摘要:根据一块32位嵌入式CPU的400MHz主频的要求,结合该CPU五级流水线结构,并借鉴各种算法成熟的加法器,提出了一种电路设计简单、速度快、功耗低、版图面积小的32位改进定点加法器的设计方案,为后续浮点加法器的设计提供了很好的铺垫。
关键词:借鉴 改进 定点 加法器
从CPU的指令执行频率上看,算术逻辑单元、程序计数器、协处理器是CPU中使用频率最多的模块,而加法器正是这些模块的核心部件,几乎所有的关键路径都与之有关,因而设计一种通用于这些模块的加法器是整个CPU设计中关键的一步。为此,笔者根据32位CPU的400MHz主频的要求,结合CPU流水线结构,借鉴各种算法成熟的加法器,提出一种电路设计简单、速度快、功耗低、版图面积小的32位改进定点加法器的设计方案。
1 设计思想
对于高性能CPU中使用的加法器,速度显然是第一位的,所以考虑采用并行计算的方法,并且在电路的设计上采用少量的器件来获得速度上的巨大提升。从面积有度出发,链式进位加法器(Ripple-Carry Adder)的器件最少,面积最小,版图工作量也最小,可是由于加法器的高位进位要等待低位的运算结束后才能得到,所以没有办法在速度上达到要求。鉴于此,采用类似于链式加法器的结构。
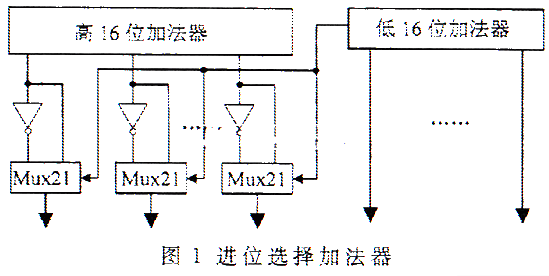 省先从进位选择加法器(Carry-Select Adder)得到提示,将32位加法器一分为二,分为低16位加法器和高16位加法器,再将低16位加法器的进位输出作为选择信号,用于选择高16位加法器的和及第27位的进位输出(这个进位输出要在溢出逻辑判断中使用,而普通的加法器则不用产生进位)。通过这样的处理,将一个32位的加法器简化就成了两上16位的加法器,如图1所示。
另外,从超前进位加法器(Carry-Look-Ahead Adder)获得提示,在超前进位加法器中引入中间变量G和P用于加速进位链的速度。而G和P在逻辑表达式上与前一级的进位无关,只与每一级的操作数输入有关,而且它们又是构成本级进位的必要部分。在微处理器的数据通道上,数据传输是并行进行的,即两个32位操作数几乎同一时间到达时加法器。所以,G和P不论是加法器的最低位还是加法器的最高位,几乎都可以在相同的时间内得到,因而进位链上就可以借鉴这个特点加速进位的传递。以一个四位加法器为例,有如下的逻辑推导过程:
C4=C3P4+G4=(C2P3+G3)%26;#183;P4=G4=C2P3P4+G3P4+G4=(C1P2+G2) %26;#183;P3%26;#183;P4+G3P4+G4=C1P2P3P4+G2P3P4+G3P4=(C0P1+G1) %26;#183;(P2P3P4)+(G2P3P4+G3P4+G4)=C0%26;#183;(P1P2P3P4)+(G1P2P3P4+G2P3P4+G3P4+G4)
令上式中P1P2P3P4为Pgroup,G1P2P3P4+G2P3P4+G3P4+G4为Ggroup,如果将32位加法器划分为若干的小块,则每一个小块都可以有自己相对应的Ggroup和Pgroup。由此可知对于整个加法器的时延来说,关键路径的时延总值可以由三部分组成:①产生Ggroup和Pgroup的时延;②进位传递逻辑上的器件时延;③加法器进位链上的导线时延。对于这三类时延,时延①与时延(②+③)存在重叠的部分,于是使这两类时延合理衔接,可以使得进位链上的逻辑级数最小,从而使得电路上的传输时延达到最小上。
图2
2 具体实现
2.1 4位加法器模块的实现
在具体的电路设计中,先将32位数据通道划分成了高低两部分,然后以4位为单位划分成更小的模块。这些模块在结构上是基本一致的,但在功能上要完成本模块四组操作数(A[k:k+3]和B[k:k+3])与进位Ck的加法运算,并要产生模块的中间变量Ggroup和Pgroup的运算。
对于单一的每一位,定义它的G和P分别为:Gi=AiBi,Pi=Ai+Bi,加法器的和SUMi=Ai+Bi+Ci-1=Pi+Ci-1,考虑到器件的实际驱动能力,结合加法器的另一个功能——减法运算,设计出如图2所示的带减法功能的一位加法器电路。
设计的4位加法器进位链如图3所示,除C0外,输入(Pi和Gi)都是由图2的一位加法器产生的,所有4位进位链Ci都按超前进位加法器连接方式直接接入相应位置。由此可以看出,进位信号到达各位的逻辑级数是相当的,只要在进位信号到达之间使所有的中间信号Gi和Pi都能及时产生,就能及时得到每一位的和(SUM)。
图3
图4是产生4位加法器块进位及块的Ggroup和Pgroup信号的电路。借鉴于超前进位加法器的传递逻辑电路,可知并不是所有的4位加法器都需要向它的下一个模块传送进位信号,而只要产生传递进位所需的Ggroup和Pgroup信号即可。而有些位置,由于进位链设计的实际需要,要需要利用4位加法器模块产生的进位信号,而不必采用传递逻辑产生的进位信号,而不必采用传递逻辑产生的进位信号,具体的情况还是有区别的。为了充分利用图3中产生的相关信号的复位,在进位信号C4的产生电路部分,进位链方向上的逻辑级数只有两组,可以说还是比较简单了。可是,综合前面所谈到的4位加法器的电路,可以发现有一些中间信号(Pi和Gi)的负载是不均衡的,如P2的负载比P3或P4要重很多。所以在设计的时候,如果考虑到尽量降低版图的复杂程度,就要在面积上做出适当的牺牲,尽量以最大负载进行考虑,使得器件的设计符合时延上的要求;同时还要充分考虑到在深亚微米工艺条件下导线的时延问题,即设计的电路不但要考虑到所承受的器件的负载,而且还要结合版图设计中实现的导线负载,定出上述电路的合理尺寸。
