摘要:提出了一种基于修正的M距离辐射源识别的新方法。该方法对各特征参数作加权值处理,得到一种新的相似性度量标准,大大提高了识别的准确性。通过计算机仿真,验证了该方法的合理性与有效性。
关键词:M距离 辐射源 识别 数据库
现代战场电磁环境日益密集、复杂,如何快速、准确地对辐射源进行识别已成为电磁斗争领域的一项紧迫任务。一般来说,无源探测系统通过对辐射源辐射信号的处理,得到反映辐射源特征的特征量,由这些特征量根据一定的算法完成对辐射源的识别。这里提到的识别主要是指对辐射源的类型作出判断,若能预先知道辐射源与载体之间的搭配关系,则可进一步实现对辐射源载体的识别[1]。目前,对辐射源识别方法的研究很多,包括人工识别方法、传统的数据处理识别方法、智能化识别方法等[3[4]。人工识别方法是运用人的知识、经验,进行分析和推理,作出判断,不能适应复杂的电磁环境。传统的数据处理识别是利用计算机技术、数字技术进行识别(如数据库查询识别、统计模式识别等)。这类识别方法在待识别雷达信号数据不全或新出现信号时,识别结果难尽人意。智能化识别方法一般比较复杂,难以实现。本文从统计学理论出发,提出了一种基于修正的M距离的辐射源识别法,对辐射源识别问题进行了一些有意义的研究。
1 问题描述
对于现有的数据库或知识库,辐射源个体识别过程就是将侦察所得信号与辐射源数据库中的已知信号相比较,根据某一判决规则,使按该规则对被识别对象进行识别所造成的错误识别率最小或引起的损失最小,从而确定该信号的类属。简单地说就是一个分类问题[2]。其判断的依据主要是看两信号的相似性程度,这涉及到相似性度量标准的问题。为了有效地实现分类识别,需对原始侦察数据进行处理,得到最能反映分类本质的特征。一般把原始数据构成的空间叫测量空间,把分类识别赖以进行的空间叫做特征空间。如果用一组特征参数描述辐射源信号,由这组特征参数所构成的向量即为特征空间中的一个点,此时,点间的距离函数可以作为相似性度量的一个标准。这样,在实际过程中可以依据距离的大小作为模式分类的依据。现在的问题就归结为选择什么样的距离作为相识性度量的标准,从而实现识别、分类。
在辐射源识别中,常采用M距离作为相似性度量的标准。M距离又称为马氏距离,这里的M代表英文Maharanobis。在数理统计中,称常数
 r为a到b的M距离。其中a、b为m维列向量。下面以雷达为例,讨论辐射源泉识别中M距离的应用。
对于雷达这样的多特征对象,采用多元正态分布的概率模型,其概率密度函数定义为:
r为a到b的M距离。其中a、b为m维列向量。下面以雷达为例,讨论辐射源泉识别中M距离的应用。
对于雷达这样的多特征对象,采用多元正态分布的概率模型,其概率密度函数定义为:
 式(2)中,xk=[xk1,xk2,…,xkm]T,xki,i=1,2,…,m是表征第k类雷达信号的一组特征参数,它们对信号的识别起关键作用。例如xk1取载频f,xk2取重频间隔PRI,xk3取脉宽PW,xk4取天线扫描周期Ta等。这里,uk=[uk1,uk2,…,ukm]T为xk的m维均值向量,∑为xk的mxm维协方差矩阵,即∑=E{(xk-uk)(xk-uk)T}。由M距离的定义知道,对于特征空间的两点xk和uk来说,M(xk,uk)表示空间上任意一点到某一考虑该特征分布中心的距离,具体表示为:
式(2)中,xk=[xk1,xk2,…,xkm]T,xki,i=1,2,…,m是表征第k类雷达信号的一组特征参数,它们对信号的识别起关键作用。例如xk1取载频f,xk2取重频间隔PRI,xk3取脉宽PW,xk4取天线扫描周期Ta等。这里,uk=[uk1,uk2,…,ukm]T为xk的m维均值向量,∑为xk的mxm维协方差矩阵,即∑=E{(xk-uk)(xk-uk)T}。由M距离的定义知道,对于特征空间的两点xk和uk来说,M(xk,uk)表示空间上任意一点到某一考虑该特征分布中心的距离,具体表示为:

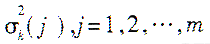 为特征矢量xk的每一个分量的方差,对于具体的侦察设备来说即为参数容差值。
