1 TMS320F2812简介
TMS320F2812是TI公司的一款用于控制的高性能、多功能、高性价比的32位定点DSP芯片。该芯片兼容TMS320LF2407指令系统最高可在150MHz主频下工作,并带有18k×16位0等待周期片上SRAM和128k×16位片上FLASH(存取时间36ns)。其片上外设主要包括2×8路12位ADC(最快80ns转换时间)、2路SCI、1路SPI、1路McBSP、1路eCAN等,并带有两个事件管理模块(EVA、EVB),分别包括6路PWM/CMP、2路QEP、3路CAP、2路16位定时器(或TxPWM/TxCMP)。另外,该器件还有3个独立的32位CPU定时器,以及多达56个独立编程的GPIO引脚,可外扩大于1M×16位程序和数据存储器。TMS320F2812采用哈佛总线结构,具有密码保护机制,可进行双16×16乘加和32×32乘加操作,因而可兼顾控制和快速运算的双重功能。
通过对TMS320F2812定点DSP芯片合理的系统配置和编程可实现快速运算,本文着重对此加以说明。
2 TMS320F2812基本系统配置
2.
1 TMS320F2812时钟
TMS320F2812的片上外设按输入时钟可分为如下4个组:
(1)SYSOUTCLK组:包括CPU定时器和eCAN总线,可由PLLCR寄存器动态地修改;
(2)OSCCLK组:主要是看门狗电路,由WDCR寄存器设置分频系数;
(3)低速组:有SCI、SPI、McBSP,可由LOSPCP寄存器设置分频系数;
(4)高速组:包括EVA/B、ADC,可由HISPCP寄存器设置分频系数。
为了使系统具有较快的工作速度,除了定时器和SCI等少数需要低速时钟的地方,其它外设均可以150MHz时钟工作。
2.2 存储空间
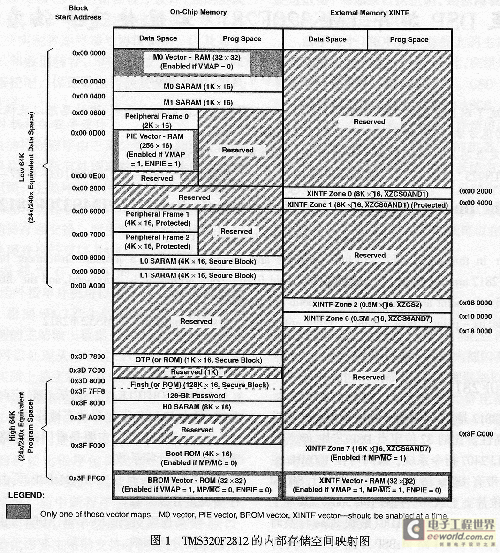
图1 所示是TMS320F2812的内部存储空间映射图。TMS320F2812为哈佛(Harvard)结构的DSP,即在同一个时钟周期内可同时进行一次取指令、读数据和写数据的操作。在逻辑上有4M×16位程序空间和4M×16位数据空间,但物理上已将程序空间和数据空间统一为一个4M×16位的存储空间,各总线按优先级由高到低的顺序为:数据写、程序写、数据读、程序读。其中由CY7C1041扩展的256k×16位SARAM位于Zone 6(0x100000~0x13FFFF),存取时间不小于12ns;128k×16位FLASH空间(0x3D8000~ 0x3F7FFF)取指时间不小于36ns。为了尽可能提高器件的工作速度,在对FLASH寄存器编程使其在较高速度下工作的同时,可将时间要求比较严格的程序(如时延计算子程序、FIR滤波子程序等)、变量(如FIR滤波器系数、自适应算法的权向量等)各堆栈空间搬移到H0、L0、L1、M0、M1空间来运行。
2.3 中断
TMS320F28x系列DSP片上都有非常丰富的外设,每个片上外设均可产生1个或多个中断请求。中断由两级组成,其中一级是PIE中断,另一级是CPU中断。CPU中断有32个中断源,包括RESET、NMI、EMUINT、ILLEGAL、12个用户定义的软件中断USER1~USER12和16个可屏蔽中断(INT1~INT14、RTOSINT和DLOGINT)。所有软件中断均属于非屏蔽中断。由于CPU没有足够的中断源来管理所有的片上外设中断请求,所以在TMS320F28x系列DSP中设置了一个外设中断扩展控制器(PIE)来管理片上外设和外部引脚引起的中断请求。
PIE中断共有96个,被分为12个组,每组内有8个片上外设中断请求,96个片上外设中断请求信号可记为INTx.y(x=1,2,…,12;y=1,2,…,8)。每个组输出一个中断请求信号给CPU,即PIE的输出INTx(x=1,2,…,…12)对应CPU中断输入的INT1~INT12。TMS320F28x系列DSP的96个可能的PIE中断源中有45个被TMS320F2812使用,其余的被保留作以后的DSP器件使用。
ADC、定时器、SCI编程等均以中断方式进行,可提高CPU的利用率。
2.4 复位引导
