摘要:提出一种基于OFDM的电力线宽带高速通信系统的实现方案讨论了OFDM应用于电力线载波通信的原理,探讨了通信系统调制解调部分的硬件实现和软件流程,并对其关键的FFT算法进行了优化。
关键词:电力线载波 DSP OFDM FFT
利用电力线作为信道进行通信是解决“最后一公里”问题的一个很好的方法。然而电力线作为通信信道,存在着高噪声、多径效应和衰落的特点。OFDM技术能够在抗多径干扰、信号衰减的同时保持较高的数据传输速率,在具体实现中还能够利用离散傅立叶变换简化调制解调模块的复杂度,因此它在电力线高速通信系统中的应用有着非常乐观的前景。文中给出一种基于正交频分复用技术(OFDM技术)的调制解调器的设计方案。
1 OFDM原理
OFDM全称为正交频分复用(Orthogonal Frequency Division Multiplexing),其基本思想是把高速数据流经过串/并变换,分成几个低比特率的数据流,经过编码、交织,它们之间具有一定的相关性,然后用这些低速率的数据流调制多个正交的子载波并迭加在一起构成发送信号。每个数据流仅占用带宽的一部分,系统由许多子载波组成。在接收端用同样数量的载波对发送信号进行相干接收,获得低速率信息数据后,再通过并/串变换得到原来的高速信号。从而降低子载波上的码率,加长码元的持续时间,加强时延扩展的抵抗力。
在OFDM中,为了提高频带利用率,令各载波上的信号频谱相互重叠,但载波间隔的选择要使这些载波在整个符号周期上正交,即相加于符号周期上的任何两个子载波乘积为零。这样,即使各载波上的信号频谱间存在重叠,也能无失真复原。当载波间最小间隔等于符号周期的倒数的整数倍时,可满足正交性条件。实际上为实现最大频谱效率,一般取载波间最小间隔等于符号周期的倒数。
OFDM允许各载波间频率互相混叠,采用了基于载波频率正交的IFFT/FFT调制,直接在基带处理。1971年,Weinstein和Ebert将DFT引入到并行传输系统的调制解调部分。应用时去掉了频分复用所需要的子载波振荡器组、解调部分的带通滤波器组,并且可以利用FFT的专用器件实现全数字化的调制解调过程。
OFDM技术具有频谱利用率高、抗多径干扰能力强、易于实现等优点,尤其适于多径效应严重的宽带传输系统,是一门具有发展前景、非常适合电力线高速数字通信的新兴技术。
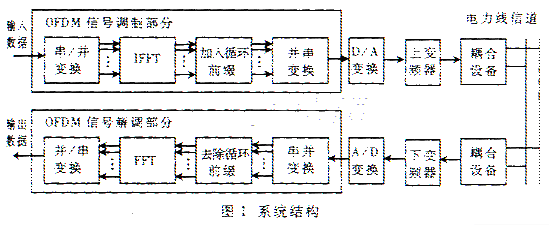 2 电力线载波通信系统结构
Homeplug是工业界第一个电力线家庭网络标准。系统参考Homeplug采用的频谱范围4.5MHz~21MHz,并在Homeplug物理参数的基础上确定本系统参数为:
采样频率fs=1/T = 15MHz
数据符号时间Td = 256%26;#215;T=17.07μs
循环前缀时间Tcp = 172%26;#215;T=11.47μs
OFDM符号时间Ts = 428%26;#215;T=28.5μs
数据子载波数为256
子载波间隔Δf=1/Td=0.05858MHz
总子载波占用带宽 N%26;#215;Δf=15MHz
由于加入了11.47μs的循环前缀,系统可以消除11.47μs以内的回波干扰。但是同时也付出频带利用率仅0.59B/Hz和损失功率2.23dB的代价。考虑到电力线恶劣的通信环境,付出的代价是值得的。
电力线高速通信系统的系统结构如图1所示。输入数据在OFDM信号调制部分依次经过串/并变换、IFFT、加入循环前缀、并/串变换后,输出调制后的信号,其频带范围为0~15MHz、数据速率为8.97MB。经过调制的信号经过数/模变换和上变频后,通过系统耦合部分进入电力线。
电力线上的信号通过系统耦合部分,输出的信号通过下变频、模/数变换后输入给OFDM信号解调部分。在经过串/并变换、去除循环前缀、FFT、并/串变换后,输出串行数据流。
3 OFDM调制解调器的硬件实现
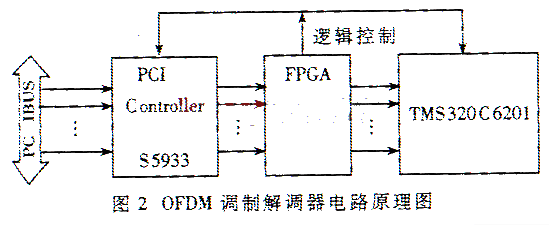
基于TMS320C6201的OFDM调制解调器的硬件实现分别如图2和图31所示。PCI总线实现OFDM系统和计算机之间的通信。S5933是32bit PCI控制器。FPGA是系统的控制核心,系统的逻辑控制信号及时钟由FPGA提供。DSP部分为系统的核心,完成OFDM的调制与解调。
