不过直到最近,计算机都对图片束手无策。比如,除非人为添加一些标签和注释,否则机器就无法理解图片,图片也就是成了无用的文件。但是,这种尴尬的情况正在发生变化。一大批能看懂图片的人工智能技术已经来到人间,下面不妨来看看机器之心的盘点:
谷歌 TensorFlow
5月份谷歌推出 Google Photos时,媒体关注的焦点是:人工智能和图片搜索结合后所产生的强大功能。谷歌声称(并且用户也很快确认),搜寻特定某人,你会找到对方从现在到婴儿时期的照片。搜索品种名,你就能找到相应品种狗的照片。把名字和食品类别结合起来,比如输入「最大披萨」,就能锁定特定图片。

这款应用发布之初,媒体无从得知谷歌究竟研发了多长时间。不过,一些搜索功能在Google+上出现一年多了。
两周前,谷歌以TensorFlow平台形式开源了它的人工智能主体部分。
尽管TensorFlow并不是第一个开源人工智能平台,但是,它是与谷歌强大图片搜索关系最为密切一个。
开源TensorFlow意味着,包括初创公司在内的其他公司,能够利用谷歌的这个开源平台,快速将人工智能和图片结合起来。尽管谷歌并未开放人工智能关键技术,包括在众多服务器上运行的能力。谷歌也没有开放让其如此强大的用户数据库。但是,谷歌的此举毫无疑问将**整个机器学习和人工智能创业生态的发展。
我们也期待着基于TensorFlow的各种震撼新应用能于明年进入市场。
Facebook Photo Magic
Facebook近期开始在Messenger应用上测试一项新功能——Facebook Photo Magic。这是一个可选应用,它会扫描手机相册照片并对它们进行面部识别处理。Photo Magic会识别照片中的人物(他们也是你的Facebook好友),建议你和他们一起分享这些照片。

毫无疑问,这项功能给Facebook带来了双重优势。首先,它鼓励用户更多在Messenger上分享。其次,它改善了识别。但是,仅仅这项便利功能是不够的,用户实际上可以赞成或拒绝在任意灯光条件、角度和其他参数条件下,Facebook使用人工智能对面部和名字进行匹配。Facebook人工智能掌握的照片越多,识别效果也越好。
令人吃惊的是,即使遮住了脸部,Facebook的「面部识别」一样能能识别出你的脸部。这个系统也关注发型、姿势、衣着和身材。(请注意,我们并不清楚Facebook是否已经实现了这种先进系统,但很明显的是,它从用户照片中收集数据。)
Facebook 的Photo Magic拓展了图片库来源,它不仅收集Facebook(社交网站),还收集Messenger(聊天应用)的数据,扩充了数据量。Photo Magic还鼓励赞成或否定匹配结果,提高数据质量。
很明显,Facebook最终目标是识别任意场景中的任何人,即使在看不清脸部的恶劣灯光条件下。毫无疑问,未来Facebook的人工智能会扫描和分析环境,发现可市场化的线索——比如,如果某人在照片里经常打棒球,广告商就可以利用这个信息锁定棒球迷,尽管他在上传照片的文字里并没有表露出这种兴趣。
毫无疑问,他们也打算通过观察图片中一起出现的人,进一步建立社交图谱。
微软牛津项目(Project Oxford)
微软日前也更新它的牛津项目,这是一个工具包,让开发者通过旗下的Azure云平台,使用微软的人工智能系统。
这个工具包支持人工智能各个方面的应用,包括口语,视频和其他媒体。但是,最震撼和最强大的功能莫过于牛津项目现在支持开发者通过牛津人脸应用平台接口项目( Project Oxford Face API)检测图片中的人物表情。