事实上,M距离相对其他距离如欧氏距离而言具有以下优点:首先,M距离是欧几里德空间中非均匀分布的归一化距离,不用考虑各特征参数的量纲;其次,M距离是根据整个空间上的特征分布情况来作为判别依据的,排除了模式样本之间的相关性影响;同时,给出的结果是一个数值,判断标准简单易行,也为更高一级的分析提供了较可靠的依据。但是,M距离的定义中并没有考虑每一个特征参数在识别过程中所起作用即权重的大小。从式(4)可以看出,各特征参数在识别中是作等权值处理的,不符合实际情况。因此,采用修正的M距离作为相似性度量标准。定义新的距离函数如下:
为特征矢量xk的每一个分量的方差,对于具体的侦察设备来说即为参数容差值。
事实上,M距离相对其他距离如欧氏距离而言具有以下优点:首先,M距离是欧几里德空间中非均匀分布的归一化距离,不用考虑各特征参数的量纲;其次,M距离是根据整个空间上的特征分布情况来作为判别依据的,排除了模式样本之间的相关性影响;同时,给出的结果是一个数值,判断标准简单易行,也为更高一级的分析提供了较可靠的依据。但是,M距离的定义中并没有考虑每一个特征参数在识别过程中所起作用即权重的大小。从式(4)可以看出,各特征参数在识别中是作等权值处理的,不符合实际情况。因此,采用修正的M距离作为相似性度量标准。定义新的距离函数如下:
 其中W为权系数矩阵,表示如下:
其中W为权系数矩阵,表示如下:
 且满足
且满足
 则(4)式可表示为:
则(4)式可表示为:
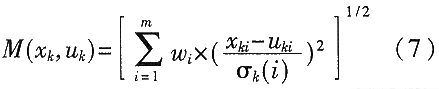 这样,得到了一个新的相似性度量标准。
2 权系数的设置
一般来说,对辐射源目标特征参数之间重要性没有任何先验信息,采用等加权处理方法,如式(4)所示。它是修正的M距离的一个特例。如果是具有一定先验信息的情况,此时权值可根据先验信息确定。但在实际工,作中,先验信息很难得到,此时可以采用如下的熵值分
析法确定权系数。
2.1 熵的定义[2]
熵在信息论中是一个非常重要的概念,它是不确定性的一种度量。设集合X中各事件出现的概率用n维概率矢量p=(p1,p2,…,pn)表示,且满足
这样,得到了一个新的相似性度量标准。
2 权系数的设置
一般来说,对辐射源目标特征参数之间重要性没有任何先验信息,采用等加权处理方法,如式(4)所示。它是修正的M距离的一个特例。如果是具有一定先验信息的情况,此时权值可根据先验信息确定。但在实际工,作中,先验信息很难得到,此时可以采用如下的熵值分
析法确定权系数。
2.1 熵的定义[2]
熵在信息论中是一个非常重要的概念,它是不确定性的一种度量。设集合X中各事件出现的概率用n维概率矢量p=(p1,p2,…,pn)表示,且满足
 则熵定义为:
则熵定义为:
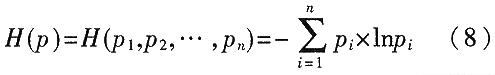 因此,熵H可以看作是n维概率矢量户p=(p1,p2,…,Pn)的函数,称为熵函数。
熵函数H(p)具有以下重要性质:
(1)对称性:概率矢量p=(P1,P2,…,Pn)各分量p1,p2,,…,Pn的次序任意改变时,熵函数H(P)的值不变,即熵值只与集合X总体上的统计特征有关。
(2)非负性:熵函数是一个非负量,即: H(Pl,P2,…,Pn)≥0 (9)
(3)确定性:集合X中只要有一个必然事件,其熵值必为零。
(4)极值性:集合X中各事件以等概率出现时,其熵值为最大,即有:
H(p1,p2,…,pn)≤H(1/n,1/n,…,1/n)=1nn (10)
由熵函数的定义可知,熵值越小,不同类别的分离程度越大。从概率论的角度来看,某一特征的熵值越小则包含的确定性信息越多;反映在分类识别中就是它对识别结果的影响较大,这也意味着设置该特征参数所对应的权值要大一些,以保证识别的精度和准确性。
2.2 熵值分析法设置权重
对于有k类模式的雷达辐射源识别问题,已提取的特片参数共有m个,如式(2)所示。对每一个特征参数Fj;j=1,2,…,m,将其对应的分布区间分为相等的N段,记为rk(j),k=1,2,…,N.注意,这里的分布区间是指k类模式的最大可能的参数分布区间。满足Fj∈rk(j)的样本属于i类的概率为pki(j):
pki(j)=[Nki(j)]/[Nk(j)] (11)
