摘要:对AD公司的TigerSHARC DSP(ADSP-TS101S)和摩托罗拉公司的具有AltiVec矢量处理器核的PowerPC系列MPC7410和MPC7455处理器,在连续实时信号处理领域的应用进行了评估。
关键词:连续实时信号处理 I/O带宽 ADSP-TS101S MPC7410 MPC7455
对于复杂、实时信号算是系统的设计人员来讲,最严峻的挑战是针对给定任何选择一个最有效的处理器。因为处理器效率依赖于应用,涉及到结构和应用等各个方面,因此折中的办法很难定义和评估。用通常使用的方法评价处理器,往往误导人们。因为它掩盖了许多依赖应用并使实际性能下降因素;在不同的处理器上执行应用,然后评估每个处理器执行的实际性能,这种方法费用昂贵、花费时间,不切合实际。
1 处理器概况
AD公司的TigerSHARC DSP(ADSP-TS101S)和摩托罗位公司PowerPC系列处理器代表了获得高性能计算能力的不同结构和方法。TigerSHARC代表DSP的传统做法,它具有低开销、确定性和DMA引擎等特点,专门用于开发嵌入式实时应用系统,例如雷达、声纳、无线通信和图像处理。相反,PowerPC是一种RISC处理器,用于开发副苹果计算机最高性能的G4工作站;具有很高的时钟频率以及强大的AltiVec矢量处理引擎,在一些嵌入式信号处理应用方面也取得了很大的成功。
很明显,具有AltiVec核的PowerPC G4(74xx)具有较高的核时钟速率与性能。PowerPC的核时钟速率几乎是目前TigerSHARC的3.3倍(不久更快版本的TigerSHARC将发布)。AltiVec核每个周期执行单条指令,每128位向量包含4个独立的32位数据单元,这就是众所周知的SIM-D(单指令多数据)结构。当执行一次乘加(MAC)矢量运算时,达到峰值处理能力,每周期可完成8次浮点操作。对于1GHz的MPC7455,峰值处理能力可达8000M次/s浮点运算。AltiVec每周期能执行8次整数或定点操作,峰值整数运算能力为8000MOPS(百万次操作/s)。
 相反,TigerSHARC有两个独立的32闰处理器核,或称MIMD(多指令多数据)结构。每个计算单元每周期能执行一次乘法以及和差分运算,对于300MHz ADSP-TS101S每周期完成6次浮点运算或1800MFLOPS峰值运算能力。当执行16位数据运算时,TigerSHARC可以利用它的超标量体系结构,分离两个独立32位计算单元成2个单独的16位SIMD单元,这样每个操作在两个数据单元,每个周期可以增加超过12次的操作。另外,TigerSHARC有另外两个专门的16位整数引擎,每个周期可以增加超过12次的操作,这样每个周期共计24次整数运算,7200MOPS。
2 I/O带宽与处理能力的比值
在许多信号处理的应用中,受限于数据流而不是处理能力,因此理解处理器I/O能力以及与处理器内核的数据交换的性能十分重要。衡量的尺度是I/O带宽与处理率之比(BPR),即处理器峰值I/O带宽(MB/s)除以峰值处理能力(MFLOPS)。1B/FLOP的BPR指示它是一个比较平衡的连续信号处理结构,意味着处理器对每个浮点操作能完成1B数据传输。一个处理器的BPR明显高于或低于1B/FLOP,表示这种结构比连续信号处理器更适合数据流搬移或后向数据处理。
图1所示为PowerPC处理器节点方框图。从图中可以看出所有处理器I/O的访问必须通过MPC和控制器/桥芯片之间的64位,128MHz(对于MPC7455为133MHz)系统总线。对于MPC7410任何一个处理器的最高I/O带宽是1000MB/s,对MPC7455的最高I/O带宽是1064 MB/s。
然而由于Altivec很强大,这种适宜的高带宽不一定总能跟上核的速度。当MPC7455执行8000MFLOPS时,数据搬移的速度仅为1064MB/s。BPR值只有0.13,说明这种结构的I/O带宽和处理能力是不平衡的。因此,PowerPC对块处理是有效的(比如具有高的计算和相对低的数据流动),但对连续的、高数据流动、较少计算的连续信号处理,是低效率的。
