全彩LED显示显控制卡根据控制方式,可以分显两大显:同步控制卡和异步控制卡。
1.1 同步控制卡
全彩LED同步显示墙主要由PC,同步控制卡和LED显示模块组三部分组成,其连接方式如下:

图1 同步控制模块图
同步控制卡将DVI信号转成LED显示模组所需要的视频信号格式,而且用以太网的方式传输给LED显示模组。同步控制卡本身不做视频解码等处理,仅做格式转换。因此,一般采用FPGA实现该功能。
1.2 异步控制卡
全彩LED异步显示墙由异步控制卡和LED显示模组组成,其连接方式如下:

图2 异步控制卡模块图
由上图,异步控制卡主要由两个大的部分组成:
- 视频处理模块。
在此模块中,SOC从网口得到视频流以及UI的素材,进行视频解码和UI 绘制,最后通过LCD接口传送给 FPGA。
- 视频信号转换模块。
在此模块中,FPGA将视频信号转换成LED显示模组所需的信号,并通过网口输出,该功能和同步控制卡的 功能一样。
对比两种方案,可见异步控制卡具体有成本低,便于集中管理的特点。
2 异步控制卡系统分析
下面从硬件和软件两个方面分析其主芯片的系统需求。
2.1 硬件部分
从硬件上看,视频处理模块部分主要由最小系统和外围模块两大部分组成。
- 最小系统
- 最小系统由主芯片,电源系统,DDR和存储四部分组成。
- 不同级别的全彩屏对SOC的处理能力有不同要求,具体的要求在软件部分有说明。
- 外围模块
- 音频接口,LCD接口。即LED显示墙的基本需求。
- 网络接口。百兆甚至千兆网口可以有效保证显示内容更新的高效性。
- USB接口。便于系统升级,以及扩展基于USB各种外设。
- SD卡/TF卡支持。便于系统升级以及内容的本地更新。
此外,异步卡一般和LED显示墙一起放置于室外,所以需要可工作在宽温度范围的工业级芯片。
2.2 软件部分
软件部分主要由操作系统和应用软件两大部分组成。
2.2.1 操作系统
在异步控制卡行业中,主流系统选择了Linux。
2.2.2应用软件
应用软件主要包含三个部分:
- 多媒体部分。
用于对音视频码流的解码。
全彩屏主要分为高端和中低端两个档次:
- 高端,视频分辨率以及显示分辨率要求在720p分辨率以上。
- 中低端,视频分辨率以及显示分辨率在640x480以内。
由于LED墙一般显示物理面积大,而且亮度高,所以对视频流的帧率要求较高,要求在每秒25帧以上。因此,对于高端产品,一般需带有视频硬解码模块的主芯片,其价格一般较高;对于低端产品,使用软解码可实现,所以需要运算性能较强的主芯片,成本优势较好。
- UI 部分。
用于显示字幕,图片等,并处理UI 元素和视频层的叠加。叠加部分。由于涉及到透明度,尺寸变换等,运 算需求也很大,所以需要主芯片具有相关的硬件加速模块。
- 远程控制部分。
该部分主要实现上位机对各控制卡的远程控制,内容更新等功能。该部分一般通过网络应用层实现,各控 制厂家有自己的协议。
3 AM335x的解决方案
AM335x是TI新近推出的基于ARM Cortex-A8 的SOC,外设丰富,主要针对工业应用领域。针对异步控制卡应用,TI也提供了基于Linux的解决方案。下面将从硬件和软件两方面分别介绍该方案。
3.1 硬件方案
AM335x具有一个强劲的核心Cortex-A8,该核的运算能力可达2.0DMIPS/MHz, 而且AM335x的主频可到1GHz,即运算总的能力可达2000DMIPS,可流畅解码640x480的MPEG4视频流,而且有足够的运算余量绘制各种UI。
此外,AM335x还有一个3D图形加速核,SGX530,可支持OpenGL ES2.0。TI 在OpenGL ES2.0之上提供了相应的软件方案,将SGX530用于视频帧的尺寸缩放以及实现对UI 层和视频层的透明叠加的加速,后面软件部分会详细介绍该方案。
