看门狗分硬件看门狗和 软件看门狗。硬件看门狗是利用一个定时器电路,其定时输出连接到电路的复位端,程序在一定时间范围内对定时器清零(俗称“喂狗”),因此程序正常工作时, 定时器总不能溢出,也就不能产生复位信号。如果程序出现故障,不在定时周期内复位看门狗,就使得看门狗定时器溢出产生复位信号并重启系统。软件看门狗原理 上一样,只是将硬件电路上的定时器用处理器的内部定时器代替,这样可以简化硬件电路设计,但在可靠性方面不如硬件定时器,比如系统内部定时器自身发生故障 就无法检测到。当然也有通过双定时器相互监视,这不仅加大系统开销,也不能解决全部问题,比如中断系统故障导致定时器中断失效。
看门狗本身不是用来解决系统出现的问题,在调试过程中发现的故障应该要查改设计本身的错误。加入看门狗目的是对一些程序潜在错误和恶劣环 境干扰等因素导致系统死机而在无人干预情况下自动恢复系统正常工作状态。看门狗也不能完全避免故障造成的损失,毕竟从发现故障到系统复位恢复正常这段时间 内怠工。同时一些系统也需要复位前保护现场数据,重启后恢复现场数据,这可能也需要一笔软硬件的开销。
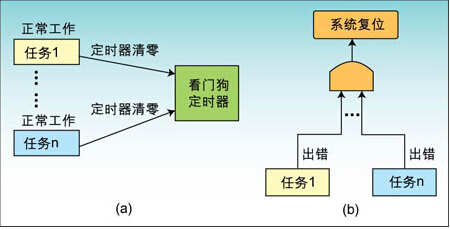
图1:(a) 多任务系统看门狗示意图;(b) 相应的看门狗复位逻辑图
在单任务系统中看门狗工作原理如上所述,容易实现。在多任务系统中情况稍为复杂。假如每个任务都像单任务系统那么做,如图1(a)所示,只要有一个 任务正常工作并定期“喂狗”,看门狗定时器就不会溢出。除非所有的任务都故障,才能使得看门狗定时器溢出而复位,如图1(b)。
而往往我们需要的是只要有一个任务故障,系统就要求复位。或者选择几个关键的任务接受监视,只要一个任务出问题系统就要求复位,如图2(a)所示,相应的看门狗复位逻辑如图2(b)所示。
在多任务系统中通过创建一个监视任务TaskMonitor,它的优先级高于被监视的任务群Task1、Task2...Taskn。 TaskMonitor在Task1~Taskn正常工作情况下,一定时间内对硬件看门狗定时器清零。如果被监视任务群有一个Task_x出现故 障,TaskMonitor就不对看门狗定时器清零,也就达到被监视任务出现故障时系统自动重启的目的。另外任务TaskMonitor自身出故障时,也 不能及时对看门狗定时器清零,看门狗也能自动复位重启。接下来需要解决一个问题是:监视任务如何有效监视被监视的任务群。