TigerSHARC是为多处理器设计的,而且提供了64位、100MHz共享系统总线以及4个8位,250MHz的Link口作I/O和处理器之间的数据通信,簇总线的搬移数据速率为800MB/s。数据还可以通过Link口以50MB/s速度进行传送,每个TigerSHRC提供总的I/O带宽可达1800MB/s。TigerSHARC的BPR是0.1,表明对连续的信号处理是平衡的优化结构。
3 信号处理能力—cFFT
1024点复数FFT(cFFT)是评价信号处理性能使用最广泛的基准。原因如下:第一,清晰而且容易易化;第二,在大多数应用中,它是最普遍使用的信号处理函数;第三,cFFT可以评估处理器的数据处理能力和处理速度。
值得注意的是,由于PwerPC的速度和性能,在计算1024点cFFT有明显优越性;然而TigerSHARC是为DSP裁剪定制的,在执行信号处理算法时会更加有效。这是由于芯片具有极好的数据搬移的能力、平衡以及单周期执行蝶形运算能力(乘法、加法、差分)。AltiVec核比TigerSHARC核快3.3倍,潜在处理速率是TIgerSHARC的4.4倍,然而它执行一个1024点cFFT仅比TIgerSHARC快2.5倍。TigerSHARC在9750周期可以完成CFFT运算,而PowerPC必须用13000个周期,因此,在执行一个1024点CFFT时,TigerSHARC的计算效率比PowerPC高33%。换句话说,如果以相同的时钟频率运行,TIgerSHARC会超过PowerPC 33%。随着TigerSHARC时钟速率继续提升,考虑成本和功耗等问题,当它执行FFT信号处理应用时,它的能力要显明超过AltiVec。
4 连续的cFFT
评价处理器能力时,通常考虑它的处理能力、I/O带宽,甚至算法的执行,但遗憾的是这些评估没有一个能真实反映实际应用。实际应用时,这些因素往往相互影响。数据必须按所希望的那样同时输入、处理、输出。每个1024点cFFT需要8KB数据输入(1024个样本%26;#215;2个样本/IQ对%26;#215;4字节/样本)和8KB数据输出,共16KB的数据流。通过比较1024点cFFT基准与16KB乘积与处理器的I/O带宽,来决定是受限于处理器的计算能力还是I/O带宽。
对于TigerSHARC,其准的倒数表示每秒钟能执行30 769次1024点cFFT,由于TIgerSHARC在后台能搬移所需要的数据,需要有504MB/s的数据流(30769/s%26;#215;16KB),可以保证处理器的I/O带宽,因此TigerSHARC完全适合如此应用。
对于MPC7410,1024点CFFT其准其实是误导。因为它不能同时搬移数据和进行数据处理,而且在处理时间里,8KB的输入数据必须搬入高速缓存(cache),8KB的输出数据必须搬出的高速缓存(cache)。搬移数据需要增加16.4μs的处理时间,执行1024点CFFT共需要38.4μs 的时间。考虑到数据的租用移,1024点CFFT基准的倒数为1/38.4μs。
然而对于MPC7455的情况不同,基准的倒数显示处理器内核每秒处理76 923次1024点CFFT,需要1260MB/s数据流量。尽管PowerPC进行处理的同时能搬移数据,但它的峰值带宽仅为1064MB/s,因此在这一应用中带宽受到了限制。假设它能连续保持峰值I/O带宽(cache管理和控制器瓶颈会明显减小I/O带宽,不在本文讨论管理),PMC7455每秒仅能执行64941次1024点cFFT(1064MB/s除16KB/1024点cFFT),明显比基准的倒数要小。
相反,TigerSHARC有两个独立的32闰处理器核,或称MIMD(多指令多数据)结构。每个计算单元每周期能执行一次乘法以及和差分运算,对于300MHz ADSP-TS101S每周期完成6次浮点运算或1800MFLOPS峰值运算能力。当执行16位数据运算时,TigerSHARC可以利用它的超标量体系结构,分离两个独立32位计算单元成2个单独的16位SIMD单元,这样每个操作在两个数据单元,每个周期可以增加超过12次的操作。另外,TigerSHARC有另外两个专门的16位整数引擎,每个周期可以增加超过12次的操作,这样每个周期共计24次整数运算,7200MOPS。