式(11)中,Nk(j)为有Fj∈rk(j)的样本数,Nki(j)为Nk(j)中属于第i类的样本数,于是有:
因此,熵H可以看作是n维概率矢量户p=(p1,p2,…,Pn)的函数,称为熵函数。
熵函数H(p)具有以下重要性质:
(1)对称性:概率矢量p=(P1,P2,…,Pn)各分量p1,p2,,…,Pn的次序任意改变时,熵函数H(P)的值不变,即熵值只与集合X总体上的统计特征有关。
(2)非负性:熵函数是一个非负量,即: H(Pl,P2,…,Pn)≥0 (9)
(3)确定性:集合X中只要有一个必然事件,其熵值必为零。
(4)极值性:集合X中各事件以等概率出现时,其熵值为最大,即有:
H(p1,p2,…,pn)≤H(1/n,1/n,…,1/n)=1nn (10)
由熵函数的定义可知,熵值越小,不同类别的分离程度越大。从概率论的角度来看,某一特征的熵值越小则包含的确定性信息越多;反映在分类识别中就是它对识别结果的影响较大,这也意味着设置该特征参数所对应的权值要大一些,以保证识别的精度和准确性。
2.2 熵值分析法设置权重
对于有k类模式的雷达辐射源识别问题,已提取的特片参数共有m个,如式(2)所示。对每一个特征参数Fj;j=1,2,…,m,将其对应的分布区间分为相等的N段,记为rk(j),k=1,2,…,N.注意,这里的分布区间是指k类模式的最大可能的参数分布区间。满足Fj∈rk(j)的样本属于i类的概率为pki(j):
pki(j)=[Nki(j)]/[Nk(j)] (11)
式(11)中,Nk(j)为有Fj∈rk(j)的样本数,Nki(j)为Nk(j)中属于第i类的样本数,于是有:
 又设pk(j)为一个样本有Fj∈rk(j)的概率,则有:
pk(j)=[Nk(j)]/N0 (13)
式(12)中N0为总的样本数,即:
又设pk(j)为一个样本有Fj∈rk(j)的概率,则有:
pk(j)=[Nk(j)]/N0 (13)
式(12)中N0为总的样本数,即:
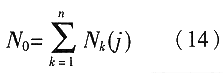 从而定义特片Fj的熵值为:
从而定义特片Fj的熵值为:
 根据熵函数的性质,熵值H(Fi)越小,各类模式在特征Fi上的类间分离性越大,则特征巧对分类的贡献越大,即在识别过程中的权重越大。如果有Fiεrk(j)的所有样本都属于同一类,则有H(Fi)=0。在这种情况下,用这一特征巧就可以实现分类识别。在得到各个特征参数的H(Fi)后,就可以定义相应的归一化权值如下:
根据熵函数的性质,熵值H(Fi)越小,各类模式在特征Fi上的类间分离性越大,则特征巧对分类的贡献越大,即在识别过程中的权重越大。如果有Fiεrk(j)的所有样本都属于同一类,则有H(Fi)=0。在这种情况下,用这一特征巧就可以实现分类识别。在得到各个特征参数的H(Fi)后,就可以定义相应的归一化权值如下:
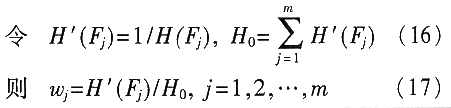 需要注意的是,由于识别过程实际上是将侦察所得信号与辐射源数据库中的已知信号相比较,因而可以采用辐射源数据库中的数据作为熵值分析法的样本。这实际上是充分利用已有的知识数据库中的分类信息确定各特征参数在识别中的权值,以期得到较好的识别效果。
获得权系数后,就可根据相似性度量的大小判断一个特征向量应属于哪一类。若已知待识别信号为。,显然满足M"(s,ui)最小的类ωi与样本有着最大的相似度。即:
M"(s,9ui)=min(M"(s,uj))→sεωi (18)
其中i,j=1,2,…,K,K为类的总数,ωi表示第i类。
需要注意的是,由于识别过程实际上是将侦察所得信号与辐射源数据库中的已知信号相比较,因而可以采用辐射源数据库中的数据作为熵值分析法的样本。这实际上是充分利用已有的知识数据库中的分类信息确定各特征参数在识别中的权值,以期得到较好的识别效果。
获得权系数后,就可根据相似性度量的大小判断一个特征向量应属于哪一类。若已知待识别信号为。,显然满足M"(s,ui)最小的类ωi与样本有着最大的相似度。即:
M"(s,9ui)=min(M"(s,uj))→sεωi (18)
其中i,j=1,2,…,K,K为类的总数,ωi表示第i类。
 3 仿真实验及结果分析
