使用STVD建立完汇编工程项目之后(具本建立方法可以看我的另一篇博文http://blog.csdn.net/u010093140/article/details/49983397),可以看到这个目录结构(以STM8S105C6芯片为例) 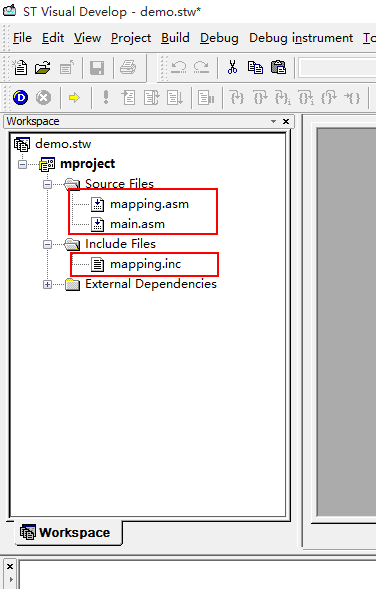
其中.asm文件是汇编代码的源文件,.inc文件是包含文件,类似于C语言当在的.c文件和.h文件。接下来让我们来分析一下这三个文件。(分析汇编代码最好也要对STM8单片机的启动流程有所了解,可以看我的另一篇博文http://blog.csdn.net/u010093140/article/details/49982879)
首先是看mapping.inc文件:
;------------------------------------------------------
; SEGMENT MAPPING FILE AUTOMATICALLY GENERATED BY STVD
; SHOULD NOT BE MANUALLY MODIFIED.
; CHANGES WILL BE LOST WHEN FILE IS REGENERATED.
;------------------------------------------------------
#define RAM0 1
#define ram0_segment_start 0
#define ram0_segment_end FF
#define RAM1 1
#define ram1_segment_start 100
#define ram1_segment_end 5FF
#define stack_segment_start 600
#define stack_segment_end 7FF
这一段代码应该不难看懂,就是定义了一些常量。需要注意的是,分号”;”是汇编代码中用于写注释的符号。所以分号后面跟的是注释。
接下来就是看一下mapping.asm文件
stm8/
;------------------------------------------------------
; SEGMENT MAPPING FILE AUTOMATICALLY GENERATED BY STVD
; SHOULD NOT BE MANUALLY MODIFIED.
; CHANGES WILL BE LOST WHEN FILE IS REGENERATED.
;------------------------------------------------------
#include "mapping.inc"
BYTES ; The following addresses are 8 bits long
segment byte at ram0_segment_start-ram0_segment_end 'ram0'
WORDS ; The following addresses are 16 bits long
segment byte at ram1_segment_start-ram1_segment_end 'ram1'
WORDS ; The following addresses are 16 bits long
segment byte at stack_segment_start-stack_segment_end 'stack'
WORDS ; The following addresses are 16 bits long
segment byte at 4000-43FF 'eeprom'
WORDS ; The following addresses are 16 bits long
segment byte at 8080-FFFF 'rom'
WORDS ; The following addresses are 16 bits long
segment byte at 8000-807F 'vectit'
END
上面的代码第一行以stm8/开头,很多人不知道为什么要这样子。其实是因为我们所用的汇编连接器Assembler Linker不仅支持STM8汇编代码而且还支持ST公司的另一款芯片ST7的汇编代码,如果你用的是ST7芯片的话,就要以st7/开头了。结论就是使用stm8/开头是为了表明代码的目标芯片是stm8芯片。
分号后面的注释不算入代码里面,剩下来的代码就定义了芯片上的内存段,比如说segment byte at ram0_segment_start-ram0_segment_end ‘ram0’的意思就是,从ram0_segment_start到ram0_segment_end的这一段内存起个名字叫做“ram0”,segment byte at ram1_segment_start-ram1_segment_end ‘ram1’的意思就是,从ram1_segment_start到ram1_segment_end的这一段内存起个名字叫做“ram1”,其它的也是一样的道理。那么,你也会注意到,每一句这样的代码之前都有一句”Bytes”或者”Words”,这是什么意思呢?按代码注释里的意思就是,Bytes代表内存段里内存的地址是8位的,而Words代表内存段里内存的地址是16位的。通过查Assembler Linker PDF,发现Bytes和Words用于指定跟在它下面的的标号的默认长度,什么意思?可以看以下的例子:
Bytes
label1
;下面这条语句是编译通过的。因为A是8位的,label1也是8位的。
LD A,#label1
Words
label2
;下面这条语句是编译不通过的。因为A是8位的,而label2是16位的,通过赋值给A。
LD A,#label2
Words
label3.b
;而下面这条语句是可以编译通过的,因为我显式地指定了label3为byte的长度(.b),是8位的。
我们再看回到mapping.asm那个文件,mapping文件里所有的指令都是伪指令,并不产生实际的可执行代码,那么使用了bytes,words是什么作用呢?从上面bytes和words的作用来看,我个人认为它们在mapping.asm里不起作用,只起到说明的作用,相当于注释。当然如有错误,欢迎大家指出^_^。所以mapping的作用就是给芯片的存储空间划分区域并命名。我们后面我们写的代码可以通过这个名字,指定存到该名字所代表的存储区域下。比如说ram0区,ram1区,rom区等。
