摘要:家电语音控制系统在复杂的背景环境下,由于识别率显著下降而导致关键词检出率偏低。介绍了利用孤立词、连接词以及连续语音识别引擎构造的多识别引擎的识别器,该识别器允许用户自由选择语音输入方式,扩大了关键词的检出范围,从而达到提高关键词检出率的目的。同时给出了家电语音控制系统的整体结构,分析了影响系统性能的关键因素,并且给出了相应的解决方案。
关键词:语音识别 家电语音控制 语音确认关键词检出
近年来,随着语音识别与确认技术的逐渐成熟,基于语音识别技术的对话控制系统受到了越来越多的关注。现有的语音技术虽然在实验室环境中取得取得了较好的识别效果,但是一旦由于环境或者说话人的客观原因使得语音信号变差时,就会导致系统检出率急剧下降,从而使得语音控制系统的性能变差甚至不能正常工作。
针对残疾人行动不便的问题,在日本富士通公司的资助下开发了一套残疾人利用语音进行家电控制的系统。本系统的用户主要是康复中心的特殊用户,由于身体长期瘫痪或者其它原因,他们不仅行动不便,而且语言交流能力也有很大程度的下降,尤其是发音不够清晰准确,仅仅用传统的语音识别器很难满足控制系统实际应用的需要。因此,提出了综合利用孤立词识别器、连接词识别以及连续语音识别器构建一个基于多识别引擎的识别器的方法,使得关键词被正确检出的可能性大大增加,在允许用户自由使用孤立或者连续语音交流的同时,还最大限度地利用不同识别引擎的优点,改善了家电语音控制系统的性能。
另外,还分析了语音控制系统中确认、模型自适应以及对话控制策略等关键技术,并且给出了相应的解决方案,从而给出家电语音控制系统的完整结构,在电梯、轮椅、电视等设备的实际控制中取得了良好的效果。
1 家电语音控制系统的结构
家电语音控制系统包括软件设计和硬件设计两部分。本文主要讨论软件设计部分,其中包括:语音识别模块、语音确认模块、对话控制及硬件指令传输模块以及模型自适应模块。整个系统的流程是:首先,用户的语音被送入语音识别模块进行Viterbi解码识别,得到相应的候选关键词;然后,将候选关键词送入语音确认模块进行确认,从中检出可能的关键词,并给出相应的确认分值;再后,根据检出的关键词及其对应的确认分值产生相应的对话或者控制命令对硬件进行控制,同时利用已经确认的语音对识别中的语音模型进行更新。图1给出了家电语音控制系统的结构图。
 2 基于多识别引擎的识别器设计
2.1 传统识别引擎简介
根据待识别语音属于单一用户还是公众进行分类,可以将其分为特定人识别以及非特定人识别。由于设计目标是针对特定用户的,因此采用特定人识别器。如果根据输入语音特点以及建模方法进行分类,当前的识别引擎主要分为孤立词识别、连续语音识别以及连接词识别等引擎。下面分别介绍几种不同的识别引擎以及各自的优缺点。
2.1.1 孤立词识别引擎
由于孤立词识别引擎的输入是孤立的词汇,因此其识别范围小,建模精确,识别率高,非特定人的孤立词识别引擎的识别率可达95%左右,特定人的识别率甚至可达99%以上。但是孤立词识别引擎要求用户的输入必须是一个个独立的单词,显然对于连续的语音流无法处理。即使是独立的单词,如果由于用户的习惯或者生理原因,在语音中含有一些语气词或者其它高能量的突发噪声,将严重影响系统的识别率。
2.1.2 连续语音识别引擎
连续语音识别引擎是以音节或者音素为单位进行建模的,很好地解决了孤立词识别中对输入语音的限制,而且通过对常见的语气词以及噪声的建模,也能够解决由其引起的识别率下降的问题。但是连续语音的识别率很低,即使在实验室环境下,其识别率最高也只能达90%左右。显然连续语音识别引擎难以单独用于家电语音控制系统。
2.1.3 连接词识别引擎
连接词识别引擎介于孤立词识别引擎和连续语音识别引擎之间。它以孤立词为模型,通过对孤立词的拼接实现对连续语音流的识别。对于小型的语音识别系统来说,由于其词表较小,因此建模方便,而且建模精度高,对关键词的识别率接近于孤立词识别引擎,很好地解决了孤立词识别引擎无法解决的连续语音流问题。但是当输入语音流包含过多的音节时,其识别率不可避免地会下降很多。