图2所示是TMS320F2812的片上引导ROM空间映射。其此导程序配置在图2中的0x3FFC00~0x3FFFBF,根据图1,设置VMAP=1,MP/MC=0,ENPIE=0,复位向量指向片上0x3FFFC0,而片上0x3FFFC0中内容为0x3FFC00,即指向图2中的引导程序。配置表2中的GPIOF4(SCITXDA)=1,则转向FLASH中的0x3F7FF6开始执行程序,最后在0x3F7FF6片设置跳转指令指向用户程序的开始处,以开始运行用户程序。由于在实际应用中使用了PIE中断,因此,在用户应用程序中,应首先初始化PIE中断向量表,然后使能PIE。
3 编程设计
编程是实现系统正常工作和快速运算必不可少的重要环节。在系统配置合理的条件下,用定点芯片实现快速运算的关键用整数取代浮点数进行计算处理。用C编译器时,为产生最优代码,应遵循以下原则:
(1)将除法转换为乘法,尽量使编译器产生MAC指令,以充分利用DSP的硬件乘法器资源进行快速运算,且应使MAC的操作数为局部变量以分配到寄存器中(或到一个累加器中)。
(2)尽可能使用静态直接插入函数,以节省函数调用的额外开销。
(3)对FOR循环的上限,使用常数或具有常数属性的变量可产生重复指令RPT。
3.1 ADC编程
TMS20F2812带有两个8选1多路切换器和双采样/保持器的12位ADC,模拟量输入范围为0~3V,最快转换速率为80ns,选用10kSPS采样率,并采用EVA的定时器(0.1ms)自动触发方式,可同时采样4个通道,并采用每次转换结束的中断方式来纪录采样结果(右移4位)。
转换结果=(212
-1)×(输入的模拟信号-ADCLO)/3
ADC转换时,首先初始化DSP系统,然后设置PIE中断矢量表,再初始化ADC模块,接着将ADC中断的入口地址装入中断矢量表并开中断,然后再启动0.1ms定时器,同时等待ADC中断,最后在ADC中断中读取ADC转换结果,并用软件启动下一次中断。
3.2 FIR滤波器编程
目标信号对某些低频干扰非常敏感,它将直接响应到定位结果和数据的有效性。为了在滤波后不影响时延数据的计算,可采用线性相位的FIR滤波器。滤波器系数h(i)用MATLAB的产生,并在变成整形然后固化到程序中,这样做(而不是单独计算滤波器系数)的目的是为了实现快速滤波而不会过多增加整个测量系统定位计算的时间。
3.3 定位算法的移植
由于定位算法采用自适应时延估计法,因此计算量非常庞大,对DSP芯片性能要求较高。TMS320F2812具有32位硬件乘法器和累加器,其RPT指令非常适合循环计算,处理能力可达150MIPS,因而具有较高的性能。但它是一款定点处理芯片,需要使用定点算法来解决处理量大的问题。因此,对初始数据、权矢量应采用16位整形变量(Q=12:由ADC转换精度决定),而循环计算中产生的中间结果则使用32位整形变量(Q=20:在结果不溢出的情况下尽量满足计算精度);至于对三角函数等的运算,可用查表法并利用图2中的表格来进行快速计算。
C编译器带有浮点运算库,因此可将浮点算法和定点算法的结果进行比较,对于4路各1024点数据处理,用浮点算法实现约需3.6秒,而用定点算法只需1.3秒。
另外,还可对算法进行优化。第一是将经常使用的中间变量配置到等待周期为0的内存中;第二是采用FLASH加速技术(使能FOPT寄存器的ENPIPE位实现预指机制的FLASH流水线模式),这样可以达到100~120MIPS的处理能力,大大高于其本身36ns的读取能力。需要注意的是,由于TMS320F2812的保护机制,对FLASH寄存器进行存取的这段程序必须搬移到L0、L1中执行。尽管这样,将这段对时间要求比较荷记得的算法移植到内存H0中,可以达到最高150MIPS的处理速度,并能使用函数memcpy()完成程序的搬移。
4 结束语
在计算量较大时,通常选用浮点DSP芯片。实际上,为了充分利用定点DSP芯片的片上资源,也能利用本文所介绍的方法选用定点芯片来达到较高的计算速度,这样可节省硬件设计费用和周期,并降低功耗。
上一篇:基于FPGA+DSP架构视频处理系统设计
下一篇:DSP的并行处理方法
推荐阅读最新更新时间:2024-05-02 23:11

 电力系统谐波(第二版)
电力系统谐波(第二版)




 京公网安备 11010802033920号
京公网安备 11010802033920号