来源:内容来自「矽说」,谢谢。
想起写这篇矽说的起源是一个月前的AI界大新闻——知名AI硬件公司深鉴被FPGA巨头Xilinx收购,传说中的交易金额在n亿美金不等,大家纷纷感概创始人的财富自由与高尚情怀(给清华大学捐了500万,简直是国内由学、研至产再回馈学的典范),一时佳话。与此同时,各种危言耸听也开始流传,如AI领域的垂直整合大幕即将开启,泡沫破灭已经不远矣的恐惧也落在雨后春笋般崛起的AI硬件公司中。
我并不想去评断那个商业行为背后的动机,只是想以此为契机从技术的角度,略略讨论下这次收购背后的关键因素——FPGA和ASIC的在AI计算中衔接关系。因为并不是专家,所以如有错误理解请指出。
从FPGA到ASIC,异曲同工还是南辕北辙?
在国产AI硬件三强“寒地深”中,deephi最强的当属其面向AI的专用design kit —— DNNDK以及其FPGA的实现,其中涵盖了其大杀四方的必杀技——稀疏化网络。做AI硬件的如果没有看过剪枝(prunning)就可以放弃科研了。
与此同时,deephi也有其ASIC产品线——听涛系列SoC。

我们假设听涛的亚里士多德结构传承自深鉴在Zynq 7020上的Aristotle架构(Aristotle是亚里士多德的英文),即下图: (注:这里是姑妄言之随便臆测,这个假设很有可能是不对的)

那么,问题来了 AI硬件的架构最优解是否从FPGA 到 ASIC是一以贯之呢?
这个问题还需要回到FPGA和ASIC的设计的价值观。随着FPGA芯片的发展不断深化,在一个FPGA fabric中,核心基础模块早已不仅仅是查找表(Look Up Table, LUT)。在以算力为主要矛盾的FPGA设计中,(典型例子是神经网络),FPGA中的DSP和BRAM IP的高效率决定了该设计的最终性能。
让我们来看看目前应用广泛的Xilinx 7系列的dsp48 macro IP,其基本架构如下图,基本可以理解为一个可配置乘加模块,值得注意的是其输入位宽,25位和18位,输出位宽可以达到48位。

这时候,尴尬的故事发生了,DNN,特别是端测DNN的大部分应用仅仅需要8位精度,如果用牛逼的dsp48就是大炮打蚊子,如果用LUT综逻辑时序又无法满足。这个时候,Xilinx官宣了一份白皮书WP487,给出了一种在NN场景下一个dsp48怎样实现并行实现两个8-bit精度的方法。简而言之就是把两个8-比特数拼成一个27位的数,当中隔了10位然后和第三个数相乘,乘法的结果的MSB和 LSB分别是两个乘法的结果。总之,尴尬癌还是有那么点的。

在这个场景下,每次MAC需要3个周期才能完成,复杂的流水线实现会给带来很多debug的空间。然而在ASIC实现中,8-bit MAC仅仅需要一个周期,跑到500MHz是分分钟的事情。由此,如果照搬FGPA的RTL到ASIC,那将带来许多平白无故的性能损失。该问题可能在时下越来越流行的低精度神经网络中越来越显著,比如在ISSCC 2018中韩国KAIST提出的新形复用MAC,在乘加内部做了新逻辑,完全超出了FPGA的mapping范围,但是其在功耗性能上的优势显著。
同样的问题还发生在片上RAM的使用。笔者认为,CNN专用处理器和经典SIMD计算/矩阵乘加速器 最大的差别,就是在于利用CNN的数据复用实现多样化的data flow上。而实现各种data flow的切实需求就在于有一个不大不小的scratchpad用于实现存储partial sum。目前主流的设计,每个MAC对应scratchpad大小在0.5kb-2kb左右。而FPGA片上macro IP(RAMB18E1)提供的BRAM/FIFO 的单位尺寸为18kb,显著地大于scratchpad的需求。于是这个scratchpad在FPGA上的实现又陷于两难,直接综合将消耗大量的LUT中DFF的资源,如果用片上macro,又有一定程度的浪费,并且挤压了用于存储feature/weight的空间。由于这个scratchpad大小的尴尬处境,很多FPGA的DNN实现专注在矩阵乘法(Matrix product)的实现上,而放弃了在CNN/DNN中复杂data flow的支持。同样地,这个问题在以RAM compiler为基础的ASIC实现上毫无问题,毕竟ASIC设计中可以自由配置scratchpad的大小。
综上所述,FPGA和 ASIC在面向AI的专用设计中,虽然表面都是写RTL,但是在具体架构和思想上已经有了较大的差异。FPGA设计的最优解是最大化底层marco IP的拼积木设计,而ASIC却完全没有这样的限制,以放飞自我的方式寻找可能。由此,照搬FPGA而来的ASIC很有可能在某种程度上受这些限制的影响,也无法达到存在的ASIC最优解。这或许也是为什么深鉴在FPGA原型开发完成之后,还付出了大量努力才能完成真正ASIC设计的原因。
FPGA原型验证:食之无味,弃之可惜?
传统意义上,FPGA出现的一个重要因素是为了给ASIC做原型验证(Prototyping)的。不可否认,原型验证仍然是FPGA的一个重大市场。