PCI总线是宽度为32bits或64bits的地址数据复用线,支持猝发传输,数据率为132Mbps,可满足高速数据要求。PCI总线能自动配置参数,定义配置空间,使设备具备自动配置功能,支持即插即用,采用多路复用技术,支持多处理器64位寻址、5V和3.3V环境。其独特的同步操作及对总线主控功能,可确保CPU能与总线同步操作,而无需等待总线完成任务。
S5933是AMCCApplied Micro Circuits Corporation公司开发的32bit PCI控制器,具备强大、灵活的PCI接口功能,适用于高速数据传输场合。S5933芯片的特点是符合PCI2.1规范,支持PCI主、从两种工作方式,支持多种数据传输方式,适用于不同的数据传输场合,支持PCI全速传输,提供8/16/32bit的Add-On用户总线,有高低字节顺序调整功能,支持穿行和并行的BOOT/POST码功能,160脚PQFP封装。
DSP部分选用TI公司的TMS320C6201。TMS320C6201有32位的外部存储接口EMIF,为CPU访问外围设备提供了无缝接口。为了便于多信道数字信号处理,TMS320C6201配备了多信道带缓冲能力的串口McBSP。McBSP的功能非常强大,除具有一般DSP串口功能之外,还可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同标准。TMS32C6201提供的16位主机接口(HPI)使得主机设备可以直接访问DSP的存储空间。通过内部或外部存储空间,主机可以与DSP交换信息,也可以利用HPI直接访问映射进存储空间的外围设备。TMS320C6201的DMA控制器有四个独立的可编程通道,可以同时进行四种不同的DMA操作。
2 电力线载波通信系统结构
Homeplug是工业界第一个电力线家庭网络标准。系统参考Homeplug采用的频谱范围4.5MHz~21MHz,并在Homeplug物理参数的基础上确定本系统参数为:
采样频率fs=1/T = 15MHz
数据符号时间Td = 256%26;#215;T=17.07μs
循环前缀时间Tcp = 172%26;#215;T=11.47μs
OFDM符号时间Ts = 428%26;#215;T=28.5μs
数据子载波数为256
子载波间隔Δf=1/Td=0.05858MHz
总子载波占用带宽 N%26;#215;Δf=15MHz
由于加入了11.47μs的循环前缀,系统可以消除11.47μs以内的回波干扰。但是同时也付出频带利用率仅0.59B/Hz和损失功率2.23dB的代价。考虑到电力线恶劣的通信环境,付出的代价是值得的。
电力线高速通信系统的系统结构如图1所示。输入数据在OFDM信号调制部分依次经过串/并变换、IFFT、加入循环前缀、并/串变换后,输出调制后的信号,其频带范围为0~15MHz、数据速率为8.97MB。经过调制的信号经过数/模变换和上变频后,通过系统耦合部分进入电力线。
电力线上的信号通过系统耦合部分,输出的信号通过下变频、模/数变换后输入给OFDM信号解调部分。在经过串/并变换、去除循环前缀、FFT、并/串变换后,输出串行数据流。
3 OFDM调制解调器的硬件实现
基于TMS320C6201的OFDM调制解调器的硬件实现分别如图2和图31所示。PCI总线实现OFDM系统和计算机之间的通信。S5933是32bit PCI控制器。FPGA是系统的控制核心,系统的逻辑控制信号及时钟由FPGA提供。DSP部分为系统的核心,完成OFDM的调制与解调。
PCI总线是宽度为32bits或64bits的地址数据复用线,支持猝发传输,数据率为132Mbps,可满足高速数据要求。PCI总线能自动配置参数,定义配置空间,使设备具备自动配置功能,支持即插即用,采用多路复用技术,支持多处理器64位寻址、5V和3.3V环境。其独特的同步操作及对总线主控功能,可确保CPU能与总线同步操作,而无需等待总线完成任务。
S5933是AMCCApplied Micro Circuits Corporation公司开发的32bit PCI控制器,具备强大、灵活的PCI接口功能,适用于高速数据传输场合。S5933芯片的特点是符合PCI2.1规范,支持PCI主、从两种工作方式,支持多种数据传输方式,适用于不同的数据传输场合,支持PCI全速传输,提供8/16/32bit的Add-On用户总线,有高低字节顺序调整功能,支持穿行和并行的BOOT/POST码功能,160脚PQFP封装。