2 I/O带宽与处理能力的比值
在许多信号处理的应用中,受限于数据流而不是处理能力,因此理解处理器I/O能力以及与处理器内核的数据交换的性能十分重要。衡量的尺度是I/O带宽与处理率之比(BPR),即处理器峰值I/O带宽(MB/s)除以峰值处理能力(MFLOPS)。1B/FLOP的BPR指示它是一个比较平衡的连续信号处理结构,意味着处理器对每个浮点操作能完成1B数据传输。一个处理器的BPR明显高于或低于1B/FLOP,表示这种结构比连续信号处理器更适合数据流搬移或后向数据处理。
图1所示为PowerPC处理器节点方框图。从图中可以看出所有处理器I/O的访问必须通过MPC和控制器/桥芯片之间的64位,128MHz(对于MPC7455为133MHz)系统总线。对于MPC7410任何一个处理器的最高I/O带宽是1000MB/s,对MPC7455的最高I/O带宽是1064 MB/s。
然而由于Altivec很强大,这种适宜的高带宽不一定总能跟上核的速度。当MPC7455执行8000MFLOPS时,数据搬移的速度仅为1064MB/s。BPR值只有0.13,说明这种结构的I/O带宽和处理能力是不平衡的。因此,PowerPC对块处理是有效的(比如具有高的计算和相对低的数据流动),但对连续的、高数据流动、较少计算的连续信号处理,是低效率的。
TigerSHARC是为多处理器设计的,而且提供了64位、100MHz共享系统总线以及4个8位,250MHz的Link口作I/O和处理器之间的数据通信,簇总线的搬移数据速率为800MB/s。数据还可以通过Link口以50MB/s速度进行传送,每个TigerSHRC提供总的I/O带宽可达1800MB/s。TigerSHARC的BPR是0.1,表明对连续的信号处理是平衡的优化结构。
3 信号处理能力—cFFT
1024点复数FFT(cFFT)是评价信号处理性能使用最广泛的基准。原因如下:第一,清晰而且容易易化;第二,在大多数应用中,它是最普遍使用的信号处理函数;第三,cFFT可以评估处理器的数据处理能力和处理速度。
值得注意的是,由于PwerPC的速度和性能,在计算1024点cFFT有明显优越性;然而TigerSHARC是为DSP裁剪定制的,在执行信号处理算法时会更加有效。这是由于芯片具有极好的数据搬移的能力、平衡以及单周期执行蝶形运算能力(乘法、加法、差分)。AltiVec核比TigerSHARC核快3.3倍,潜在处理速率是TIgerSHARC的4.4倍,然而它执行一个1024点cFFT仅比TIgerSHARC快2.5倍。TigerSHARC在9750周期可以完成CFFT运算,而PowerPC必须用13000个周期,因此,在执行一个1024点CFFT时,TigerSHARC的计算效率比PowerPC高33%。换句话说,如果以相同的时钟频率运行,TIgerSHARC会超过PowerPC 33%。随着TigerSHARC时钟速率继续提升,考虑成本和功耗等问题,当它执行FFT信号处理应用时,它的能力要显明超过AltiVec。
4 连续的cFFT
评价处理器能力时,通常考虑它的处理能力、I/O带宽,甚至算法的执行,但遗憾的是这些评估没有一个能真实反映实际应用。实际应用时,这些因素往往相互影响。数据必须按所希望的那样同时输入、处理、输出。每个1024点cFFT需要8KB数据输入(1024个样本%26;#215;2个样本/IQ对%26;#215;4字节/样本)和8KB数据输出,共16KB的数据流。通过比较1024点cFFT基准与16KB乘积与处理器的I/O带宽,来决定是受限于处理器的计算能力还是I/O带宽。