同时,AM335x具有丰富的外设,如下图所示:
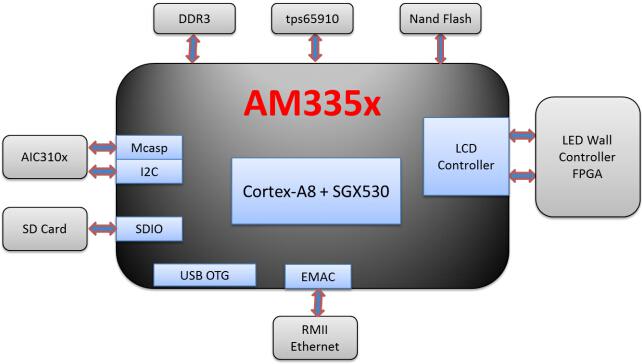
图3 AM335x异步控制卡硬件模块图
由上图可见AM335x可完全涵盖所有异步控制卡的外设需求,不需要其他扩展。因此,总体成本具有很强竞争力。
TI的开发板GP EVM(可查阅参考文档[1])都可以很便利的进行LED应用的评估和开发,下文中的软件方案是以GP EVM为平台进行开发的。[page]
3.2 软件方案
软件方案主要分为操作系统和应用软件两大块,具体介绍如下。
3.2.1 操作系统
如前所述,Linux是异步控制卡的主流操作系统,因此,本方案也选择了Linux作为平台。AM335x EZSDK提供了Linux的完整开发包,包括板级支持包,交叉编译器,文件系统等,可查阅参考文档[2]。
3.2.2 软件模块
- UI
在基于Linux的异步控制卡平台上,QT以免费,开源,开发资料全以及在嵌入式系统上运行效率高等特 点,已经成为异步控制卡厂商开发UI主要的平台。在EZSDK中已包含对QT4的移植,可查阅参考文档[3]。 QT在开源网站上也有很丰富的资源,可查阅参考文档[4]。
- 多媒体
在EZSDK中提供Gstreamer+ffmpeg的多媒体解决方案,可查阅参考文档[5]和参考Gstreamer文档(参考文档 [6])。在多媒体中,由于格式比较多,各种编码的复杂度以及编码质量差异较大是一个难点。而在LED显示 墙的应用场景中,多媒体码流可接受转码方式,所以可指定码流的格式。这里,推荐的多媒体格式 MP4(MPEG4+AAC),其中MPEG4选择simple profile,对此种码流,若分辨率为640x480,AM335x可流畅解 码每秒25帧以上。
- 显示后端
AM335x只有一个功能简单的LCD控制器,该控制器只支持RGB格式,其在Linux中的驱动为framebuffer,可 查阅参考文档[7] 。相应的上述两个模块的显示后端也以framebuffer为基础:
- Gstreamer的后端显示插件采用fbdevsink。由于视频解码后的格式为YUV格式,而AM335x自带的LCD控制器只支持RGB格式,因此此处可使用Gstreamer的插件ffmpegcolourspace进行色度空间的转换
- QT 默认以framebuffer为显示后端。
Framebuffer会接收来自QT和Gstreamer的图像帧数据,然后进行OSD的叠加和缩放等操作,数据流如下图所示:
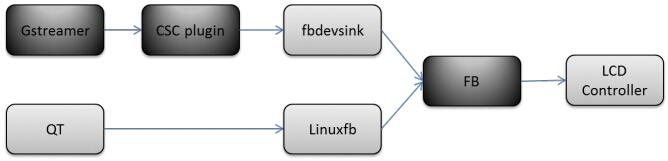
图4 默认软件方案数据流程图
3.2.3软件复杂度分析
在图4中,深色模块为运算较密集模块,具体分析如下:
- Gstreamer的解码和ffmpegcolourspace(CSC plugin)两个模块。ARM虽然有较强的运算能力,但对于较大分辨率的视频解码,视频解码的宏块运算等需较大运算量。另外,色度空间涉及浮点运算,而且为逐点运算,所以运算量需求也不小。以640x480分辨率的MP4(MPEG4 simple profile+AAC)为例,若帧率为30fps时,ARM核的loading在91%左右,其中ffmpegcolourspace模块约占运算量的50%。
- Framebuffer模块。在该模块中的OSD叠加指的是UI图层和视频图层之间的叠加,而且是包含带透明度的叠加,而图层的缩放是指对原图等比例的缩放,因而需对每一帧数据的每个像素点进行浮点乘加运算,参考ffmpegcolourspace的运算量,该部分运算量也应较大。可见,ARM核无法独自胜任系统所需的全部运算。