DSP部分选用TI公司的TMS320C6201。TMS320C6201有32位的外部存储接口EMIF,为CPU访问外围设备提供了无缝接口。为了便于多信道数字信号处理,TMS320C6201配备了多信道带缓冲能力的串口McBSP。McBSP的功能非常强大,除具有一般DSP串口功能之外,还可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同标准。TMS32C6201提供的16位主机接口(HPI)使得主机设备可以直接访问DSP的存储空间。通过内部或外部存储空间,主机可以与DSP交换信息,也可以利用HPI直接访问映射进存储空间的外围设备。TMS320C6201的DMA控制器有四个独立的可编程通道,可以同时进行四种不同的DMA操作。
 4 OFDM在DSP上的软件实现
调制部分的子程序被系统调用前,发送的数据已装入数据存储器。子程序被调用时,数据区的首地址以及长度被作为入口参数传递给子程序。程序执行时首先进行一系列的配置工作,如配置DSP片内外设以及数模转换器的各种参数等。之后,串口中断产生,中断服务程序自动依次读取发送存储器中的内容,经串口输出给数模转换器。然后程序从数据存储区读取一帧数据,并行放入IFFT工作区的相应位置,随后进行IFFT以及加入循环前缀(即复制数据的后若干位插入到数据的前段)。所得数据存入发送存储器以便中断服务程序将其输出。
解调部分的程序首先执行DSP片内外设以及模数转换器的配置,然后开串行口,接收中断,使接收中断程序接收来自模数转换器的采样数据,并将采样数据依次存入接收存储器。每得到一帧数据,程序首先去除循环前缀(即删去数据的前若干位),然后对去除循环前缀后的数据进行FFT变换。
图3 OFDM调制解调器电路原理图
5 FFT在TMS320C6201上的优化算法
表1给出256点Radix2FFT和Radix4FFT在TMS320C6201上所需的指令周期,以及在不同的工作频率下完成FFT所需的时间。
由表1可以看出,在TMS320C6201上采用Raidx4算法比采用Radix2算法更加高效。并且,为了满足系统需求,即在17.07μs之内完成256个复数点的FFT运算,TMS320C6201必须采用200MHz的工作频率。
表1 6201上实现256点FFT所需的时间
TMS320C6201工作频率
256点复数FFT运算所需的总指令周期数
256点FFT所需时间
R2
100MHz
4225
42.25μs
200MHz
4225
21.1μs
R4
100MHz
2763
27.63μs
200MHz
2763
13.8μs
TMS320C6201的数据通路和流水线工作方式是对算法进行优化从而获得高性能的基础。TMS320C6201有两个可以进行数据处理的数据通路A和B2,每个通路有4个功能单元(.L.S.M.D)和一个包括16个32位寄存器的寄存器组。功能单元执行逻辑、位移、乘法、加法和数据寻址等操作。两个数据寻址单元(.D1和.D2)专门负责寄存器组和存储器之间的数据传递。在同一时刻,这些功能单元能够并行地执行多条指令。TMS320C6201对任何指令的操作都能分为几个子操作,每个子操作由不同单元完成。对每个单元来说,每个时钟周期可进入一条新指令,这样在不同周期内,不同单元可以处理不同的指令,这种工作方式称为“流水线”工作方式。TMS320C6201的特殊结构,可使8条指令同时通过流水线的每个节拍,从而大大提高了机器的吞吐量。
为使代码达到最大效率,程序将尽可能将指令安排为并行执行。为使指令并行操作,程序确定指令间的相关性,即一条指令必须发生在另一条指令之后。根据TMS320C6201的数据通路和流水线工作方式,在此给出一种高效实现16点Radix4FFT的方法。其基本思想是分解传统的FFT蝶型算法循环体,将其分别展开在A、B通路内计算两个FFT蝶型算法。每个蝶型算法分别只分配自己这一侧的寄存器组和功能单元。这样在循环体内两个蝶型算法是完全不相关的,能够并行执行。下面给出基于C.S.Burrus和T.W.Parks的Radix4FFT算法3的优化算法的代码实现。
void radix4int n short x short w