对于TigerSHARC,其准的倒数表示每秒钟能执行30 769次1024点cFFT,由于TIgerSHARC在后台能搬移所需要的数据,需要有504MB/s的数据流(30769/s%26;#215;16KB),可以保证处理器的I/O带宽,因此TigerSHARC完全适合如此应用。
对于MPC7410,1024点CFFT其准其实是误导。因为它不能同时搬移数据和进行数据处理,而且在处理时间里,8KB的输入数据必须搬入高速缓存(cache),8KB的输出数据必须搬出的高速缓存(cache)。搬移数据需要增加16.4μs的处理时间,执行1024点CFFT共需要38.4μs 的时间。考虑到数据的租用移,1024点CFFT基准的倒数为1/38.4μs。
然而对于MPC7455的情况不同,基准的倒数显示处理器内核每秒处理76 923次1024点CFFT,需要1260MB/s数据流量。尽管PowerPC进行处理的同时能搬移数据,但它的峰值带宽仅为1064MB/s,因此在这一应用中带宽受到了限制。假设它能连续保持峰值I/O带宽(cache管理和控制器瓶颈会明显减小I/O带宽,不在本文讨论管理),PMC7455每秒仅能执行64941次1024点cFFT(1064MB/s除16KB/1024点cFFT),明显比基准的倒数要小。
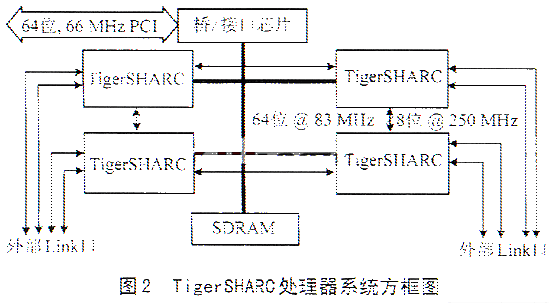 5 板极应用
如上所述,目前可获得基于所有处理器cPCI和VME总线的COTS板。然而,当与板级应用相联系时,会大大改变以上的评估结果。
因为MPC7455带宽受限,板级的结构会增加I/O的限制,进一步恶化处理器连续CFFT的性能。不考虑背板的数据流,对于PowerPC来讲,目前最好的I/O方式是两个64位/66MHz PMC,双528 MB/s PMC,可达到的数据流共1056MB/s。这已经小于MPC7455的1064MB/s峰值I/O带宽。实际上PMC达到连续、持续的吞吐率也是不可能的。假设1056MB/s持续的I/O带宽,PowerPC板持续1024点cFFTs为每秒64453次(1056MB/s被16KB除)——不依赖于PowerPC的数量或速度。
相反,TigerSHARC具有通过link口可扩展的I/O,图2所示为典型的4个TigerSHARC处理器的结构框图。在此例子中,每个处理器必须共享一个簇总线带宽,每个处理器使用2个Link口作为处理器间的数据传输,每个TigerSHARC的其它2个Link被用做I/O。这样每个处理器I/O总带宽就减少至700MB/s(Link口2%26;#215;250MB/s+1/4%26;#215;共享簇总线800MB/s)。然而,对于每个处理器,在最大连续CFFT速率的情况下,TigerSHARC需要504MB/s的带宽。虽然这一速率在TigerSHARC极限范围,但把连续的I/O分裂成Link口和簇总线也是不切合实际的做法。实际上,对于连续CFFT的最大I/O数据率是500MHz,由每个TIgerSHARC的两个Link口提供。很小带宽的限制降低了连续1024点cFFT的性能,每个TigerSHARC能处理30 517次。TigerSHARC低功耗、小尺寸和功能的集成,目前可得到簇总线(8片TigerSHARC)6U cPCI板卡。8片TigerSHARC每秒能执行244 135次连续1024点CFFT运算,几乎是理想PowerPC板卡的4倍。
6 结论
我们讨论的各种COTS板的应用,代表了连续实时信号处理应用的实际性能。对于其它因素的分析(如中断、开发环境、DMAs、存储器的利用、Cache管理、电源等)不在本文讨论范围。如果应用系统需要大量的计算、比较少的数据搬移和所谓的后向数据处理,由于较高的时钟频率和强大的内核,PowerPC是理想的选择;反之,对于像成像、雷达、声纳和监听等应用的连续、实时信号处理,由于需要比较高的数据吞吐率,TigerSHARC应该是首选。
5 板极应用
如上所述,目前可获得基于所有处理器cPCI和VME总线的COTS板。然而,当与板级应用相联系时,会大大改变以上的评估结果。