用户在选择识别引擎的时候,主要需要考虑的因素包括:识别率、实时响应速度、鲁棒性、输入语音限制、使用舒适性等。
2.2 基于多识别引擎的识别器设计
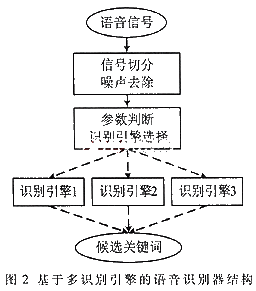
通过对识别引擎的分析以及对传统识别引擎的介绍可以看到,无论单独选择哪种识别引擎,都不能够完善地满足实用的语音控制系统的要求,因此设计了一种多识别引擎的并行识别器,能够获得传统识别器无法兼得的优点。图2给出了基于多识别引擎的识别器结构图。
2.2.1 基于多识别引擎的识别器工作原理
图2中,识别引擎1为孤立词识别引擎;识别引擎2为连接词识别引擎;识别引擎3为连续语音识别引擎。识别器具体的工作流程如下:
(1)对输入语音进行预处理,包括语音信号的切分以及噪声去除等。语音信号的切分采用的是基于能量窗计算的切分算法,使得语音信号的端点更准确。
(2)根据输入语音的物理长度以及其它物理特征预判输入语音为孤立词输入还是连续语音输入。如果语音信号较短,则采用识别引擎1、2进行识别;如果信号较长,则采用识别引擎2、3进行识别;如果不能确定是孤立语音还是连续语音,则同时采用三个识别引擎进行识别。
(3)对于不同的识别引擎,将得到的识别结果作为候选关键词(如果识别结果不同则为多候选)送入确认模块进行确认。
2.2.2 基于多识别引擎的识别器性能分析
由于基于多识别引擎的识别器至少同时启动了两个或者三个识别引擎,因此系统的响应时间不可避免地要受到影响。所以在语音建模时,采用参数共享的方法,从而降低了计算法复杂度,提高了系统响应速度。同时注意到,对于孤立语音来说,由于识别引擎1、2的识别速度很快,因此完全可以满足实时响应的要求;对于连续语音来说,其识别时间主要耗费在识别引擎3上,这是不可避免的,系统引入的附加耗时很小,因此基本上不会因此而降低系统的响应速度。
而多识别引擎的识别器的建立,使得无论连续语音输入还是孤立语音输入,都能采用合适的识别引擎进行识别,从而在允许用户自由交流的基础上,保证了系统的识别率得到大幅度的提高。尤其是用户在采用连续语音输入系统不能正确识别时,可以降低要求,
2 基于多识别引擎的识别器设计
2.1 传统识别引擎简介
根据待识别语音属于单一用户还是公众进行分类,可以将其分为特定人识别以及非特定人识别。由于设计目标是针对特定用户的,因此采用特定人识别器。如果根据输入语音特点以及建模方法进行分类,当前的识别引擎主要分为孤立词识别、连续语音识别以及连接词识别等引擎。下面分别介绍几种不同的识别引擎以及各自的优缺点。
2.1.1 孤立词识别引擎
由于孤立词识别引擎的输入是孤立的词汇,因此其识别范围小,建模精确,识别率高,非特定人的孤立词识别引擎的识别率可达95%左右,特定人的识别率甚至可达99%以上。但是孤立词识别引擎要求用户的输入必须是一个个独立的单词,显然对于连续的语音流无法处理。即使是独立的单词,如果由于用户的习惯或者生理原因,在语音中含有一些语气词或者其它高能量的突发噪声,将严重影响系统的识别率。
2.1.2 连续语音识别引擎
连续语音识别引擎是以音节或者音素为单位进行建模的,很好地解决了孤立词识别中对输入语音的限制,而且通过对常见的语气词以及噪声的建模,也能够解决由其引起的识别率下降的问题。但是连续语音的识别率很低,即使在实验室环境下,其识别率最高也只能达90%左右。显然连续语音识别引擎难以单独用于家电语音控制系统。
2.1.3 连接词识别引擎
连接词识别引擎介于孤立词识别引擎和连续语音识别引擎之间。它以孤立词为模型,通过对孤立词的拼接实现对连续语音流的识别。对于小型的语音识别系统来说,由于其词表较小,因此建模方便,而且建模精度高,对关键词的识别率接近于孤立词识别引擎,很好地解决了孤立词识别引擎无法解决的连续语音流问题。但是当输入语音流包含过多的音节时,其识别率不可避免地会下降很多。
用户在选择识别引擎的时候,主要需要考虑的因素包括:识别率、实时响应速度、鲁棒性、输入语音限制、使用舒适性等。
