


实力原创:徒手编写了一个STM8的反汇编工具
☼
原创
最近打算玩一下STM8, 只为了消化一下我的库存,因为我曾经买过几个型号的STM8单片机,但是一直没用来DIY啥。我对STM8熟悉程度远不如STM32, 后者是流行广泛的ARM核,STM8却是ST独家的架构。
STM8 CPU是在ST7基础上增强,有人说是从6502演变来的,我看倒也不像。学习了一下历史,Motorola的6800演变出来的6805/6811/6809三个分支,以及6502这个与6800有渊源的CPU,从寄存器和指令集上看STM8是和它们有相似之处的,不过差异的地方也很大。作为一个8位MCU,STM8的寻址范围居然达到16M byte(我不信ST会给8位机配上1M以上的ROM或RAM),寻址模式就很多了,间接内存访问比x86都复杂,看惯了RISC的CPU更不能忍。好吧,虽然指令集复杂,STM8的执行速度还快,反正不会纯用汇编来开发。
ST并没有提供STM8的C编译器(汇编器是有的),需要用第三方的。Cosmic C编译器有免费License的版本可以用,这也是ST推荐的,我就装了一个来试。ST官方支持的还有Raisonance的编译器,此外IAR也有STM8的开发环境。
试写了个C程序测试,可以用STVP连接ST-Link下载程序,但我觉得还需要个能反汇编看编译结果的东西。Cosmic工具链里面没有反汇编程序,ST的汇编工具里也没有,STVD既然能跟踪调试应该有,但我没能把它用起来。
干脆自己写一个STM8反汇编工具吧,也练下手怎么写。
先研究下STM8的指令集,这是一种典型变长指令集,除了前缀字节,操作码就在一个字节里面。于是我照着手册统计了一张表出来: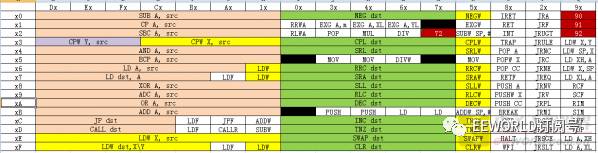
一个字节能表示的范围除了 0x90, 0x91, 0x92, 0x72 用来做指令前缀,其它几乎都用来作操作码了。当然许多指令都有多种寻址模式的(比如加法是谁和谁相加,需要指定),因此用了不止一个操作码。算上寻址模式,256种指令都不够用的,所以STM8靠前面增加前缀字节来扩展。从手册里面截一个例子如下(这是XOR指令的多种编码):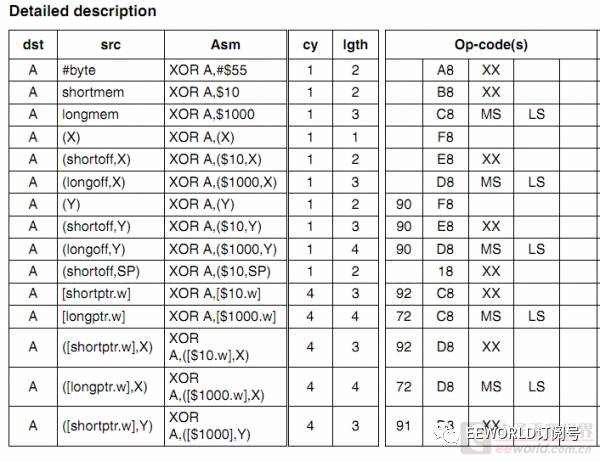
编写反汇编程序就是写一个根据字节数据流的查表过程。上面我做的那个表只是划分了指令的分布,涉及到寻址模式的细节还是得一边写一边查手册。从表上看,操作码的高半字节大概可以把指令划分为几类,再用低半字节去细分指令,于是我的程序解码第一步就是一个 switch-case 结构来划分任务:
[C] 纯文本查看 复制代码
?
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | int decode_instr(unsigned char opcode){ switch(opcode>>4) { case 1: case 0x0A: case 0x0B: case 0x0C: case 0x0D: case 0x0E: case 0x0F: return decode_group1(opcode); case 0: case 3: case 4: case 6: case 7: return decode_group2(opcode); case 5: if(Prefix==0x72) return |






 京公网安备 11010802033920号
京公网安备 11010802033920号