3.2.4 基于GPU的优化方案–GPU Composition
GPU Composition软件模块,调用SGX530模块进行色彩空间转换,OSD叠加,图层缩放功能,分担A8的运算负载使其专注于QT,视频解码等应用,下面将具体介绍。
- GPU Composition模块的编译和安装。在TI Wiki上有明确说明,可查阅参考文档[8]。
- GPU Composition设计分析
A.各功能模块
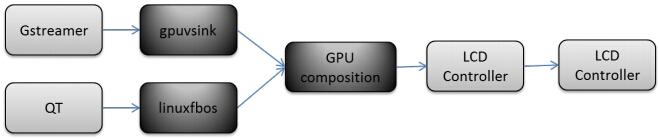
图5 GPU Composition软件模块图
SGX530实现的功能模块标记为深色,具体功能如下:
a. gpuvsink该模块设计为Gstreamer视频显示后端插件,将视频解码器解出的YUV 数据帧,传送给SGX530模块。按照标准的Gstreamer视频显示后端插件设计,可采用标准的显示后端接口编程。对于视频输入的尺寸,要求其宽(width)为4个像素点的倍数。其输出视频帧数据这里可称为Video Plane。
b. linuxfbofs该模块设计为QT架构中的显示后端,将QT的帧数据发送到SGX530模块中处理。linuxfbofs和framebuffer有同样的接口,对于QT应用开发是透明的。其输出界面帧数据为Graphics Plane。
GPU Composition
该模块基于Open GL ES 2.0接口设计,对输入的Video plane和Graphics Plane进行色彩空间转换,图层缩放,OSD叠加等操作,将最终的帧数据推送到Framebuffer中显示。
B. 模块间的数据流
模块间的数据以Plane的形式传递,具体介绍如下:
a. Plane格式
- Video Plane可支持YUV422,NV12,I420和YUV420 格式帧数据。
- Graphics Plane可支持RGB565,RGB888和ARGB8888帧数据。
- GPU Composition接收这些格式的帧数据,并将其转换为RGB格式,进行图层缩放,OSD叠加等操作。
b. Plane的内存分配
SGX530输入内存(Buffer),只支持物理地址连续的Buffer。因此,在gpuvsink和linuxfbofs中,使用cmem(具体可查阅参考文档[9])据此要求分配内存Pool来存储帧数据,需在Linux启动时通过命令行参数 ”mem=”配置预留给Kernel的内存,而剩下的内存即是给cmem所准备,用于分配物理连续的内存。
其大小的计算公式如下:
Pool size for Graphics Plane = width * height * Bytes Per Pixel
Pool size for Video Plane = video frame width * height * 2 (Bytes Per Pixel) * 8 (buffers)
对于一个Video Plane可能需要多个Buffer,其具体个数定义在
gpu-compositing/gpuvsink/src/gst_render_bridge.
#define PROP_DEF_QUEUE_SIZE 8
c. Pool传递
Graphics Plane和Video Plane以指针的形式将Pool传递给GPU Composition。
C. 模块间的控制流
a. 配置信息数据结构
对于Graphics Plane,通过命名管道“"/opt/gpu-
compositing/named_pipes/video_cfg_and_data_plane_X"”其配置信息在下面数据结构中