2.2 基于多识别引擎的识别器设计
通过对识别引擎的分析以及对传统识别引擎的介绍可以看到,无论单独选择哪种识别引擎,都不能够完善地满足实用的语音控制系统的要求,因此设计了一种多识别引擎的并行识别器,能够获得传统识别器无法兼得的优点。图2给出了基于多识别引擎的识别器结构图。
2.2.1 基于多识别引擎的识别器工作原理
图2中,识别引擎1为孤立词识别引擎;识别引擎2为连接词识别引擎;识别引擎3为连续语音识别引擎。识别器具体的工作流程如下:
(1)对输入语音进行预处理,包括语音信号的切分以及噪声去除等。语音信号的切分采用的是基于能量窗计算的切分算法,使得语音信号的端点更准确。
(2)根据输入语音的物理长度以及其它物理特征预判输入语音为孤立词输入还是连续语音输入。如果语音信号较短,则采用识别引擎1、2进行识别;如果信号较长,则采用识别引擎2、3进行识别;如果不能确定是孤立语音还是连续语音,则同时采用三个识别引擎进行识别。
(3)对于不同的识别引擎,将得到的识别结果作为候选关键词(如果识别结果不同则为多候选)送入确认模块进行确认。
2.2.2 基于多识别引擎的识别器性能分析
由于基于多识别引擎的识别器至少同时启动了两个或者三个识别引擎,因此系统的响应时间不可避免地要受到影响。所以在语音建模时,采用参数共享的方法,从而降低了计算法复杂度,提高了系统响应速度。同时注意到,对于孤立语音来说,由于识别引擎1、2的识别速度很快,因此完全可以满足实时响应的要求;对于连续语音来说,其识别时间主要耗费在识别引擎3上,这是不可避免的,系统引入的附加耗时很小,因此基本上不会因此而降低系统的响应速度。
而多识别引擎的识别器的建立,使得无论连续语音输入还是孤立语音输入,都能采用合适的识别引擎进行识别,从而在允许用户自由交流的基础上,保证了系统的识别率得到大幅度的提高。尤其是用户在采用连续语音输入系统不能正确识别时,可以降低要求,
 视其为孤立语音输入,这样一方面可以正确控制家电正常运行,另一方面通过自适应,不同识别引擎的模型都得到了更为精确的刻画,逐渐提高了系统识别率,从而使得连续语音识别率也得到了提高。另外,在各种情况下都采用了连接识别引擎,主要是考虑到残疾用户的语音中经常附带一些常见的突发噪声以及语气词,因此通过对此进行独立建模,能够去除语音信号首尾的噪声和语气词的影响,进一步提高识别器的鲁棒性。
3 其它关键技术分析
在家电语音控制系统中,除了识别器的性能严重影响系统的运行性能以外,关键词确认、对话控制策略以及识别器自适应也是至关重要的:关键词输入的结果给出候选关键词的置信度,因此直接影响了后续的对话控制模块可能采取的动作——当置信度高时,接受该关键词将其作为真正的关键词并且发出相应的控制指令;当置信度较低时,拒绝该候选词;当置信度处于中间水平时,产生相应的对话语音与用户进一步进行交互,对可能要发生的动作进行确认。在实际应用中,自适应技术保证了通过长期的用户和系统之间的交互,对识别器的模型进行修正,从而提高用户的语音识别率。
基于多识别引擎的识别器给关键词确认模块提供了更多的候选关键词,因此扩大了关键词的检出范围,为进一步提高检出率提供了条件;但是另一方面,更多的候选关键词意味着错误的候选关键词被接受的可能性也大大增加,系统的误警率也会随之上升。因此对于关键词确认性能的依赖也会更大,所以提取出多种有效的确认特片,利用神经元网络进行最终的置位度评价。这些确认特片包括:音素匹配得分特征、音素数匹配得分特征、似然得分特征、似然排位得分特片以及模型距离差累积得分特征。详细的确认过程见参考文献。
在对话控制模块中,由于不同的电路对应着不同的关键词,因此通过记录当前对话所处的处理(应用某一个电路的状态或者空闲状态),给识别器提供相应于该状态的关键词表,大大缩小了关键词表中关键词的总数,降低了关键词之间的混淆度,从而进一步提高了识别器的识别率。此外,对关键词重要性进行了分级,不同的关键词拥有不同的级别,对于重要的关键词来说,只有在其置信度很高的情况下才会将其直接发送给硬件控制模块去执行控制,否则要通过语音交互和用户确认的方法来确定是否执行该命令。