譬如,用牛津项目处理一张包含5个人的照片,识别照片中的脸以及每个人的表情——快乐,愤怒或恶心。
这项功能在新的高度,像人类一样「理解」图片质量。观看他人照片时,人们关注的最重要特征就是个人或群体的情感状况。
Pinterest Visual Search
Pinterest日前发布了全新的图片搜索功能,它能帮助用户发现更多的信息甚至帮助购买他们在固定照片里看到的产品。
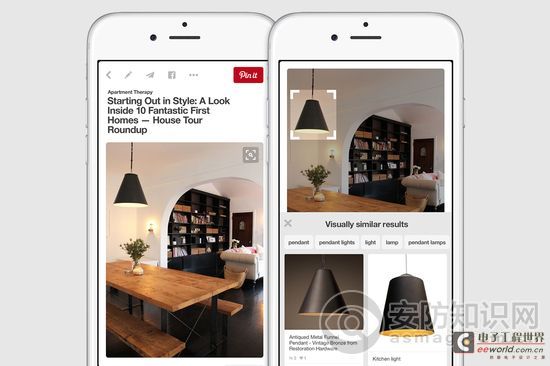
首先,在 Pinterest的图片中选中任一物体(来回拖动一个盒状标识)。然后,搜索工具会找到具有相似图案和颜色的相似物,系统会将最匹配的结果链接到购买按钮上,点击这里就能购买该产品。
这个功能是以伯克利视觉和学习中心(Berkeley Vision and Learning Center)的深度学习人工智能为基础的。
这种照片人工智能应用可以说是万维网照片的雏形,在这个万维网中,每张图片中的每个物体都与等同物或者相似物、相关物彼此关联。
CloudSight
一家名为CamFind的图片识别和视觉搜索公司,今年推出了一个「云视觉」(CloudSight)的公共应用平台接口。

这个API支持开发者使用CamFind的人工智能分析图片内容。这样的扫描大多数情况下具有高度特定性,比如,能识别汽车的制造和模型,或者狗的品种以及食品的具体类型。一旦分析出图片中的物品,开发者就可以使用这些信息来获取网络上的文字信息。
Deepomatic
Deepomatic开发了一种服务型软件智能搜索引擎,它能识别图片中各种各样的数据。Deepomatic热衷时尚。它不仅匹配颜色,图案和其他数据,还能识别图片中的物品,并将它与一个全面的时尚产品数据库进行匹配。

Deepomatic网站声称,其技术模拟了人类大脑接收视觉信息的方式并用这种方式来理解各种概念。
远大前景
每当想到这样一个令人惊喜的新世界:能够理解照片内容的人工智能将无处不在,具有强大扩展潜力且唾手可得时,这些无限可能性就会令人叹为观止。
而且,这仅仅是一个开始。在绝大多数情况下,这项技术几乎都能通过API,开源程序或服务化处理得以应用实现,因此,我们已经站在了未来世界的入口:图像AI将和网络搜索一样普及,成为这个世界的一个基本特征。为了真正模拟人工智能,计算机必须有视觉,现在它们有了。
上一篇:盘点一下能让你的生活更加轻松的智能家居系统
下一篇:智能安防,做你所想
推荐阅读最新更新时间:2024-03-16 11:17

 人工智能及其应用 (蔡自兴)
人工智能及其应用 (蔡自兴) 控制系统计算机辅助设计 — MATLAB语言与应用
控制系统计算机辅助设计 — MATLAB语言与应用- 米尔T527系列核心板,高性能车载视频监控、部标一体机方案
- Akamai 全新视频工作流程功能强化媒体平台控制能力
- 紫光同芯推出全球首颗开放式架构安全芯片E450R 已获国密二级认证
- 品英Pickering公司携多款模块化信号开关和仿真解决方案亮相国防电子展
- 派克汉尼汾推出适用于现场监测和诊断的测量设备 Service Master COMPACT
- 连接与距离: 安防摄像头新气象—— Wi-Fi HaLow 带来更远传输距离和更低功耗
- 思特威携多款重磅产品强势亮相2023 CPSE安博会
- 双轮驱动,云天励飞推出12TOPS边缘视觉SoC
- 丰田汽车因信息泄露案接受日本行政指导 涉及241万条用户数据










 京公网安备 11010802033920号
京公网安备 11010802033920号