接下来再来看main.asm,这个代码有一些长了,先贴出来吧。
stm8/
#include "mapping.inc"
segment 'rom'
main.l
; initialize SP
ldw X,#stack_end
ldw SP,X
#ifdef RAM0
; clear RAM0
ram0_start.b EQU $ram0_segment_start
ram0_end.b EQU $ram0_segment_end
ldw X,#ram0_start
clear_ram0.l
clr (X)
incw X
cpw X,#ram0_end
jrule clear_ram0
#endif
#ifdef RAM1
; clear RAM1
ram1_start.w EQU $ram1_segment_start
ram1_end.w EQU $ram1_segment_end
ldw X,#ram1_start
clear_ram1.l
clr (X)
incw X
cpw X,#ram1_end
jrule clear_ram1
#endif
; clear stack
stack_start.w EQU $stack_segment_start
stack_end.w EQU $stack_segment_end
ldw X,#stack_start
clear_stack.l
clr (X)
incw X
cpw X,#stack_end
jrule clear_stack
infinite_loop.l
jra infinite_loop
interrupt NonHandledInterrupt
NonHandledInterrupt.l
iret
segment 'vectit'
dc.l {$82000000+main} ; reset
dc.l {$82000000+NonHandledInterrupt} ; trap
dc.l {$82000000+NonHandledInterrupt} ; irq0
dc.l {$82000000+NonHandledInterrupt} ; irq1
dc.l {$82000000+NonHandledInterrupt} ; irq2
dc.l {$82000000+NonHandledInterrupt} ; irq3
dc.l {$82000000+NonHandledInterrupt} ; irq4
dc.l {$82000000+NonHandledInterrupt} ; irq5
dc.l {$82000000+NonHandledInterrupt} ; irq6
dc.l {$82000000+NonHandledInterrupt} ; irq7
dc.l {$82000000+NonHandledInterrupt} ; irq8
dc.l {$82000000+NonHandledInterrupt} ; irq9
dc.l {$82000000+NonHandledInterrupt} ; irq10
dc.l {$82000000+NonHandledInterrupt} ; irq11
dc.l {$82000000+NonHandledInterrupt} ; irq12
dc.l {$82000000+NonHandledInterrupt} ; irq13
dc.l {$82000000+NonHandledInterrupt} ; irq14
dc.l {$82000000+NonHandledInterrupt} ; irq15
dc.l {$82000000+NonHandledInterrupt} ; irq16
dc.l {$82000000+NonHandledInterrupt} ; irq17
dc.l {$82000000+NonHandledInterrupt} ; irq18
dc.l {$82000000+NonHandledInterrupt} ; irq19
dc.l {$82000000+NonHandledInterrupt} ; irq20
dc.l {$82000000+NonHandledInterrupt} ; irq21
dc.l {$82000000+NonHandledInterrupt} ; irq22
dc.l {$82000000+NonHandledInterrupt} ; irq23
dc.l {$82000000+NonHandledInterrupt} ; irq24
dc.l {$82000000+NonHandledInterrupt} ; irq25
dc.l {$82000000+NonHandledInterrupt} ; irq26
dc.l {$82000000+NonHandledInterrupt} ; irq27
dc.l {$82000000+NonHandledInterrupt} ; irq28
dc.l {$82000000+NonHandledInterrupt} ; irq29
end
上面的代码看得明白吗?哈哈。首先先给一个内存图,有用到内存的地方可以回来看这个图比较直观。

下面采用一行一行注释的方式给大家讲解(发表完之后发现注释跑到屏幕外面了,把代码栏下面的横条向右拉就可以看到了。)。
;就如之前所说的,stm8指明以下的代码是用于stm8芯片的,而不是st7芯片。
stm8/
;以下代码是把mapping.inc文件包含进来的意思,这样就可以直接用mapping.inc里面定义的常量了。
#include "mapping.inc"
;以下代码是指明往后的代码都是放在rom存储区域的意思,就如mapping.asm里所表明的,rom的地址范围是8080-FFFF。
segment 'rom'
;main.l是一个标号,写在最左边的一行,标号不产生实际的指令。标号的作用时给一个地址进行命名,然后其它指令就可以使用这个名字来使用这个地址了。比如说下面的main.l的地址就跟下面的ldw X,#stack_end所在的地址相等的。而.l的意思是该地址是3个字节24位的。
main.l
; initialize SP
;下面这一句的意思是把stack_end的值加载到X寄存器,#是立即数的意思。ldw的w是word的意思,表明是16位是加载指令。也有8位的加载指令,为ld.