int n1 n2 ie wa1 wa2 wa3 wb1 wb2 wb3 ia0 ia1 ia2 ia3 ib0 ib1 ib2
ib3 j k
short ta tb ra1 ra2 rb1 rb2 sa1 sa2 sb1 sb2 coa1 coa2 coa3 cob1
cob2 cob3 sia1 sia2 sia3 sib1 sib2 sib3
n2=n
ie=1
fork=nk>1k>>=2
//number of stage
n1=n2
n2>>=2 // distance between input datas
wa1=0
forj=0j<n2j+=2 //number of butterfies perstage
wb1=wa1+ie
wa2=wa1+wa1
wb2=wb1+wb1 //since heremost of the folow-
ering two instructions are parallel
wa3=wa2+wa1
wb3=wb2+wb1
coa1=wwa12+1
cob1=wwb12+1
sia1=wwa12
sib1=wwb12
coa2=wwa22+1
cob2=wwb22+1
sia2=wwa22
sib2=wwb22
coa3=wwa32+1
cob3=wwb32+1
sia3=wwa32
sib3=wwb32
wa1=wb1+ie
foria0=j ib0=j+1 ia0<n ia0+=n1 ib0+=n1
//loop of two butterflies caculation
ia1=ia0+n2
ib1=ib0+n2
ia2=ia1+n2
ib2=ib1+n2
ia3=ia2+n2
ib3=ib2+n2
ra1=x2ia0+x2ia2
rb1=x2ib0+x2ib2
ra1=x2ia0-x2ia2
rb1=x2ib0-x2ib2
ta=x2ia1+x2ia3
tb=x2ib1+x2ib3
x2ia0=ra1+ta // x2ia0
x2ib0=rb1+tb // x2ia0
ra1=ra1-ta
rb1=rb1-tb
sa1=x2ia0+1+x2ia2+1
sb1=x2ib0+1+x2ib2+1
sa2=x2ia0+1-x2ia2+1
sb2=x2ib0+1-x2ib2+1
ta=x2ia1+1+x2ia3+1
tb=x2ib1+1+x2ib3+1
x2ia0+1=sa1+ta
x2ib0+1=sb1+tb
sa1=sa1-ta
sb1=sb1-tb
x2ia2=ra1coa2+sa1sia2>>15
x2ib2=rb1cob2+sb2sib2 >>15
x2ia2+1=sa1coa2-ra1sia2 >>15
x2ib2+1=sb1cob2-rb1sib2 >>15
ta=x2ia1+1-x2ia3+1
ra1=ra2+ta
rb1=rb2+tb
ra2=ra2-ta
rb2=rb2-tb
ta=x2ia1-x2ia3
tb=x2ib1-x2ib3
sa1=sa2-ta
sb1=sb2-tb
sa2=sa2+ta
sb2=sb2+tb
x2ia1=ra1coa1+sa1sia1 >>15
x2ib1=rb1cob1+sb1sib1 >>15
x2ia1+1=sa1coa1-ra1sia1 >>15
x2ib1+1=sb1cob1-rb1sib1 >>15
x2ia3=ra2coa3+sa2sia3 >>15
x2ib3=rb2cob3+sb2sib3 >>15
x2ia3+1=sa2coa3-ra2sia3 >>15
x2ib3+1=sb2cob3-rb2sib3 >>15
ie <<=2
4 OFDM在DSP上的软件实现
调制部分的子程序被系统调用前,发送的数据已装入数据存储器。子程序被调用时,数据区的首地址以及长度被作为入口参数传递给子程序。程序执行时首先进行一系列的配置工作,如配置DSP片内外设以及数模转换器的各种参数等。之后,串口中断产生,中断服务程序自动依次读取发送存储器中的内容,经串口输出给数模转换器。然后程序从数据存储区读取一帧数据,并行放入IFFT工作区的相应位置,随后进行IFFT以及加入循环前缀(即复制数据的后若干位插入到数据的前段)。所得数据存入发送存储器以便中断服务程序将其输出。
解调部分的程序首先执行DSP片内外设以及模数转换器的配置,然后开串行口,接收中断,使接收中断程序接收来自模数转换器的采样数据,并将采样数据依次存入接收存储器。每得到一帧数据,程序首先去除循环前缀(即删去数据的前若干位),然后对去除循环前缀后的数据进行FFT变换。