针对不同的识别器,采用不同的自适应策略:由于噪声模型和系统当前所处状态直接相关,因此随时准备利用系统空闲状态时采集的噪音段对噪声模型进行更新;对于孤立词和连接词识别引擎所采用的声学模型来说,利用经过确认的语音段对相应的模型者重新;对连续语音来说,由于只有对关键词的置信度评价,很难保证非关键词语音识别的正确性,因此只对关键词模型进行更新,在用户空闲时,引导用户利用给定的语音输入对连续语音所采用的模型进行更新,以达到模型自适应的效果。
4 实验及结果分析
本文所采用的试验平台是用于连续语音电梯控制声控仿真系统的关键词检出系统。整个系统由四个部分组成:语音识别模块、语音确认模块、自适应模块以及对话管理模块。语音识别模块采用的是无跨越从左向右的CHMM模型,特征向量为39维的MFCC特征——12维的MEL特征系数以及一阶和二阶差分;能量及其一阶和二阶差分。确认模块采用的是基于多特征联合得分的确认算法。
论文中所采用的语音数据库包括三种类型:孤立语音——对应系统中采用的关键词命令;连续语音——每段语音中包含一个相应的关键词命令;含噪声段的孤立语音——在关键词命令对应的语音前后有一小段高能量突发噪声。另外,把这三种类型的语音混合起来得到了混合语音数据。系统中采用的关键词包括:公用的关键词——打开,关闭,是,否;用于电梯控制的关键词——上升,下降,一层,二层,三层,四层;用于轮椅控制的关键词——前进,后退、停止;用于电视控制的关键词——向上,向下,一台,二台,三台,四台,五台。对于不同识别引擎以及不同语音数据,识别器的识别率以及系统的关键词检出率如表1所示。
表1 不同识别器在不同语音输入下的识别率及系统检出率
引擎
类型
输入
语音
孤立词识别引擎
连续语音识别引擎
连接词识别引擎
基于多识别引擎的
识别器
识别率
检出率
识别率
检出率
识别率
检出率
识别率
检出率
孤立语音
99%
93%
81%
73%
97%
87%
99%
94%
连续语音
0%
0%
87%
74%
78%
65%
87%
79%
含噪声段孤立语音
83%
15%
72%
58%
94%
75%
96%
81%
混合语音
60%
36%
80%
68%
90%
76%
94%
85%
通过以上的实验可以看出:对于三种不同的语音输入,采用单一的识别引擎,不可避免地使得在某一种或几种语音输入下识别器的识别率以及系统的检出率较低,极大地影响了系统的控制性能。当采用基于多识别引擎的识别器时,在任一语音输入类型下,无论是识别率还是检出率都能够达到使用单一识别器时最优的效果。由此可见,在采用基于多识别引擎的识别器时,能够充分利用不同识别引擎的优势,使得系统的性能得到最大的提升。
本文针对传统的单识别引擎在家电语音控制中存在的问题,提出了基于多识别引擎构造语音识别器的方法,使得对于不同类型的语音输入,都能够得到较好的关键词检出效果,从而提高了系统的性能;同时,本文对语音控制系统中关键词确认、对话控制策略以及模型自适应技术进行了一定的的分析和讨论,并且搭建了完整的语音控制系统。目前本系统已经通过了日本富士通公司的检测,其相关硬件的研制工作正在进行当中,有望在近期取得联调成功。
视其为孤立语音输入,这样一方面可以正确控制家电正常运行,另一方面通过自适应,不同识别引擎的模型都得到了更为精确的刻画,逐渐提高了系统识别率,从而使得连续语音识别率也得到了提高。另外,在各种情况下都采用了连接识别引擎,主要是考虑到残疾用户的语音中经常附带一些常见的突发噪声以及语气词,因此通过对此进行独立建模,能够去除语音信号首尾的噪声和语气词的影响,进一步提高识别器的鲁棒性。
3 其它关键技术分析