因为MPC7455带宽受限,板级的结构会增加I/O的限制,进一步恶化处理器连续CFFT的性能。不考虑背板的数据流,对于PowerPC来讲,目前最好的I/O方式是两个64位/66MHz PMC,双528 MB/s PMC,可达到的数据流共1056MB/s。这已经小于MPC7455的1064MB/s峰值I/O带宽。实际上PMC达到连续、持续的吞吐率也是不可能的。假设1056MB/s持续的I/O带宽,PowerPC板持续1024点cFFTs为每秒64453次(1056MB/s被16KB除)——不依赖于PowerPC的数量或速度。
相反,TigerSHARC具有通过link口可扩展的I/O,图2所示为典型的4个TigerSHARC处理器的结构框图。在此例子中,每个处理器必须共享一个簇总线带宽,每个处理器使用2个Link口作为处理器间的数据传输,每个TigerSHARC的其它2个Link被用做I/O。这样每个处理器I/O总带宽就减少至700MB/s(Link口2%26;#215;250MB/s+1/4%26;#215;共享簇总线800MB/s)。然而,对于每个处理器,在最大连续CFFT速率的情况下,TigerSHARC需要504MB/s的带宽。虽然这一速率在TigerSHARC极限范围,但把连续的I/O分裂成Link口和簇总线也是不切合实际的做法。实际上,对于连续CFFT的最大I/O数据率是500MHz,由每个TIgerSHARC的两个Link口提供。很小带宽的限制降低了连续1024点cFFT的性能,每个TigerSHARC能处理30 517次。TigerSHARC低功耗、小尺寸和功能的集成,目前可得到簇总线(8片TigerSHARC)6U cPCI板卡。8片TigerSHARC每秒能执行244 135次连续1024点CFFT运算,几乎是理想PowerPC板卡的4倍。
6 结论
我们讨论的各种COTS板的应用,代表了连续实时信号处理应用的实际性能。对于其它因素的分析(如中断、开发环境、DMAs、存储器的利用、Cache管理、电源等)不在本文讨论范围。如果应用系统需要大量的计算、比较少的数据搬移和所谓的后向数据处理,由于较高的时钟频率和强大的内核,PowerPC是理想的选择;反之,对于像成像、雷达、声纳和监听等应用的连续、实时信号处理,由于需要比较高的数据吞吐率,TigerSHARC应该是首选。
引用地址:连续实时信号处理器的性能分析
相反,TigerSHARC有两个独立的32闰处理器核,或称MIMD(多指令多数据)结构。每个计算单元每周期能执行一次乘法以及和差分运算,对于300MHz ADSP-TS101S每周期完成6次浮点运算或1800MFLOPS峰值运算能力。当执行16位数据运算时,TigerSHARC可以利用它的超标量体系结构,分离两个独立32位计算单元成2个单独的16位SIMD单元,这样每个操作在两个数据单元,每个周期可以增加超过12次的操作。另外,TigerSHARC有另外两个专门的16位整数引擎,每个周期可以增加超过12次的操作,这样每个周期共计24次整数运算,7200MOPS。
2 I/O带宽与处理能力的比值
在许多信号处理的应用中,受限于数据流而不是处理能力,因此理解处理器I/O能力以及与处理器内核的数据交换的性能十分重要。衡量的尺度是I/O带宽与处理率之比(BPR),即处理器峰值I/O带宽(MB/s)除以峰值处理能力(MFLOPS)。1B/FLOP的BPR指示它是一个比较平衡的连续信号处理结构,意味着处理器对每个浮点操作能完成1B数据传输。一个处理器的BPR明显高于或低于1B/FLOP,表示这种结构比连续信号处理器更适合数据流搬移或后向数据处理。
图1所示为PowerPC处理器节点方框图。从图中可以看出所有处理器I/O的访问必须通过MPC和控制器/桥芯片之间的64位,128MHz(对于MPC7455为133MHz)系统总线。对于MPC7410任何一个处理器的最高I/O带宽是1000MB/s,对MPC7455的最高I/O带宽是1064 MB/s。