在该实验中以雷达知识数据库中11类雷达辐射源的识别问题作为研究对象。所采用的描述雷达类型的特征参数为:载频、重频间隔、脉宽和天线扫描周期。分段数N=100,经计算得到的各个参数在识别中的权重如表1所示。
表1 各参数在识别中的权重
特征参数名称
载频
重频间隔
脉宽
天线扫描周期
权系数
0.37
0.24
0.2
0.19
下面考虑对某个已知类型的雷达的一批侦察数据进行处理,计算对该目标的识别率,得到的识别率与信噪比的关系曲线如图1所示。
由图1可以看出,为得到较高的识别率,要求信噪比达到5dB左右。进一步的研究表明该方法对未知的新类型雷达目标具有较好的判断能力;同时,分段数N的大小及由此决定的分段区间对权值的确定有一定的影响。当N足够大时,权系数的变化趋向稳定,最终得到的极限值就可以作为确定权系数的依据。
本方法在实际应用中还要注意特征参数的选取和识别权系数的确定,特别是对先验信息的利用,以期得到更佳的识别效果。
3 仿真实验及结果分析
在该实验中以雷达知识数据库中11类雷达辐射源的识别问题作为研究对象。所采用的描述雷达类型的特征参数为:载频、重频间隔、脉宽和天线扫描周期。分段数N=100,经计算得到的各个参数在识别中的权重如表1所示。
表1 各参数在识别中的权重
特征参数名称
载频
重频间隔
脉宽
天线扫描周期
权系数
0.37
0.24
0.2
0.19
下面考虑对某个已知类型的雷达的一批侦察数据进行处理,计算对该目标的识别率,得到的识别率与信噪比的关系曲线如图1所示。
由图1可以看出,为得到较高的识别率,要求信噪比达到5dB左右。进一步的研究表明该方法对未知的新类型雷达目标具有较好的判断能力;同时,分段数N的大小及由此决定的分段区间对权值的确定有一定的影响。当N足够大时,权系数的变化趋向稳定,最终得到的极限值就可以作为确定权系数的依据。
本方法在实际应用中还要注意特征参数的选取和识别权系数的确定,特别是对先验信息的利用,以期得到更佳的识别效果。
引用地址:基于修正的M距离辐射源识别方法及计算机仿真
r为a到b的M距离。其中a、b为m维列向量。下面以雷达为例,讨论辐射源泉识别中M距离的应用。
对于雷达这样的多特征对象,采用多元正态分布的概率模型,其概率密度函数定义为:
式(2)中,xk=[xk1,xk2,…,xkm]T,xki,i=1,2,…,m是表征第k类雷达信号的一组特征参数,它们对信号的识别起关键作用。例如xk1取载频f,xk2取重频间隔PRI,xk3取脉宽PW,xk4取天线扫描周期Ta等。这里,uk=[uk1,uk2,…,ukm]T为xk的m维均值向量,∑为xk的mxm维协方差矩阵,即∑=E{(xk-uk)(xk-uk)T}。由M距离的定义知道,对于特征空间的两点xk和uk来说,M(xk,uk)表示空间上任意一点到某一考虑该特征分布中心的距离,具体表示为:
为特征矢量xk的每一个分量的方差,对于具体的侦察设备来说即为参数容差值。
事实上,M距离相对其他距离如欧氏距离而言具有以下优点:首先,M距离是欧几里德空间中非均匀分布的归一化距离,不用考虑各特征参数的量纲;其次,M距离是根据整个空间上的特征分布情况来作为判别依据的,排除了模式样本之间的相关性影响;同时,给出的结果是一个数值,判断标准简单易行,也为更高一级的分析提供了较可靠的依据。但是,M距离的定义中并没有考虑每一个特征参数在识别过程中所起作用即权重的大小。从式(4)可以看出,各特征参数在识别中是作等权值处理的,不符合实际情况。因此,采用修正的M距离作为相似性度量标准。定义新的距离函数如下:
其中W为权系数矩阵,表示如下:
且满足
则(4)式可表示为:
这样,得到了一个新的相似性度量标准。
2 权系数的设置
一般来说,对辐射源目标特征参数之间重要性没有任何先验信息,采用等加权处理方法,如式(4)所示。它是修正的M距离的一个特例。如果是具有一定先验信息的情况,此时权值可根据先验信息确定。但在实际工,作中,先验信息很难得到,此时可以采用如下的熵值分
析法确定权系数。
2.1 熵的定义[2]
熵在信息论中是一个非常重要的概念,它是不确定性的一种度量。设集合X中各事件出现的概率用n维概率矢量p=(p1,p2,…,pn)表示,且满足