在AI应用中,除了对RTL code的功能验证和高速仿真外,FPGA Prototyping对于产品的更重要优势在于,更早地让嵌入式软件设计(Embedded Software Development)进入整体设计流程。软件领域的bug和灵活度的数量级往往都远高于硬件,如果等ASIC流片完了再对软件和系统接口着手,那也是白白浪费时间。原型验证的一大优势就是尽早地从系统和集成的角度,以硬件原型着手进行软件与嵌入式的开发。而于此同时后端以及流片的ASIC研发时间可以同步进行。
但和RTL simulation相比,Prototype的debug性差也是路人皆知的。常见的FPGA Prototype的debug方法是人为的在RTL中设置观测点(probe),调用片上BRAM存储,然后用类似JTAG的串口方式读取存储信号,再现波形。显然地,这种观测方法方法是在和有实际功用的RTL竞争片上BRAM资源,特别是在存储深度大,位宽宽的情况下。更严重的问题是如果发生了新一轮规模性的修改probe,而导致的重新综合与实现可能会耗去大量时间,可能还不如simulation的效率高。目前主流的FPGA的debug方案基本都是如上思路,如下图中的ChipScope+ILA模式。
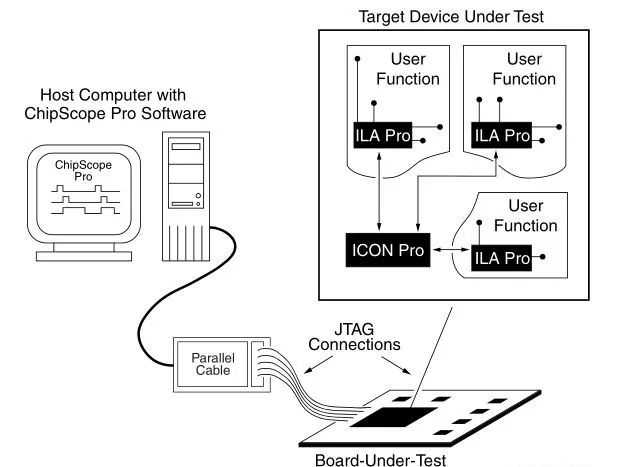
不仅如此,FPGA prototyping在复杂时钟设计中的表现也令人堪忧。对于FPGA的初学者,门控时钟(clock gating,CG)几乎是完全不推荐的。而作为最主流的ASIC降功耗手段,CG几乎存在AI芯片的每一角落,特别是在具有稀疏性的网络中,门控时钟是最简单易行的降低功耗的做法。FPGA对这一特点的弱支持将导致原型验证可能存在不完整性问题。除此之外,多时钟域的问题在FPGA的原型验证也是一个问题,由于FPGA片上的PLL资源受限,在原型设计中也将收到诸多限制。
上述种种原因的情况下,FPGA作为AI芯片的原型验证重要平台,虽然仍是不少产品的重要选项,但是目前的受到的挑战令他越来越后继乏力。
Hardware Emulator,领域专用的FPGA
随着集成电路EDA工具的发展,一个兼具良好debug性能,又可接近原型功能提供软件开发的便利的新型SoC系统开发工具正在崛起——hardware emulator(硬件模拟器)。可以说它兼具了simulation和prototype的优点,又在很大程度上弥补了缺点。目前主流的EDA工具开发商均提供emulator平台,并且期望在不远的将来,实现以emulator为中心的SoC开发流程。Synopsys 家的Zebu,Cadence家的Palladium和Mentor家的Veloce。其中Zebu就是以Xilinx的高端FPGA为基本元件搭建的。
从技术角度上,FPGA emulation 和 prototype的差别在于——emulator的RTL mapping是将原本的RTL分解映射(partition)到多块FPGA上,每块FPGA本身还集成了用于debug的观测硬件部分的代码。在Partition同时,设计EDA软件还关注模块间的通信行为,通过FPGA集成的高速传输(high speed link)和路由(router)特性完成实现SoC partition,避免了在单一FPGA中硬件资源受限制的问题。
下图从性能的角度比较了以FPGA为核心的原型验证平台与模拟器平台的上的区别。可以发现,emulator虽然在速度上并不具有优势,但是,其在内部数据的可观测性,以及由此带来的debug的可实现性能,均具有明显的优势。可以说,基于FPGA的模拟器正在并非对AISC 设计原代码的直接映射,反之是在源代码基础上通过Partition, Interconnection,Probe-serialization等一系列RTL的再生成后,产生的新RTL的映射。拿时髦的话来讲,emulator是领域专用的FPGA Prototyping。