关于此配置信息中,比较重要的有如下几点:
- 对于QT而言,对入的对对参数来自Linux的FB对对,即对LCD屏的对示分辨率。
- 关于透明度(Alpha),Video plane在底部,因此,Graphics Plane决定Video Plane的可对度。Alpha 可分对:全局Alpha,整个Plane使用同一的一个Alpha对;以像素点(Pixel)对对位的Alpha, 即像素的数据格式对ARGB8888,可以在局部对置Alpha。
- 可以通对对置对出的对构体out_g对对对出Plane的对放。
对于Video Plane, 配置信息如下:

此配置结构体中的输入信息,会通过Gstreamer的标准接口,通过前级的Gstreamer Plugin进行配置。如前所述,输入视频帧的宽(width)的像素点数,需为4的倍数;对于输出信息,和Graphics Plane一样,可以通过配置输出数据结构out,实现缩放功能。[page]
b. 命名管道(named pipe)配置信息
上述配置信息,通过存放于文件系统中的命名管道,传递到GPU Composition模块。对于linuxfbofs,命名管道文件为/opt/gpu-compositing/named_pipes/gfx_cfg_plane_X。对于gpuvsink,命名管道文件为/opt/gpu-compositing/named_pipes/video_cfg_and_data_plane_X。
4 方案实验
笔者基于GPU Composition方案,在AM335x EVM板上,开发了Gstreamer和QT应用程序,以验证整个异步LED显示墙方案的性能。
4.1 代码及编译
代码分成两个应用:
- Gstreamer部分,可在参考文档[10]下载,为一个视频播放器,可循环播放MP4视频
- QT部分,可以在参考文档[11]下载,包括一个时钟和滚动字幕。
可以根据参考文档[8]进行编译。
4.2 代码运行
在AM335x EVM(AM3358 主频为720MHz)上,运行命令行如下:

这里播放的视频流为mp4格式,其包含有分辨率为640x480的MPEG4 simple profile码流以及AAC音频流。
运行效果图如下:
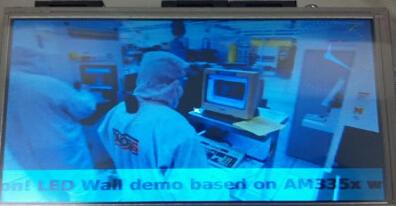
图6 示例运行效果图
可以从截图中看到,OSD层和视频层的透明度叠加很清楚。
4.3 性能分析
关于GPU Composition方案的性能提高,可以参考下面两个截图。
图7中,没有使用GPU Composition方案,CPU除了要做解码,也需要做色彩空间转换,其CPU占用率达到91%。
图8中,使用了GPU分担了视频叠加,色彩空间转换等运算,在整个系统的总运算量明显大于仅仅Gstreamer播放视频的情况下,ARM核的CPU占用率仅仅只有58%,仍给应用程序留下运行的空间。更多的示例可查阅参考文献[8]。
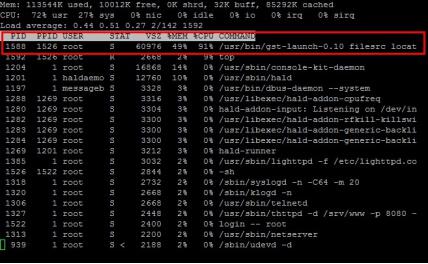
图7 单Cortex-A8软解视频流的系统负载

图8 GPU Composition方案视频播放的系统负载
5 总结
本文主要介绍了基于AM335x的全彩LED显示墙异步控制卡方案,重点介绍了基于GPU 的软件解决方案,在实现LED显示墙所需的视频层和OSD层叠加,缩放等功能的基础上,仍给客户定制的应用程序提供了足够的开发空间。希望该方案能加速客户进行异步控制卡的开发。
上一篇:Microchip发布全新GestIC®控制器
下一篇:基于高级图形控制器及视频处理技术的远程摄像头应用实例
推荐阅读最新更新时间:2024-03-16 13:54

 独辟蹊径品内核: Linux 内核源代码导读
独辟蹊径品内核: Linux 内核源代码导读
设计资源 培训 开发板 精华推荐
- 【下载】LAT1439 关于STM32H745的MC SDK电机控制工程问题的解决办法
- 【下载】LAT1444 ADC采样中的阻抗匹配计算方法
- 【下载】LAT1446 TrustZone应用中串口通信的DMA传输失败问题
- 【下载】LAT1450 不断电情况下修改RDP选项并生效的解决方案
- 【下载】LAT1455 分辨OEMiROT的Bash与BAT脚本
- 【下载】LAT1457 Keil工程使用NEAI库的异常问题












 京公网安备 11010802033920号
京公网安备 11010802033920号