在家电语音控制系统中,除了识别器的性能严重影响系统的运行性能以外,关键词确认、对话控制策略以及识别器自适应也是至关重要的:关键词输入的结果给出候选关键词的置信度,因此直接影响了后续的对话控制模块可能采取的动作——当置信度高时,接受该关键词将其作为真正的关键词并且发出相应的控制指令;当置信度较低时,拒绝该候选词;当置信度处于中间水平时,产生相应的对话语音与用户进一步进行交互,对可能要发生的动作进行确认。在实际应用中,自适应技术保证了通过长期的用户和系统之间的交互,对识别器的模型进行修正,从而提高用户的语音识别率。
基于多识别引擎的识别器给关键词确认模块提供了更多的候选关键词,因此扩大了关键词的检出范围,为进一步提高检出率提供了条件;但是另一方面,更多的候选关键词意味着错误的候选关键词被接受的可能性也大大增加,系统的误警率也会随之上升。因此对于关键词确认性能的依赖也会更大,所以提取出多种有效的确认特片,利用神经元网络进行最终的置位度评价。这些确认特片包括:音素匹配得分特征、音素数匹配得分特征、似然得分特征、似然排位得分特片以及模型距离差累积得分特征。详细的确认过程见参考文献。
在对话控制模块中,由于不同的电路对应着不同的关键词,因此通过记录当前对话所处的处理(应用某一个电路的状态或者空闲状态),给识别器提供相应于该状态的关键词表,大大缩小了关键词表中关键词的总数,降低了关键词之间的混淆度,从而进一步提高了识别器的识别率。此外,对关键词重要性进行了分级,不同的关键词拥有不同的级别,对于重要的关键词来说,只有在其置信度很高的情况下才会将其直接发送给硬件控制模块去执行控制,否则要通过语音交互和用户确认的方法来确定是否执行该命令。
针对不同的识别器,采用不同的自适应策略:由于噪声模型和系统当前所处状态直接相关,因此随时准备利用系统空闲状态时采集的噪音段对噪声模型进行更新;对于孤立词和连接词识别引擎所采用的声学模型来说,利用经过确认的语音段对相应的模型者重新;对连续语音来说,由于只有对关键词的置信度评价,很难保证非关键词语音识别的正确性,因此只对关键词模型进行更新,在用户空闲时,引导用户利用给定的语音输入对连续语音所采用的模型进行更新,以达到模型自适应的效果。
4 实验及结果分析
本文所采用的试验平台是用于连续语音电梯控制声控仿真系统的关键词检出系统。整个系统由四个部分组成:语音识别模块、语音确认模块、自适应模块以及对话管理模块。语音识别模块采用的是无跨越从左向右的CHMM模型,特征向量为39维的MFCC特征——12维的MEL特征系数以及一阶和二阶差分;能量及其一阶和二阶差分。确认模块采用的是基于多特征联合得分的确认算法。
论文中所采用的语音数据库包括三种类型:孤立语音——对应系统中采用的关键词命令;连续语音——每段语音中包含一个相应的关键词命令;含噪声段的孤立语音——在关键词命令对应的语音前后有一小段高能量突发噪声。另外,把这三种类型的语音混合起来得到了混合语音数据。系统中采用的关键词包括:公用的关键词——打开,关闭,是,否;用于电梯控制的关键词——上升,下降,一层,二层,三层,四层;用于轮椅控制的关键词——前进,后退、停止;用于电视控制的关键词——向上,向下,一台,二台,三台,四台,五台。对于不同识别引擎以及不同语音数据,识别器的识别率以及系统的关键词检出率如表1所示。
表1 不同识别器在不同语音输入下的识别率及系统检出率
引擎
类型
输入
语音
孤立词识别引擎
连续语音识别引擎
连接词识别引擎
基于多识别引擎的
识别器
识别率
检出率
识别率
检出率
识别率
检出率
识别率
检出率
孤立语音
99%
93%
81%
73%
97%
87%
99%
94%
连续语音
0%
0%
87%
74%
78%
65%
87%
79%
含噪声段孤立语音
83%
15%
72%
58%
94%
75%
96%
81%
混合语音
60%
36%
80%
68%
90%
76%
94%
85%
通过以上的实验可以看出:对于三种不同的语音输入,采用单一的识别引擎,不可避免地使得在某一种或几种语音输入下识别器的识别率以及系统的检出率较低,极大地影响了系统的控制性能。当采用基于多识别引擎的识别器时,在任一语音输入类型下,无论是识别率还是检出率都能够达到使用单一识别器时最优的效果。由此可见,在采用基于多识别引擎的识别器时,能够充分利用不同识别引擎的优势,使得系统的性能得到最大的提升。