ldw X,#stack_end
;下面这一句的意思是把寄存器X的值赋给SP寄存器的意思,SP是栈指针,上下两句的作用是让SP指向栈顶。(STM8的栈结构是自顶向下的,栈顶的值就是stack_end,栈中地址值最大的那个数)。
ldw SP,X
;伪指令,如果定义了RAM0就编译其后的代码,显然这个判断是为真的,因为在mapping.inc中已经定义了RAM0和RAM1.
#ifdef RAM0
; clear RAM0
;伪指令,定义标号ram0_start.b的值为ram0_segment_start的值,$是16进制数的意思,ram0_end.b同理。这种直接赋值的方式跟前面的main.l标号有所不同,下面这种是赋绝对地址,而main.l是赋相对地址。
ram0_start.b EQU $ram0_segment_start
ram0_end.b EQU $ram0_segment_end
;加载ram0_start的值到X
ldw X,#ram0_start
;定义标号clear_ram0.l
clear_ram0.l
;clr是清除的意思,()是间接寻址的意思,clr(X)就是以X的值为地址,清除该地址上的值的意思。
clr (X)
;X加1,incw有个w是因为X是16位的。
incw X
;cpw是compare的意思,比较X和ram0_end的值,w的意思跟上面讲的意思一样。
cpw X,#ram0_end
;jrule(jump relative unsigned less than)这个意思明白了吧?就是如果小于就跳转到clear_ram0标号地址的意思。
jrule clear_ram0
;跟前面的#ifdef RAM0相对应。
#endif
;这个面RAM1的操作跟以上对RAM0的操作一样。整一段代码的作用就是清零存储区的作用。
#ifdef RAM1
; clear RAM1
ram1_start.w EQU $ram1_segment_start
ram1_end.w EQU $ram1_segment_end
ldw X,#ram1_start
clear_ram1.l
clr (X)
incw X
cpw X,#ram1_end
jrule clear_ram1
#endif
;下面初始化栈区的操作也是跟前面对RAM0的操作一样的。
; clear stack
stack_start.w EQU $stack_segment_start
stack_end.w EQU $stack_segment_end
ldw X,#stack_start
clear_stack.l
clr (X)
incw X
cpw X,#stack_end
jrule clear_stack
;下面定义了infinite_loop.l标号。
infinite_loop.l
;jra是相对跳转的意思,跳转到上面那个标号。所以这是一个无限循环,代码到这里就是不断地执行jra infinite_loop这条语句,相当于C语言中的while(1);
jra infinite_loop
;interrupt是伪指令,把NoHandleInterrupt说明成是用于中断的标号。
interrupt NonHandledInterrupt
;定义NonHandledInterrupt.l标号
NonHandledInterrupt.l
;iret是中断返回的意思。而ret是函数返回的意思。
iret
;segment 'vectic'指令其下面的代码是放在vectit存储区的,即8000-807F所在的区域。
segment 'vectit'
;dc.l的意思是申请一段四个字节的空间,后面加的数字就是赋予这个空间的值。什么?前面的l的用法都是3个字节的,这里dc.l里的l就成4个字节了?没错,就是这样子的,有点乱,这也是有点费解的地方,我也不明白为啥不改另一个说法。{}的用法是在编译时运算里面的语句,而不是在代码里演算。比如说{1+1}会在编译后变成2.