图2:(a) 多任务系统看门狗示意图;(b) 正确的看门狗复位逻辑图
在TaskMonitor中定义一组结构体来模拟看门狗定时器组,
typedef struct
{
UINT32 CurCnt, LastCnt;
BOOL RunState;
int taskID;
} STRUCT_WATCH_DOG;
该结构体包括被监视的任务号taskID,用来模拟“喂狗”的变量CurCnt、LastCnt(具体含义见下文),看门狗状态标志RunState用来控制当前任务是否接受监视。
被监视的任务Task1~Taskn调用自定义函数CreateWatchDog(int taskid)来创建看门狗,被监视任务一段时间内要求“喂狗”,调用ResetWatchDog(int taskid),这个“喂狗”动作实质就是对看门狗定时器结构体中的变量CurCnt加1操作。TaskMonitor大部分时间处于延时状态,假设硬件 看门狗定时是2秒,监视任务可以延时1.5秒,接着对创建的看门狗定时器组一一检验,延时前保存CurCnt的当前值到LastCnt,延时后比较 CurCnt与LastCnt是否相等,都不相等系统才是正常的。需要注意的是CurCnt和LastCnt数据字节数太小,而“喂狗”过于频繁,可能出 现CurCnt加1操作达到一个循环而与LastCnt相等。
如果有任意一组的CurCnt等于LastCnt,认为对应接受监视的任务没有“喂狗”动作,也就检测到该任务出现故障需要重启,这时候 TaskMonitor不对硬件看门狗定时器清零,或者延时很长的时间,比如10秒,足以使得系统重启。反之,系统正常,Task1~Taskn定期对 TaskMonitor“喂狗”,TaskMonitor又定期对硬件看门狗“喂狗”,系统就得不到复位。还有一点,被监视任务可以通过调用 PauseWatchDog(int taskid)来取消对应的看门狗,实际上就是对STRUCT_WATCH_DOG结构体中的RunState操作,该标志体现看门狗有效与否。
这种方式可监视的最大任务数由STRUCT_WATCH_DOG结构数据的个数决定。程序中应该有一个变量记录当前已创建的看门狗数,判断被监视任务Task1~Taskn是否“喂狗”只需比较CurCnt与LastCnt的值n次。
图3:系统复位逻辑图。
硬件看门狗监视TaskMonitor任务,TaskMonitor任务又监视其他的被监视任务Task1~Taskn,形成这样一种链条。这种方 式系统的故障图表示如图3所示。被监视任务Task1~Taskn及TaskMonitor都是或的关系,因此被监视的任一任务发生故障,硬件电路看门狗 就能复位。
为实现多任务系统的看门狗监视功能额外增加了TaskMonitor任务,这个任务占用执行时间多少也是一个重要问题。假设 TaskMonitor任务一个监视周期延时1.5秒,此外需要执行保存当前计数值,判断是否“喂狗”等语句,它的CPU占用时间是很小的。用一个具体的 试验证实,使用50M工作频率的CPU(S3C4510),移植vxWorks操作系统,cache不使能条件下监视10个任务,每个监视周期占用 220~240微秒。可见该任务绝大多数时间都处于任务延时状态。
被监视任务可能有获取消息、等待一个信号量等的语句,往往这个消息、信号量的等待是无限期的等待。这就需要将这类语句作一些修改。比如在vxWorks中将一次无期限的获取信号量操作
semTake(semID, WAIT_FOREVER); // WAIT_FOREVER为无限时间等待
分解为
do
{
ResetWatchDog; // “喂狗”操作
}while(semTake(semID, sysClkRateGet( )) != OK); // 1s内的等待信号量操作
多次的时间范围内的获取信号量操作,这样才能保证及时“喂狗”。
另外需要注意的是系统中是否有的任务优先级比TaskMonitor高并且长时间处于执行状态,TaskMonitor长时间得不到调度,使得看门狗错误复位。良好的任务划分,配置是不应该出现这种高优先级任务长期执行状况的。
上一篇:看门狗复位的应用技巧
下一篇:单片机IO口工作方式详细分析
推荐阅读最新更新时间:2024-03-16 16:17

 嵌入式C语言自我修养——从芯片、编译器到操作系统 带目录 文字版
嵌入式C语言自我修养——从芯片、编译器到操作系统 带目录 文字版 硬件架构艺术:数字电路的设计方法与技术
硬件架构艺术:数字电路的设计方法与技术
设计资源 培训 开发板 精华推荐
- 【下载】LAT1439 关于STM32H745的MC SDK电机控制工程问题的解决办法
- 【下载】LAT1444 ADC采样中的阻抗匹配计算方法
- 【下载】LAT1446 TrustZone应用中串口通信的DMA传输失败问题
- 【下载】LAT1450 不断电情况下修改RDP选项并生效的解决方案
- 【下载】LAT1455 分辨OEMiROT的Bash与BAT脚本
- 【下载】LAT1457 Keil工程使用NEAI库的异常问题












 京公网安备 11010802033920号
京公网安备 11010802033920号