本文针对传统的单识别引擎在家电语音控制中存在的问题,提出了基于多识别引擎构造语音识别器的方法,使得对于不同类型的语音输入,都能够得到较好的关键词检出效果,从而提高了系统的性能;同时,本文对语音控制系统中关键词确认、对话控制策略以及模型自适应技术进行了一定的的分析和讨论,并且搭建了完整的语音控制系统。目前本系统已经通过了日本富士通公司的检测,其相关硬件的研制工作正在进行当中,有望在近期取得联调成功。
引用地址:实用的家电语音控制系统的设计
2 基于多识别引擎的识别器设计
2.1 传统识别引擎简介
根据待识别语音属于单一用户还是公众进行分类,可以将其分为特定人识别以及非特定人识别。由于设计目标是针对特定用户的,因此采用特定人识别器。如果根据输入语音特点以及建模方法进行分类,当前的识别引擎主要分为孤立词识别、连续语音识别以及连接词识别等引擎。下面分别介绍几种不同的识别引擎以及各自的优缺点。
2.1.1 孤立词识别引擎
由于孤立词识别引擎的输入是孤立的词汇,因此其识别范围小,建模精确,识别率高,非特定人的孤立词识别引擎的识别率可达95%左右,特定人的识别率甚至可达99%以上。但是孤立词识别引擎要求用户的输入必须是一个个独立的单词,显然对于连续的语音流无法处理。即使是独立的单词,如果由于用户的习惯或者生理原因,在语音中含有一些语气词或者其它高能量的突发噪声,将严重影响系统的识别率。
2.1.2 连续语音识别引擎
连续语音识别引擎是以音节或者音素为单位进行建模的,很好地解决了孤立词识别中对输入语音的限制,而且通过对常见的语气词以及噪声的建模,也能够解决由其引起的识别率下降的问题。但是连续语音的识别率很低,即使在实验室环境下,其识别率最高也只能达90%左右。显然连续语音识别引擎难以单独用于家电语音控制系统。
2.1.3 连接词识别引擎
连接词识别引擎介于孤立词识别引擎和连续语音识别引擎之间。它以孤立词为模型,通过对孤立词的拼接实现对连续语音流的识别。对于小型的语音识别系统来说,由于其词表较小,因此建模方便,而且建模精度高,对关键词的识别率接近于孤立词识别引擎,很好地解决了孤立词识别引擎无法解决的连续语音流问题。但是当输入语音流包含过多的音节时,其识别率不可避免地会下降很多。
用户在选择识别引擎的时候,主要需要考虑的因素包括:识别率、实时响应速度、鲁棒性、输入语音限制、使用舒适性等。
2.2 基于多识别引擎的识别器设计
通过对识别引擎的分析以及对传统识别引擎的介绍可以看到,无论单独选择哪种识别引擎,都不能够完善地满足实用的语音控制系统的要求,因此设计了一种多识别引擎的并行识别器,能够获得传统识别器无法兼得的优点。图2给出了基于多识别引擎的识别器结构图。
2.2.1 基于多识别引擎的识别器工作原理
图2中,识别引擎1为孤立词识别引擎;识别引擎2为连接词识别引擎;识别引擎3为连续语音识别引擎。识别器具体的工作流程如下:
(1)对输入语音进行预处理,包括语音信号的切分以及噪声去除等。语音信号的切分采用的是基于能量窗计算的切分算法,使得语音信号的端点更准确。
(2)根据输入语音的物理长度以及其它物理特征预判输入语音为孤立词输入还是连续语音输入。如果语音信号较短,则采用识别引擎1、2进行识别;如果信号较长,则采用识别引擎2、3进行识别;如果不能确定是孤立语音还是连续语音,则同时采用三个识别引擎进行识别。
(3)对于不同的识别引擎,将得到的识别结果作为候选关键词(如果识别结果不同则为多候选)送入确认模块进行确认。
2.2.2 基于多识别引擎的识别器性能分析