;下面的所有dc.l其实就是定义了一个中断向量表,分别对应于不同的中断,比如第一个就是复位中断,芯片复位后会在这里找到main标号,然后程序跳转到main里去。当然如果你对main不爽,也可以改成其它的,比如说example.但是这个改了之后,最前面的main.l标号也要相应的改成example.l.就相当于这个程序里面“没有”main函数了。是不是很神奇呢?呃。下面有注释了trap,irq0,irq2等这些,其实就是对应了不同的中断,比如说I2C的中断就对应了其中的irq19,所以当你写好I2C的中断服务程序后,需要把它的标号填写到irq19那一句中,可以参考dc.l{$82000000+main}这句,如果你把I2C中断服务程序的标号定义I2C_Interrupt.l则irq19中那一句要改成dc.l{$82000000+I2C_Interrupt}.最后一个问题,中断后单片机会跳到中断标号里去执行这点没问题了,那下面$82000000中的82是什么意思呢?(现在想找之前看到的资料已经找不到了。。。。不过我还记得那个意思)82是STM8指令集中的一个操作码(汇编指令是由操作码和操作数组成的),我想用在中断这里的意思就是表面这个地址标号是中断服务程序地址标号的意思吧,芯片可以识别82这个操作码,从而区别对待。
dc.l{$82000000+main} ; reset
dc.l {$82000000+NonHandledInterrupt} ; trap
dc.l {$82000000+NonHandledInterrupt} ; irq0
dc.l {$82000000+NonHandledInterrupt} ; irq1
dc.l {$82000000+NonHandledInterrupt} ; irq2
dc.l {$82000000+NonHandledInterrupt} ; irq3
dc.l {$82000000+NonHandledInterrupt} ; irq4
dc.l {$82000000+NonHandledInterrupt} ; irq5
dc.l {$82000000+NonHandledInterrupt} ; irq6
dc.l {$82000000+NonHandledInterrupt} ; irq7
dc.l {$82000000+NonHandledInterrupt} ; irq8
dc.l {$82000000+NonHandledInterrupt} ; irq9
dc.l {$82000000+NonHandledInterrupt} ; irq10
dc.l {$82000000+NonHandledInterrupt} ; irq11
dc.l {$82000000+NonHandledInterrupt} ; irq12
dc.l {$82000000+NonHandledInterrupt} ; irq13
dc.l {$82000000+NonHandledInterrupt} ; irq14
dc.l {$82000000+NonHandledInterrupt} ; irq15
dc.l {$82000000+NonHandledInterrupt} ; irq16
dc.l {$82000000+NonHandledInterrupt} ; irq17
dc.l {$82000000+NonHandledInterrupt} ; irq18
dc.l {$82000000+NonHandledInterrupt} ; irq19
dc.l {$82000000+NonHandledInterrupt} ; irq20
dc.l {$82000000+NonHandledInterrupt} ; irq21
dc.l {$82000000+NonHandledInterrupt} ; irq22
dc.l {$82000000+NonHandledInterrupt} ; irq23
dc.l {$82000000+NonHandledInterrupt} ; irq24
dc.l {$82000000+NonHandledInterrupt} ; irq25
dc.l {$82000000+NonHandledInterrupt} ; irq26
dc.l {$82000000+NonHandledInterrupt} ; irq27
dc.l {$82000000+NonHandledInterrupt} ; irq28
dc.l {$82000000+NonHandledInterrupt} ; irq29
end
好了,本文就讲完了,其实想尽量讲得明白一些,但发现涉及到的方面太多了,展开来讲的话,篇幅会很大,也会显得很啰嗦了。比如说汇编指令我就没有介绍过,汇编连接器所支持的伪指令有哪些我也没有讲到,想讲,但可能花的篇幅比本文还长。。后续有时间,觉得有必要再进行补充吧。最近也比较忙。当然最重要的一点是,没人看。没人看。没人看啊。
上一篇:学习STM8 关于数据类型的定义心得
下一篇:stm8单片机内部存储EEPROM字节读写实例解析
推荐阅读最新更新时间:2024-03-16 16:13

 独辟蹊径品内核: Linux 内核源代码导读
独辟蹊径品内核: Linux 内核源代码导读 控制系统计算机辅助设计 — MATLAB语言与应用
控制系统计算机辅助设计 — MATLAB语言与应用设计资源 培训 开发板 精华推荐
- 【下载】LAT1439 关于STM32H745的MC SDK电机控制工程问题的解决办法
- 【下载】LAT1444 ADC采样中的阻抗匹配计算方法
- 【下载】LAT1446 TrustZone应用中串口通信的DMA传输失败问题
- 【下载】LAT1450 不断电情况下修改RDP选项并生效的解决方案
- 【下载】LAT1455 分辨OEMiROT的Bash与BAT脚本
- 【下载】LAT1457 Keil工程使用NEAI库的异常问题












 京公网安备 11010802033920号
京公网安备 11010802033920号