当然,FPGA emulator有一个明显的劣势,那就是贵!对于刚过门槛的AI 硬件startup们,购买一台emulator是真的在流血。但即使如此,随着AI ASIC对于系统和应用的要求越来越高,未来基于FPGA的Emulator取代基于FPGA的Prototyping是否将成为一种潮流?让我们拭目以待。
FPGA AI:是否需要走ASIC的老路?
如前所述,FPGA设计很难直接照搬到ASIC。事实上,FPGA上的AI应用是否真的要走传统ASIC的老路,即“发现需求——定义产品规格——上量大规模出货——以年为时间单位更新换代”?我们认为,FPGA的可重配置特点让它完全没有必要走这条路,而是可以走更接近于软件开发模式的道路。一个例子就是最近流行的云端FPGA instance(AWS,阿里云等),用户可以根据其自身的需求在云端FPGA instance上烧入相应的bit-stream,从而让FPGA能成为针对你应用的专用加速器。另一个云FPGA的好处在于潜在地统一了FPGA的选型,令开源工作的移植减少了很多不必要的配置bug。著名的NVDLA的FPGA版本就以支持AWS的FPGA平台为主要方案。
至此,FPGA AI这样一来设计迭代速度(尤其是配合了Chisel,HLS等敏捷开发流程之后)可以远远快于传统ASIC流程,同时硬件的能效比则远高于传统的CPU/GPU。这一招在异构计算得到越来越多重视的今天可谓是迎合了潮流(关于异构计算详见RISC-V与DSA! 计算机架构宗师Patterson与Hennessy 演讲实录)。这也是为什么我们看到微软,亚马逊都纷纷在云端数据中心部署FPGA,而Intel则也在往高端CPU里加入Altera FPGA。未来,这种新的模式可望成为FPGA市场的一个新成长点,值得我们关注。
最后做个小总结,
(1)对于AI硬件的实现而言,FPGA和ASIC的 优化路径有很大区别,从FPGA到ASIC的直接移植并不是一种高效的做法。
(2)强调一下这里并不是说基于FPGA的AI实现就没有未来,(相反我觉得还潜力无限),本文只是对于从FPGA到ASIC的直接移植提出了一点小想法。我们预计FPGA将会配合敏捷设计拥有自己的新生态。
(3)FPGA对SoC设计流程的影响正在从原型验证往硬件模拟的角度发展,你的产品有没有掉队呢?
上一篇:SK电讯部署赛灵思FPGA用于AI加速,超越GPU实现5倍性能
下一篇:CIOReview杂志:Achronix将高性能计算市场中的界限推到了更远
推荐阅读最新更新时间:2024-05-03 03:12

 汽车电子的革新与FPGA-24页
汽车电子的革新与FPGA-24页 控制系统计算机辅助设计 — MATLAB语言与应用
控制系统计算机辅助设计 — MATLAB语言与应用










 京公网安备 11010802033920号
京公网安备 11010802033920号