则熵定义为:
因此,熵H可以看作是n维概率矢量户p=(p1,p2,…,Pn)的函数,称为熵函数。
熵函数H(p)具有以下重要性质:
(1)对称性:概率矢量p=(P1,P2,…,Pn)各分量p1,p2,,…,Pn的次序任意改变时,熵函数H(P)的值不变,即熵值只与集合X总体上的统计特征有关。
(2)非负性:熵函数是一个非负量,即: H(Pl,P2,…,Pn)≥0 (9)
(3)确定性:集合X中只要有一个必然事件,其熵值必为零。
(4)极值性:集合X中各事件以等概率出现时,其熵值为最大,即有:
H(p1,p2,…,pn)≤H(1/n,1/n,…,1/n)=1nn (10)
由熵函数的定义可知,熵值越小,不同类别的分离程度越大。从概率论的角度来看,某一特征的熵值越小则包含的确定性信息越多;反映在分类识别中就是它对识别结果的影响较大,这也意味着设置该特征参数所对应的权值要大一些,以保证识别的精度和准确性。
2.2 熵值分析法设置权重
对于有k类模式的雷达辐射源识别问题,已提取的特片参数共有m个,如式(2)所示。对每一个特征参数Fj;j=1,2,…,m,将其对应的分布区间分为相等的N段,记为rk(j),k=1,2,…,N.注意,这里的分布区间是指k类模式的最大可能的参数分布区间。满足Fj∈rk(j)的样本属于i类的概率为pki(j):
pki(j)=[Nki(j)]/[Nk(j)] (11)
式(11)中,Nk(j)为有Fj∈rk(j)的样本数,Nki(j)为Nk(j)中属于第i类的样本数,于是有:
又设pk(j)为一个样本有Fj∈rk(j)的概率,则有:
pk(j)=[Nk(j)]/N0 (13)
式(12)中N0为总的样本数,即:
从而定义特片Fj的熵值为:
根据熵函数的性质,熵值H(Fi)越小,各类模式在特征Fi上的类间分离性越大,则特征巧对分类的贡献越大,即在识别过程中的权重越大。如果有Fiεrk(j)的所有样本都属于同一类,则有H(Fi)=0。在这种情况下,用这一特征巧就可以实现分类识别。在得到各个特征参数的H(Fi)后,就可以定义相应的归一化权值如下:
需要注意的是,由于识别过程实际上是将侦察所得信号与辐射源数据库中的已知信号相比较,因而可以采用辐射源数据库中的数据作为熵值分析法的样本。这实际上是充分利用已有的知识数据库中的分类信息确定各特征参数在识别中的权值,以期得到较好的识别效果。
获得权系数后,就可根据相似性度量的大小判断一个特征向量应属于哪一类。若已知待识别信号为。,显然满足M"(s,ui)最小的类ωi与样本有着最大的相似度。即:
M"(s,9ui)=min(M"(s,uj))→sεωi (18)
其中i,j=1,2,…,K,K为类的总数,ωi表示第i类。
3 仿真实验及结果分析
在该实验中以雷达知识数据库中11类雷达辐射源的识别问题作为研究对象。所采用的描述雷达类型的特征参数为:载频、重频间隔、脉宽和天线扫描周期。分段数N=100,经计算得到的各个参数在识别中的权重如表1所示。
表1 各参数在识别中的权重
特征参数名称
载频
重频间隔
脉宽
天线扫描周期
权系数
0.37
0.24
0.2
0.19
下面考虑对某个已知类型的雷达的一批侦察数据进行处理,计算对该目标的识别率,得到的识别率与信噪比的关系曲线如图1所示。
由图1可以看出,为得到较高的识别率,要求信噪比达到5dB左右。进一步的研究表明该方法对未知的新类型雷达目标具有较好的判断能力;同时,分段数N的大小及由此决定的分段区间对权值的确定有一定的影响。当N足够大时,权系数的变化趋向稳定,最终得到的极限值就可以作为确定权系数的依据。
本方法在实际应用中还要注意特征参数的选取和识别权系数的确定,特别是对先验信息的利用,以期得到更佳的识别效果。
上一篇:一种新型膜片钳放大器系统的设计
下一篇:用智能马桶实现体温测量与亚健康预测
 嵌入式网络那些事:LwIP协议深度剖析与实战演练
嵌入式网络那些事:LwIP协议深度剖析与实战演练 LTC2053HMS8#TRPBF
LTC2053HMS8#TRPBF










 京公网安备 11010802033920号
京公网安备 11010802033920号