由于基于多识别引擎的识别器至少同时启动了两个或者三个识别引擎,因此系统的响应时间不可避免地要受到影响。所以在语音建模时,采用参数共享的方法,从而降低了计算法复杂度,提高了系统响应速度。同时注意到,对于孤立语音来说,由于识别引擎1、2的识别速度很快,因此完全可以满足实时响应的要求;对于连续语音来说,其识别时间主要耗费在识别引擎3上,这是不可避免的,系统引入的附加耗时很小,因此基本上不会因此而降低系统的响应速度。
而多识别引擎的识别器的建立,使得无论连续语音输入还是孤立语音输入,都能采用合适的识别引擎进行识别,从而在允许用户自由交流的基础上,保证了系统的识别率得到大幅度的提高。尤其是用户在采用连续语音输入系统不能正确识别时,可以降低要求,
视其为孤立语音输入,这样一方面可以正确控制家电正常运行,另一方面通过自适应,不同识别引擎的模型都得到了更为精确的刻画,逐渐提高了系统识别率,从而使得连续语音识别率也得到了提高。另外,在各种情况下都采用了连接识别引擎,主要是考虑到残疾用户的语音中经常附带一些常见的突发噪声以及语气词,因此通过对此进行独立建模,能够去除语音信号首尾的噪声和语气词的影响,进一步提高识别器的鲁棒性。
3 其它关键技术分析
在家电语音控制系统中,除了识别器的性能严重影响系统的运行性能以外,关键词确认、对话控制策略以及识别器自适应也是至关重要的:关键词输入的结果给出候选关键词的置信度,因此直接影响了后续的对话控制模块可能采取的动作——当置信度高时,接受该关键词将其作为真正的关键词并且发出相应的控制指令;当置信度较低时,拒绝该候选词;当置信度处于中间水平时,产生相应的对话语音与用户进一步进行交互,对可能要发生的动作进行确认。在实际应用中,自适应技术保证了通过长期的用户和系统之间的交互,对识别器的模型进行修正,从而提高用户的语音识别率。
基于多识别引擎的识别器给关键词确认模块提供了更多的候选关键词,因此扩大了关键词的检出范围,为进一步提高检出率提供了条件;但是另一方面,更多的候选关键词意味着错误的候选关键词被接受的可能性也大大增加,系统的误警率也会随之上升。因此对于关键词确认性能的依赖也会更大,所以提取出多种有效的确认特片,利用神经元网络进行最终的置位度评价。这些确认特片包括:音素匹配得分特征、音素数匹配得分特征、似然得分特征、似然排位得分特片以及模型距离差累积得分特征。详细的确认过程见参考文献。
在对话控制模块中,由于不同的电路对应着不同的关键词,因此通过记录当前对话所处的处理(应用某一个电路的状态或者空闲状态),给识别器提供相应于该状态的关键词表,大大缩小了关键词表中关键词的总数,降低了关键词之间的混淆度,从而进一步提高了识别器的识别率。此外,对关键词重要性进行了分级,不同的关键词拥有不同的级别,对于重要的关键词来说,只有在其置信度很高的情况下才会将其直接发送给硬件控制模块去执行控制,否则要通过语音交互和用户确认的方法来确定是否执行该命令。
针对不同的识别器,采用不同的自适应策略:由于噪声模型和系统当前所处状态直接相关,因此随时准备利用系统空闲状态时采集的噪音段对噪声模型进行更新;对于孤立词和连接词识别引擎所采用的声学模型来说,利用经过确认的语音段对相应的模型者重新;对连续语音来说,由于只有对关键词的置信度评价,很难保证非关键词语音识别的正确性,因此只对关键词模型进行更新,在用户空闲时,引导用户利用给定的语音输入对连续语音所采用的模型进行更新,以达到模型自适应的效果。
4 实验及结果分析
本文所采用的试验平台是用于连续语音电梯控制声控仿真系统的关键词检出系统。整个系统由四个部分组成:语音识别模块、语音确认模块、自适应模块以及对话管理模块。语音识别模块采用的是无跨越从左向右的CHMM模型,特征向量为39维的MFCC特征——12维的MEL特征系数以及一阶和二阶差分;能量及其一阶和二阶差分。确认模块采用的是基于多特征联合得分的确认算法。