图3 OFDM调制解调器电路原理图
5 FFT在TMS320C6201上的优化算法
表1给出256点Radix2FFT和Radix4FFT在TMS320C6201上所需的指令周期,以及在不同的工作频率下完成FFT所需的时间。
由表1可以看出,在TMS320C6201上采用Raidx4算法比采用Radix2算法更加高效。并且,为了满足系统需求,即在17.07μs之内完成256个复数点的FFT运算,TMS320C6201必须采用200MHz的工作频率。
表1 6201上实现256点FFT所需的时间
TMS320C6201工作频率
256点复数FFT运算所需的总指令周期数
256点FFT所需时间
R2
100MHz
4225
42.25μs
200MHz
4225
21.1μs
R4
100MHz
2763
27.63μs
200MHz
2763
13.8μs
TMS320C6201的数据通路和流水线工作方式是对算法进行优化从而获得高性能的基础。TMS320C6201有两个可以进行数据处理的数据通路A和B2,每个通路有4个功能单元(.L.S.M.D)和一个包括16个32位寄存器的寄存器组。功能单元执行逻辑、位移、乘法、加法和数据寻址等操作。两个数据寻址单元(.D1和.D2)专门负责寄存器组和存储器之间的数据传递。在同一时刻,这些功能单元能够并行地执行多条指令。TMS320C6201对任何指令的操作都能分为几个子操作,每个子操作由不同单元完成。对每个单元来说,每个时钟周期可进入一条新指令,这样在不同周期内,不同单元可以处理不同的指令,这种工作方式称为“流水线”工作方式。TMS320C6201的特殊结构,可使8条指令同时通过流水线的每个节拍,从而大大提高了机器的吞吐量。
为使代码达到最大效率,程序将尽可能将指令安排为并行执行。为使指令并行操作,程序确定指令间的相关性,即一条指令必须发生在另一条指令之后。根据TMS320C6201的数据通路和流水线工作方式,在此给出一种高效实现16点Radix4FFT的方法。其基本思想是分解传统的FFT蝶型算法循环体,将其分别展开在A、B通路内计算两个FFT蝶型算法。每个蝶型算法分别只分配自己这一侧的寄存器组和功能单元。这样在循环体内两个蝶型算法是完全不相关的,能够并行执行。下面给出基于C.S.Burrus和T.W.Parks的Radix4FFT算法3的优化算法的代码实现。
void radix4int n short x short w
int n1 n2 ie wa1 wa2 wa3 wb1 wb2 wb3 ia0 ia1 ia2 ia3 ib0 ib1 ib2
ib3 j k
short ta tb ra1 ra2 rb1 rb2 sa1 sa2 sb1 sb2 coa1 coa2 coa3 cob1
cob2 cob3 sia1 sia2 sia3 sib1 sib2 sib3
n2=n
ie=1
fork=nk>1k>>=2
//number of stage
n1=n2
n2>>=2 // distance between input datas
wa1=0
forj=0j<n2j+=2 //number of butterfies perstage
wb1=wa1+ie
wa2=wa1+wa1
wb2=wb1+wb1 //since heremost of the folow-
ering two instructions are parallel
wa3=wa2+wa1
wb3=wb2+wb1
coa1=wwa12+1
cob1=wwb12+1
sia1=wwa12
sib1=wwb12
coa2=wwa22+1
cob2=wwb22+1
sia2=wwa22
sib2=wwb22
coa3=wwa32+1
cob3=wwb32+1
sia3=wwa32
sib3=wwb32
wa1=wb1+ie
foria0=j ib0=j+1 ia0<n ia0+=n1 ib0+=n1
//loop of two butterflies caculation
ia1=ia0+n2
ib1=ib0+n2
ia2=ia1+n2
ib2=ib1+n2
ia3=ia2+n2
ib3=ib2+n2