然而由于Altivec很强大,这种适宜的高带宽不一定总能跟上核的速度。当MPC7455执行8000MFLOPS时,数据搬移的速度仅为1064MB/s。BPR值只有0.13,说明这种结构的I/O带宽和处理能力是不平衡的。因此,PowerPC对块处理是有效的(比如具有高的计算和相对低的数据流动),但对连续的、高数据流动、较少计算的连续信号处理,是低效率的。
TigerSHARC是为多处理器设计的,而且提供了64位、100MHz共享系统总线以及4个8位,250MHz的Link口作I/O和处理器之间的数据通信,簇总线的搬移数据速率为800MB/s。数据还可以通过Link口以50MB/s速度进行传送,每个TigerSHRC提供总的I/O带宽可达1800MB/s。TigerSHARC的BPR是0.1,表明对连续的信号处理是平衡的优化结构。
3 信号处理能力—cFFT
1024点复数FFT(cFFT)是评价信号处理性能使用最广泛的基准。原因如下:第一,清晰而且容易易化;第二,在大多数应用中,它是最普遍使用的信号处理函数;第三,cFFT可以评估处理器的数据处理能力和处理速度。
值得注意的是,由于PwerPC的速度和性能,在计算1024点cFFT有明显优越性;然而TigerSHARC是为DSP裁剪定制的,在执行信号处理算法时会更加有效。这是由于芯片具有极好的数据搬移的能力、平衡以及单周期执行蝶形运算能力(乘法、加法、差分)。AltiVec核比TigerSHARC核快3.3倍,潜在处理速率是TIgerSHARC的4.4倍,然而它执行一个1024点cFFT仅比TIgerSHARC快2.5倍。TigerSHARC在9750周期可以完成CFFT运算,而PowerPC必须用13000个周期,因此,在执行一个1024点CFFT时,TigerSHARC的计算效率比PowerPC高33%。换句话说,如果以相同的时钟频率运行,TIgerSHARC会超过PowerPC 33%。随着TigerSHARC时钟速率继续提升,考虑成本和功耗等问题,当它执行FFT信号处理应用时,它的能力要显明超过AltiVec。
4 连续的cFFT
评价处理器能力时,通常考虑它的处理能力、I/O带宽,甚至算法的执行,但遗憾的是这些评估没有一个能真实反映实际应用。实际应用时,这些因素往往相互影响。数据必须按所希望的那样同时输入、处理、输出。每个1024点cFFT需要8KB数据输入(1024个样本%26;#215;2个样本/IQ对%26;#215;4字节/样本)和8KB数据输出,共16KB的数据流。通过比较1024点cFFT基准与16KB乘积与处理器的I/O带宽,来决定是受限于处理器的计算能力还是I/O带宽。
对于TigerSHARC,其准的倒数表示每秒钟能执行30 769次1024点cFFT,由于TIgerSHARC在后台能搬移所需要的数据,需要有504MB/s的数据流(30769/s%26;#215;16KB),可以保证处理器的I/O带宽,因此TigerSHARC完全适合如此应用。
对于MPC7410,1024点CFFT其准其实是误导。因为它不能同时搬移数据和进行数据处理,而且在处理时间里,8KB的输入数据必须搬入高速缓存(cache),8KB的输出数据必须搬出的高速缓存(cache)。搬移数据需要增加16.4μs的处理时间,执行1024点CFFT共需要38.4μs 的时间。考虑到数据的租用移,1024点CFFT基准的倒数为1/38.4μs。
然而对于MPC7455的情况不同,基准的倒数显示处理器内核每秒处理76 923次1024点CFFT,需要1260MB/s数据流量。尽管PowerPC进行处理的同时能搬移数据,但它的峰值带宽仅为1064MB/s,因此在这一应用中带宽受到了限制。假设它能连续保持峰值I/O带宽(cache管理和控制器瓶颈会明显减小I/O带宽,不在本文讨论管理),PMC7455每秒仅能执行64941次1024点cFFT(1064MB/s除16KB/1024点cFFT),明显比基准的倒数要小。
5 板极应用