论文中所采用的语音数据库包括三种类型:孤立语音——对应系统中采用的关键词命令;连续语音——每段语音中包含一个相应的关键词命令;含噪声段的孤立语音——在关键词命令对应的语音前后有一小段高能量突发噪声。另外,把这三种类型的语音混合起来得到了混合语音数据。系统中采用的关键词包括:公用的关键词——打开,关闭,是,否;用于电梯控制的关键词——上升,下降,一层,二层,三层,四层;用于轮椅控制的关键词——前进,后退、停止;用于电视控制的关键词——向上,向下,一台,二台,三台,四台,五台。对于不同识别引擎以及不同语音数据,识别器的识别率以及系统的关键词检出率如表1所示。
表1 不同识别器在不同语音输入下的识别率及系统检出率
引擎
类型
输入
语音
孤立词识别引擎
连续语音识别引擎
连接词识别引擎
基于多识别引擎的
识别器
识别率
检出率
识别率
检出率
识别率
检出率
识别率
检出率
孤立语音
99%
93%
81%
73%
97%
87%
99%
94%
连续语音
0%
0%
87%
74%
78%
65%
87%
79%
含噪声段孤立语音
83%
15%
72%
58%
94%
75%
96%
81%
混合语音
60%
36%
80%
68%
90%
76%
94%
85%
通过以上的实验可以看出:对于三种不同的语音输入,采用单一的识别引擎,不可避免地使得在某一种或几种语音输入下识别器的识别率以及系统的检出率较低,极大地影响了系统的控制性能。当采用基于多识别引擎的识别器时,在任一语音输入类型下,无论是识别率还是检出率都能够达到使用单一识别器时最优的效果。由此可见,在采用基于多识别引擎的识别器时,能够充分利用不同识别引擎的优势,使得系统的性能得到最大的提升。
本文针对传统的单识别引擎在家电语音控制中存在的问题,提出了基于多识别引擎构造语音识别器的方法,使得对于不同类型的语音输入,都能够得到较好的关键词检出效果,从而提高了系统的性能;同时,本文对语音控制系统中关键词确认、对话控制策略以及模型自适应技术进行了一定的的分析和讨论,并且搭建了完整的语音控制系统。目前本系统已经通过了日本富士通公司的检测,其相关硬件的研制工作正在进行当中,有望在近期取得联调成功。
上一篇:基于Chebyshev混沌序列的数字图像扩频水印
下一篇:基于JPEG2000标准的感兴趣区域编码
- 热门资源推荐
- 热门放大器推荐
 ARA05050S12C
ARA05050S12C
小广播
热门活动
换一批
更多

最新手机便携文章
- 苹果遭4000万英国iCloud用户集体诉讼,面临276亿元索赔
- 消息称苹果、三星超薄高密度电池均开发失败,iPhone 17 Air、Galaxy S25 Slim手机“变厚”
- 美光亮相2024年进博会,持续深耕中国市场,引领可持续发展
- Qorvo:创新技术引领下一代移动产业
- BOE独供努比亚和红魔旗舰新品 全新一代屏下显示技术引领行业迈入真全面屏时代
- OPPO与香港理工大学续约合作 升级创新研究中心,拓展AI影像新边界
- 古尔曼:Vision Pro 将升级芯片,苹果还考虑推出与 iPhone 连接的眼镜
- 汇顶助力,一加13新十年首款旗舰全方位实现“样样超Pro”
- 汇顶科技助力iQOO 13打造电竞性能旗舰新体验
更多精选电路图






更多热门文章
更多每日新闻
- Allegro MicroSystems 在 2024 年德国慕尼黑电子展上推出先进的磁性和电感式位置感测解决方案
- 左手车钥匙,右手活体检测雷达,UWB上车势在必行!
- 狂飙十年,国产CIS挤上牌桌
- 神盾短刀电池+雷神EM-i超级电混,吉利新能源甩出了两张“王炸”
- 浅谈功能安全之故障(fault),错误(error),失效(failure)
- 智能汽车2.0周期,这几大核心产业链迎来重大机会!
- 美日研发新型电池,宁德时代面临挑战?中国新能源电池产业如何应对?
- Rambus推出业界首款HBM 4控制器IP:背后有哪些技术细节?
- 村田推出高精度汽车用6轴惯性传感器
- 福特获得预充电报警专利 有助于节约成本和应对紧急情况
更多往期活动
11月16日历史上的今天
厂商技术中心




 京公网安备 11010802033920号
京公网安备 11010802033920号