ra1=x2ia0+x2ia2
rb1=x2ib0+x2ib2
ra1=x2ia0-x2ia2
rb1=x2ib0-x2ib2
ta=x2ia1+x2ia3
tb=x2ib1+x2ib3
x2ia0=ra1+ta // x2ia0
x2ib0=rb1+tb // x2ia0
ra1=ra1-ta
rb1=rb1-tb
sa1=x2ia0+1+x2ia2+1
sb1=x2ib0+1+x2ib2+1
sa2=x2ia0+1-x2ia2+1
sb2=x2ib0+1-x2ib2+1
ta=x2ia1+1+x2ia3+1
tb=x2ib1+1+x2ib3+1
x2ia0+1=sa1+ta
x2ib0+1=sb1+tb
sa1=sa1-ta
sb1=sb1-tb
x2ia2=ra1coa2+sa1sia2>>15
x2ib2=rb1cob2+sb2sib2 >>15
x2ia2+1=sa1coa2-ra1sia2 >>15
x2ib2+1=sb1cob2-rb1sib2 >>15
ta=x2ia1+1-x2ia3+1
ra1=ra2+ta
rb1=rb2+tb
ra2=ra2-ta
rb2=rb2-tb
ta=x2ia1-x2ia3
tb=x2ib1-x2ib3
sa1=sa2-ta
sb1=sb2-tb
sa2=sa2+ta
sb2=sb2+tb
x2ia1=ra1coa1+sa1sia1 >>15
x2ib1=rb1cob1+sb1sib1 >>15
x2ia1+1=sa1coa1-ra1sia1 >>15
x2ib1+1=sb1cob1-rb1sib1 >>15
x2ia3=ra2coa3+sa2sia3 >>15
x2ib3=rb2cob3+sb2sib3 >>15
x2ia3+1=sa2coa3-ra2sia3 >>15
x2ib3+1=sb2cob3-rb2sib3 >>15
ie <<=2
引用地址:基于DSP的电力线载波OFDM调制解调器
2 电力线载波通信系统结构
Homeplug是工业界第一个电力线家庭网络标准。系统参考Homeplug采用的频谱范围4.5MHz~21MHz,并在Homeplug物理参数的基础上确定本系统参数为:
采样频率fs=1/T = 15MHz
数据符号时间Td = 256%26;#215;T=17.07μs
循环前缀时间Tcp = 172%26;#215;T=11.47μs
OFDM符号时间Ts = 428%26;#215;T=28.5μs
数据子载波数为256
子载波间隔Δf=1/Td=0.05858MHz
总子载波占用带宽 N%26;#215;Δf=15MHz
由于加入了11.47μs的循环前缀,系统可以消除11.47μs以内的回波干扰。但是同时也付出频带利用率仅0.59B/Hz和损失功率2.23dB的代价。考虑到电力线恶劣的通信环境,付出的代价是值得的。
电力线高速通信系统的系统结构如图1所示。输入数据在OFDM信号调制部分依次经过串/并变换、IFFT、加入循环前缀、并/串变换后,输出调制后的信号,其频带范围为0~15MHz、数据速率为8.97MB。经过调制的信号经过数/模变换和上变频后,通过系统耦合部分进入电力线。
电力线上的信号通过系统耦合部分,输出的信号通过下变频、模/数变换后输入给OFDM信号解调部分。在经过串/并变换、去除循环前缀、FFT、并/串变换后,输出串行数据流。
3 OFDM调制解调器的硬件实现
基于TMS320C6201的OFDM调制解调器的硬件实现分别如图2和图31所示。PCI总线实现OFDM系统和计算机之间的通信。S5933是32bit PCI控制器。FPGA是系统的控制核心,系统的逻辑控制信号及时钟由FPGA提供。DSP部分为系统的核心,完成OFDM的调制与解调。
PCI总线是宽度为32bits或64bits的地址数据复用线,支持猝发传输,数据率为132Mbps,可满足高速数据要求。PCI总线能自动配置参数,定义配置空间,使设备具备自动配置功能,支持即插即用,采用多路复用技术,支持多处理器64位寻址、5V和3.3V环境。其独特的同步操作及对总线主控功能,可确保CPU能与总线同步操作,而无需等待总线完成任务。
