rpmsg_send((void*)data,src,dst)将消息添加到virtio的缓存队列中,而当消息msg达到RPMsg总线时,总线把msg分配给dst属性和msg->dst相同的rpmsg_driver,并调用rpmsg_driver->callback()进行消息处理。
3.1.3 omapdce.ko驱动模块的实现
Omapdce.ko模块将作为一个RPMsg driver,其实现了应用程序引擎相关API的内核实现,主要包括ioctl_engine_open()、ioctl_viddec_create(),ioctl_viddec_control()、ioctl_viddec_process(),他们提供了应用API engine_open、viddec_create()、viddec_control()、viddec_process()的驱动实现,这些驱动函数将调用RPMsg总线rpmsg_send()、rpmsg_recv()与协处理器进行消息通信以完成工作任务。
3.1.4 解码应用viddectest实现
H264解码应用程序viddectest的工作主要分为以下几个方面
1)Linux显示接口DRM初始化,通过Drmopen()函数打开/dev/dri/card0设备文件,获取设备资源drmModeGetResources(),创建帧缓存drmModeAddFB2()及设置输出分辨率及模式drmModeSetCrtc()
2)FFmpeg媒体库的调用,通过AVOpenStreamFile()打开多媒体文件,AVFindStream()分离出音频流和视流,然后依次通过AVGetPacket()读取视频流数据包送去解码器进行解码。
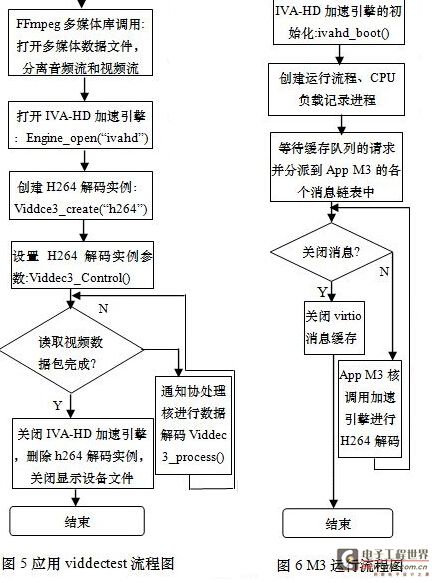
3)加速引擎初始化和利用消息总线进行解码数据通信,通过Engine_open()打开H264解码引擎,Viddec3_create()创建一个解码实例对象,Viddec3_control()设置解码所需的参数,Viddec3_process()将用RPMsg消息总线送出解码数据流并接收解码后的图像缓存数据,其流程图如图5所示:

3.2 Cortex-M3软件实现
双核Cortex-M3运行TI BIOS实时操作系统,负责与主处理核的virtio缓存队列通信及通过codec engine调用IVA-HD加速引擎实现H264解码,运行流程图如图6所示,主要包括以下内容:
1) virqueue_create(&send_queue),virqueue_create(&recv_queue)创建与Cortex-A9主处理核通信的 virtio发送及接收缓存队列。
2) Message_get_queue(&recv_queue)从virtio缓存队列获取主处理核发过来的请求数据,Message_send_queue派发到App M3的消息队列中。
3) App M3将获取消息链表的消息,设置IVA-HD加速引擎的工作状态并初始化,如果为解码消息则通过Codec Engine 调用IVA-HD加速引擎来完成解码过程。
4) 将解码后的图像缓存封装成virtio缓存,调用Message_send_queue()通过virtio缓存队列发送回主处理核A9调用DRM进行显示输出。
4 测试
本文在OMAP4430开发平台上设计实现了基于异构多核的全高清H264解码,为了测试解码器的性能,将针对不同比特率的720P、1080P 的网络视频文件Big_Buck _Bunny_Sunflower 进行解码测试,测试结果如表1所示,同时采用FFmpeg开源库项目的软解码进行测试,其对比图如图7所示
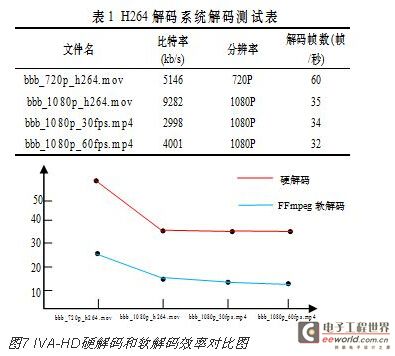
图7 IVA-HD硬解码和软解码效率对比图
从图6可以看出本次设计的H264解码器在解码720P(1280*720)和1080P(1920*1080)视频时分别达到60和34帧每秒,相比FFmpeg开源H264软解码器效率提高了一倍。而普遍全高清流畅视频的帧率为30帧每秒,达到实时解码性能需求。
5 结束语
随着移动互联网时代的到来,在移动终端上流畅播放全高清视频成为任务日常需求。为此本文采用移动Soc OMAP4430异构多核处理器为实验平台,通过基于virtio缓存队列和RPMsg消息框实现了异构多核间多媒体数据通信,同时结合IVA-HD多媒体硬件加速引擎设计了一款全高清H264视频硬解码系统。实验结果表明设计的解码系统比开源FFmpeg软解码器在性能上提升了一倍,达到实时性要求。具有解码速度快、解码过程由硬件加速器完成无需消耗主核运算资源、核间通信效率高、功耗小等优点。
上一篇:开发高可靠性嵌入式系统的7个技巧
下一篇:手机高清摄像头OTP技术详解
推荐阅读最新更新时间:2023-10-12 22:54

 明解 C 语言 (柴田望洋)
明解 C 语言 (柴田望洋) 新一代视频压缩编码标准H.264AVC (毕厚杰 王健)
新一代视频压缩编码标准H.264AVC (毕厚杰 王健) 模拟集成电路设计与仿真
模拟集成电路设计与仿真

Vishay线上图书馆
- 选型-汽车级表面贴装和通孔超快整流器
- 你知道吗?DC-LINK电容在高湿条件下具有高度稳定性
- microBUCK和microBRICK直流/直流稳压器解决方案
- SOP-4小型封装光伏MOSFET驱动器VOMDA1271
- 使用薄膜、大功率、背接触式电阻的优势
- SQJQ140E车规级N沟道40V MOSFET











 京公网安备 11010802033920号
京公网安备 11010802033920号