如上所述,目前可获得基于所有处理器cPCI和VME总线的COTS板。然而,当与板级应用相联系时,会大大改变以上的评估结果。
因为MPC7455带宽受限,板级的结构会增加I/O的限制,进一步恶化处理器连续CFFT的性能。不考虑背板的数据流,对于PowerPC来讲,目前最好的I/O方式是两个64位/66MHz PMC,双528 MB/s PMC,可达到的数据流共1056MB/s。这已经小于MPC7455的1064MB/s峰值I/O带宽。实际上PMC达到连续、持续的吞吐率也是不可能的。假设1056MB/s持续的I/O带宽,PowerPC板持续1024点cFFTs为每秒64453次(1056MB/s被16KB除)——不依赖于PowerPC的数量或速度。
相反,TigerSHARC具有通过link口可扩展的I/O,图2所示为典型的4个TigerSHARC处理器的结构框图。在此例子中,每个处理器必须共享一个簇总线带宽,每个处理器使用2个Link口作为处理器间的数据传输,每个TigerSHARC的其它2个Link被用做I/O。这样每个处理器I/O总带宽就减少至700MB/s(Link口2%26;#215;250MB/s+1/4%26;#215;共享簇总线800MB/s)。然而,对于每个处理器,在最大连续CFFT速率的情况下,TigerSHARC需要504MB/s的带宽。虽然这一速率在TigerSHARC极限范围,但把连续的I/O分裂成Link口和簇总线也是不切合实际的做法。实际上,对于连续CFFT的最大I/O数据率是500MHz,由每个TIgerSHARC的两个Link口提供。很小带宽的限制降低了连续1024点cFFT的性能,每个TigerSHARC能处理30 517次。TigerSHARC低功耗、小尺寸和功能的集成,目前可得到簇总线(8片TigerSHARC)6U cPCI板卡。8片TigerSHARC每秒能执行244 135次连续1024点CFFT运算,几乎是理想PowerPC板卡的4倍。
6 结论
我们讨论的各种COTS板的应用,代表了连续实时信号处理应用的实际性能。对于其它因素的分析(如中断、开发环境、DMAs、存储器的利用、Cache管理、电源等)不在本文讨论范围。如果应用系统需要大量的计算、比较少的数据搬移和所谓的后向数据处理,由于较高的时钟频率和强大的内核,PowerPC是理想的选择;反之,对于像成像、雷达、声纳和监听等应用的连续、实时信号处理,由于需要比较高的数据吞吐率,TigerSHARC应该是首选。
上一篇:基于DSP控制的PFC变换器的新颖采样算法
下一篇:TMS320C6711的FLASH引导装载系统研究与设计
- 热门资源推荐
- 热门放大器推荐
 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用 EL5111IWTZ-T7A
EL5111IWTZ-T7A
小广播
热门活动
换一批
更多

最新嵌入式文章

更多精选电路图






更多热门文章
更多每日新闻
- Power Integrations面向800V汽车应用推出新型宽爬电距离开关IC
- 打破台积电垄断!联电夺下高通先进封装订单
- Ampere 年度展望:2025年重塑IT格局的四大关键趋势
- 存储巨头铠侠正式挂牌上市:首日股价上涨超10%
- Vishay 推出新款精密薄膜MELF电阻,可减少系统元器件数量,节省空间,简化设计并降低成本
- 芯原推出新一代高性能Vitality架构GPU IP系列 支持DirectX 12和先进的计算能力
- NXP 2.5亿美元收购Aviva,但车载SerDes领域依然处于战国时期
- 应对 AI 时代的云工作负载,开发者正加速向 Arm 架构迁移
- 沉浸式体验漫威宇宙,英特尔锐炫显卡为《漫威争锋》提供Day 0支持
- 艾迈斯欧司朗与法雷奥携手革新车辆内饰,打造动态舱内环境
更多往期活动
厂商技术中心




 京公网安备 11010802033920号
京公网安备 11010802033920号