S5933是AMCCApplied Micro Circuits Corporation公司开发的32bit PCI控制器,具备强大、灵活的PCI接口功能,适用于高速数据传输场合。S5933芯片的特点是符合PCI2.1规范,支持PCI主、从两种工作方式,支持多种数据传输方式,适用于不同的数据传输场合,支持PCI全速传输,提供8/16/32bit的Add-On用户总线,有高低字节顺序调整功能,支持穿行和并行的BOOT/POST码功能,160脚PQFP封装。
DSP部分选用TI公司的TMS320C6201。TMS320C6201有32位的外部存储接口EMIF,为CPU访问外围设备提供了无缝接口。为了便于多信道数字信号处理,TMS320C6201配备了多信道带缓冲能力的串口McBSP。McBSP的功能非常强大,除具有一般DSP串口功能之外,还可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同标准。TMS32C6201提供的16位主机接口(HPI)使得主机设备可以直接访问DSP的存储空间。通过内部或外部存储空间,主机可以与DSP交换信息,也可以利用HPI直接访问映射进存储空间的外围设备。TMS320C6201的DMA控制器有四个独立的可编程通道,可以同时进行四种不同的DMA操作。
4 OFDM在DSP上的软件实现
调制部分的子程序被系统调用前,发送的数据已装入数据存储器。子程序被调用时,数据区的首地址以及长度被作为入口参数传递给子程序。程序执行时首先进行一系列的配置工作,如配置DSP片内外设以及数模转换器的各种参数等。之后,串口中断产生,中断服务程序自动依次读取发送存储器中的内容,经串口输出给数模转换器。然后程序从数据存储区读取一帧数据,并行放入IFFT工作区的相应位置,随后进行IFFT以及加入循环前缀(即复制数据的后若干位插入到数据的前段)。所得数据存入发送存储器以便中断服务程序将其输出。
解调部分的程序首先执行DSP片内外设以及模数转换器的配置,然后开串行口,接收中断,使接收中断程序接收来自模数转换器的采样数据,并将采样数据依次存入接收存储器。每得到一帧数据,程序首先去除循环前缀(即删去数据的前若干位),然后对去除循环前缀后的数据进行FFT变换。
图3 OFDM调制解调器电路原理图
5 FFT在TMS320C6201上的优化算法
表1给出256点Radix2FFT和Radix4FFT在TMS320C6201上所需的指令周期,以及在不同的工作频率下完成FFT所需的时间。
由表1可以看出,在TMS320C6201上采用Raidx4算法比采用Radix2算法更加高效。并且,为了满足系统需求,即在17.07μs之内完成256个复数点的FFT运算,TMS320C6201必须采用200MHz的工作频率。
表1 6201上实现256点FFT所需的时间
TMS320C6201工作频率
256点复数FFT运算所需的总指令周期数
256点FFT所需时间
R2
100MHz
4225
42.25μs
200MHz
4225
21.1μs
R4
100MHz
2763
27.63μs
200MHz
2763
13.8μs
TMS320C6201的数据通路和流水线工作方式是对算法进行优化从而获得高性能的基础。TMS320C6201有两个可以进行数据处理的数据通路A和B2,每个通路有4个功能单元(.L.S.M.D)和一个包括16个32位寄存器的寄存器组。功能单元执行逻辑、位移、乘法、加法和数据寻址等操作。两个数据寻址单元(.D1和.D2)专门负责寄存器组和存储器之间的数据传递。在同一时刻,这些功能单元能够并行地执行多条指令。TMS320C6201对任何指令的操作都能分为几个子操作,每个子操作由不同单元完成。对每个单元来说,每个时钟周期可进入一条新指令,这样在不同周期内,不同单元可以处理不同的指令,这种工作方式称为“流水线”工作方式。TMS320C6201的特殊结构,可使8条指令同时通过流水线的每个节拍,从而大大提高了机器的吞吐量。
为使代码达到最大效率,程序将尽可能将指令安排为并行执行。为使指令并行操作,程序确定指令间的相关性,即一条指令必须发生在另一条指令之后。根据TMS320C6201的数据通路和流水线工作方式,在此给出一种高效实现16点Radix4FFT的方法。其基本思想是分解传统的FFT蝶型算法循环体,将其分别展开在A、B通路内计算两个FFT蝶型算法。每个蝶型算法分别只分配自己这一侧的寄存器组和功能单元。这样在循环体内两个蝶型算法是完全不相关的,能够并行执行。下面给出基于C.S.Burrus和T.W.Parks的Radix4FFT算法3的优化算法的代码实现。
