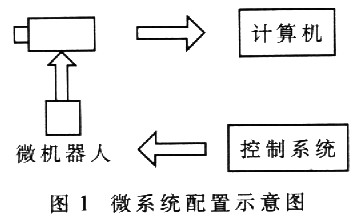
本文在系统控制电路中嵌入式实现语音识别算法,通过语音控制微机器人。
微机器人控制系统的资源有限,控制方法比较复杂,并且需要有较高的实时性,因此本文采用的语音识别算法必须简单、识别率高、占用系统资源少。
HMM(隐马尔可夫模型)的适应性强、识别率高,是当前语音识别的主流算法。使用基于HMM非特定人的语音识别算法虽然借助模板匹配减小了识别所需的资源,但是前期的模板储存工作需要大量的计算和存储空间,因此移植到嵌入式系统还有一定的难度,所以很多嵌入式应用平台的训练部分仍在PC机上实现。
为了使训练和识别都在嵌入式系统上实现,本文给出了一种基于K均值分段HMM模型的实时学习语音识别算法,不仅解决了上述问题,而且做到了智能化,实现了真正意义上的自动语音识别。
1 增量K均值分段HMM的算法及实现
由于语音识别过程中非特定的因素较多,为了提高识别的准确率,针对本系统的特点,采用动态改变识别参数的方法提高系统的识别率。
训练算法是HMM中运算量最大、最复杂的部分,训练算法的输出是即将存储的模型。目前的语音识别系统大都使用贝斯曼参数的HMM模型,采取最大似然度算法。这些算法通常是批处理函数,所有的训练数据要在识别之前训练好并存储。因此很多嵌入式系统因为资源有限不能达到高识别率和实时输出。
本系统采用了自适应增量K均值分段算法。在每次输入新的语句时都连续地计算而不对前面的数据进行存储,这可以节约大量的时间和成本。输入语句时由系统的识别结果判断输入语句的序号,并对此语句的参数动态地修改,真正做到了实时学习。
K均值分段算法是基于最佳状态序列的理论,因此可以采用Viterbi算法得到最佳状态序列,从而方便地在线修改系统参数,使训练的速度大大提高。
为了达到本系统所需要的功能,对通常的K均值算法作了一定的改进。在系统无人监管的情况下,Viterbi解码计算出最大相似度的语音模型,根据这个假设计算分段K均值算法的输入参数,对此模型进行参数重估。首先按照HMM模型的状态数进行等间隔分段,每个间隔的数据段作为某一状态的训练数据,计算模型的初始参数λ=f(a,A,B)。采用Viterbi的最佳状态序列搜索,得到当前最佳状态序列参数和重估参数θ,其中概率密度函数P(X,S|θ)代替了最大似然度算法中的P(X,θ),在不同的马尔科夫状态和重估之间跳转。基于K均值算法的参数重估流程如下:

为了使参数能更快地收敛,在每帧观察语音最佳状态序列的计算结束后,加入一个重估过程,以求更快地响应速度。

可以看到,增量K均值算法的特点为:在每次计算完观察值最佳状态序列后,插入一个重估过程。随时调整参数以识别下一个句子。
由于采用混合高斯密度函数作为输出概率分布可以达到较好的识别效果,因此本文采用M的混合度对数据进行训练。
对λ重估,并比较收敛性,最终得到HMM模型参数训练结果。
可见,用K均值法在线修改时,一次数据输入会有多次重估过程,这使系统使用最近的模型估计后续语句的最佳状态序列成为可能。但是对于在线修改参数要求,快速收敛是很重要的。为了得到更好的Viterbi序列,最佳状态序列使用了渐增的算法模型,即快速收敛算法。
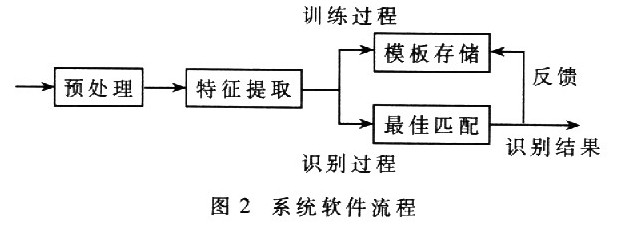
语音识别的具体实现过程为:数字语音信号通过预处理和特征向量的提取,用户通过按键选择学习或者识别模式;如果程序进入训练过程,即用户选择进行新词条的学习,则用分段K均值法对数据进行训练得到模板;如果进入识别模式,则从Flash中调出声音特征向量,进行HMM算法识别。在识别出结果后,立即将识别结果作为正确结果与前一次的状态做比较,得到本词条更好的模板,同时通过LED数字显示和语音输出结果。系统软件流程如图2所示。
对采集到的语音进行16kHz、12位量化,并对数字语音信号进行预加重:

L选择为320个点,用短时平均能量和平均过零率判断起始点,去除不必要的信息。
对数据进行FFT运算,得到能量谱,通过24通道的带通滤波输出X(k),然后再通过DCT运算,提取12个MFCC系数和一阶二阶对数能量,提取38个参数可以使系统识别率得到提高。
为了进行连接词识别,需要由训练数据得到单个词条的模型。方法为:首先从连接词中分离出每个孤立的词条,然后再进行孤立词条的模型训练。对于本系统不定长词条的情况,每个词条需要有一套初始的模型参数,然后按照分层构筑的HMM算法将所有词串分成孤立的词条。对每个词条进行参数的重估,判断是否收敛。如果差异小于某个域值就判断为收敛;否则将得到的参数作为新的初始参数再进行重估,直到收敛。
2 实验结果
实验采用30个人(15男,15女)的声音模型进行识别。首先由10人(5男,5女)对5个命令词(前进、后退、左移、右移、快速)分别进行初始数据训练,每人每词训练10次,得到训练模板。然后再由这30人随机进行非特定人语音识别。采用6状态的HMM模型,高斯混合度选为14,得到图3的实验结果。

由图3可以看出,由于本系统实时学习的特点,系统的识别率随着训练数据的增加而逐步上升(误识率下降)。但是当实验数据继续增多时,系统的识别率和实时性都有下降趋势。这是由于系统处于无人监管状态,根据判断结果进行参数重估。如果判断结果错误,势必将错误带人参数重估步骤中。
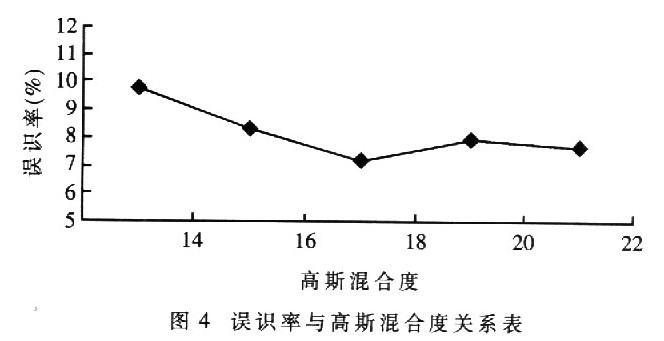
逐步增加高斯混合度数目,可以得到图4的实验结果。可见高斯混合度在18的时候达到较好的识别效果,混合度太高识别率反而会有所下降,这是由于嵌入式系统的资源有限,运算复杂度的增长超过了嵌入式设备的限制所造成的。
为了使微机器人能够正确地执行人的声音指令,本文将语音识别的过程嵌入微机器人的控制系统中,根据微机器人控制系统资源有限、对实时性要求高的特点,使用增量K均值分段HMM的算法,简化计算节省了所需的硬件资源,实现了实时学习的语音识别,能方便地对微机器人进行控制。
本系统的识别率达到了较高的标准,又由于加入了智能化的用户选择部分,用户可随时选择学习新的语句,使其有更广阔的应用前景。
由于嵌入式平台受到处理速度、存储空间的限制,所以能够对微机器人发出的指令十分有限,识别率还有待提高。因此,研究语音识别算法,比较各种算法的优缺点,进而在嵌入式微机器人控制系统上实现大词汇量非特定人的语音识别,实现真正意义上的人机交流是今后进一步的工作。
上一篇:以单片机为核心的温室智能控制系统
下一篇:基于LIN总线的车灯控制系统设计
推荐阅读最新更新时间:2024-03-30 21:23

 功率变换器和电气传动的预测控制
功率变换器和电气传动的预测控制 控制之美(卷1)——控制理论从传递函数到状态空间
控制之美(卷1)——控制理论从传递函数到状态空间





- Allegro MicroSystems 在 2024 年德国慕尼黑电子展上推出先进的磁性和电感式位置感测解决方案
- 左手车钥匙,右手活体检测雷达,UWB上车势在必行!
- 狂飙十年,国产CIS挤上牌桌
- 神盾短刀电池+雷神EM-i超级电混,吉利新能源甩出了两张“王炸”
- 浅谈功能安全之故障(fault),错误(error),失效(failure)
- 智能汽车2.0周期,这几大核心产业链迎来重大机会!
- 美日研发新型电池,宁德时代面临挑战?中国新能源电池产业如何应对?
- Rambus推出业界首款HBM 4控制器IP:背后有哪些技术细节?
- 村田推出高精度汽车用6轴惯性传感器
- 福特获得预充电报警专利 有助于节约成本和应对紧急情况




 京公网安备 11010802033920号
京公网安备 11010802033920号