void radix4int n short x short w
int n1 n2 ie wa1 wa2 wa3 wb1 wb2 wb3 ia0 ia1 ia2 ia3 ib0 ib1 ib2
ib3 j k
short ta tb ra1 ra2 rb1 rb2 sa1 sa2 sb1 sb2 coa1 coa2 coa3 cob1
cob2 cob3 sia1 sia2 sia3 sib1 sib2 sib3
n2=n
ie=1
fork=nk>1k>>=2
//number of stage
n1=n2
n2>>=2 // distance between input datas
wa1=0
forj=0j<n2j+=2 //number of butterfies perstage
wb1=wa1+ie
wa2=wa1+wa1
wb2=wb1+wb1 //since heremost of the folow-
ering two instructions are parallel
wa3=wa2+wa1
wb3=wb2+wb1
coa1=wwa12+1
cob1=wwb12+1
sia1=wwa12
sib1=wwb12
coa2=wwa22+1
cob2=wwb22+1
sia2=wwa22
sib2=wwb22
coa3=wwa32+1
cob3=wwb32+1
sia3=wwa32
sib3=wwb32
wa1=wb1+ie
foria0=j ib0=j+1 ia0<n ia0+=n1 ib0+=n1
//loop of two butterflies caculation
ia1=ia0+n2
ib1=ib0+n2
ia2=ia1+n2
ib2=ib1+n2
ia3=ia2+n2
ib3=ib2+n2
ra1=x2ia0+x2ia2
rb1=x2ib0+x2ib2
ra1=x2ia0-x2ia2
rb1=x2ib0-x2ib2
ta=x2ia1+x2ia3
tb=x2ib1+x2ib3
x2ia0=ra1+ta // x2ia0
x2ib0=rb1+tb // x2ia0
ra1=ra1-ta
rb1=rb1-tb
sa1=x2ia0+1+x2ia2+1
sb1=x2ib0+1+x2ib2+1
sa2=x2ia0+1-x2ia2+1
sb2=x2ib0+1-x2ib2+1
ta=x2ia1+1+x2ia3+1
tb=x2ib1+1+x2ib3+1
x2ia0+1=sa1+ta
x2ib0+1=sb1+tb
sa1=sa1-ta
sb1=sb1-tb
x2ia2=ra1coa2+sa1sia2>>15
x2ib2=rb1cob2+sb2sib2 >>15
x2ia2+1=sa1coa2-ra1sia2 >>15
x2ib2+1=sb1cob2-rb1sib2 >>15
ta=x2ia1+1-x2ia3+1
ra1=ra2+ta
rb1=rb2+tb
ra2=ra2-ta
rb2=rb2-tb
ta=x2ia1-x2ia3
tb=x2ib1-x2ib3
sa1=sa2-ta
sb1=sb2-tb
sa2=sa2+ta
sb2=sb2+tb
x2ia1=ra1coa1+sa1sia1 >>15
x2ib1=rb1cob1+sb1sib1 >>15
x2ia1+1=sa1coa1-ra1sia1 >>15
x2ib1+1=sb1cob1-rb1sib1 >>15
x2ia3=ra2coa3+sa2sia3 >>15
x2ib3=rb2cob3+sb2sib3 >>15
x2ia3+1=sa2coa3-ra2sia3 >>15
x2ib3+1=sb2cob3-rb2sib3 >>15
ie <<=2
上一篇:TMS320F2812型数字信号处理器与PC的串行通信
下一篇:TMS320C54xx与TLV320AIC24型编解码器的接口设备
- 热门资源推荐
- 热门放大器推荐
 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用 CA3193TX
CA3193TX










 京公网安备 11010802033920号
京公网安备 11010802033920号