2.2 传递逻辑电路实现
完成上述基本4位加法器的电路设计后,要构造一个完整的32位加法器还需借助于传递逻辑电路。传递逻辑电路要吧对4位加法器模块的进位进行传递,也可以对由两个4位加法器模块组成的8位加法器模块的进位进行传递。对于8位加法器模块,由于低4位的进行可以表示为C4=C0Ggroup+Pgroup,则8位加法器模块的进位为:
C8=C4Ggroup"+Pgroup"=Pgroup"(C0Ggroup+Pgroup)+Ggroup
=Pgroup"PgroupC0+Pgroup"Ggroup+Ggroup"
由此可以设计如图5和图6所示的两种进位传递逻辑电路。
图4
2.3 溢出逻辑电路实现
设计中还采用了判断溢出的方法。当两个有符号数进行加减法运算时,若最高的数值位符号位的进位(本设计中的C30)值与符号位产生的进位(本设计中的C31)输出值不同,则表明加减运算产生了溢出。
由上述可知,加法器时延的关键路径在进位链上,而进行溢出判断所需要的信息C30与C31都在这条路径上。于是采用类似于进位跳加法器(Carry-Skip Adder)的方法,使得低位的进位快速跳位到高位,使C30与C31快速产生,具体实现如下:
①溢出的逻辑表达式推导
由于Joverflow=(C30+C31)%26;#183;Overflag(Overflag)表示当前ALU加法器进行有符号运算),需要进行溢出判断(它是ALU控制模块在译码阶段产生的,在指令执行阶段起始段就输出到数据通道,所以它不在关键路径上)。
图5、6
对于C31与C30,有C31=C30P31+G31,所以
C30+C31=C30C31+C30C31
=(C27G28G29G30G31+C27P28P29P30P31G31) (1)
+(P28G28G29G30G31+G28P29P30P31G31)+P29G29G30G31+P30G30G31+G29P30P31G31+G30P31G31 (2)
显然,分式(1)是和进位链无关的一部分,可以在每一个流水线的指令执行阶段起始段很快得到,而分式(2)则是和进位链有关的部分,其具体逻辑值将取决于进位G27的值。分式(1)中高位的Gi和Pi都可以在进位C27到来之间预先得到,只要C27一到就可以进行逻辑判断,得到相应的逻辑。
所以令P1=G28G29G30G31+C27P28P29P30P31G31
P2=P28P29P30P31G31
Gtotal=式(2)
则 Overflow=(C30+C31)%26;#183;Overflag=(C27P1+C27P2+Gtotal) %26;#183;Overflag (3)
省先从进位选择加法器(Carry-Select Adder)得到提示,将32位加法器一分为二,分为低16位加法器和高16位加法器,再将低16位加法器的进位输出作为选择信号,用于选择高16位加法器的和及第27位的进位输出(这个进位输出要在溢出逻辑判断中使用,而普通的加法器则不用产生进位)。通过这样的处理,将一个32位的加法器简化就成了两上16位的加法器,如图1所示。
另外,从超前进位加法器(Carry-Look-Ahead Adder)获得提示,在超前进位加法器中引入中间变量G和P用于加速进位链的速度。而G和P在逻辑表达式上与前一级的进位无关,只与每一级的操作数输入有关,而且它们又是构成本级进位的必要部分。在微处理器的数据通道上,数据传输是并行进行的,即两个32位操作数几乎同一时间到达时加法器。所以,G和P不论是加法器的最低位还是加法器的最高位,几乎都可以在相同的时间内得到,因而进位链上就可以借鉴这个特点加速进位的传递。以一个四位加法器为例,有如下的逻辑推导过程:
C4=C3P4+G4=(C2P3+G3)%26;#183;P4=G4=C2P3P4+G3P4+G4=(C1P2+G2) %26;#183;P3%26;#183;P4+G3P4+G4=C1P2P3P4+G2P3P4+G3P4=(C0P1+G1) %26;#183;(P2P3P4)+(G2P3P4+G3P4+G4)=C0%26;#183;(P1P2P3P4)+(G1P2P3P4+G2P3P4+G3P4+G4)
令上式中P1P2P3P4为Pgroup,G1P2P3P4+G2P3P4+G3P4+G4为Ggroup,如果将32位加法器划分为若干的小块,则每一个小块都可以有自己相对应的Ggroup和Pgroup。由此可知对于整个加法器的时延来说,关键路径的时延总值可以由三部分组成:①产生Ggroup和Pgroup的时延;②进位传递逻辑上的器件时延;③加法器进位链上的导线时延。对于这三类时延,时延①与时延(②+③)存在重叠的部分,于是使这两类时延合理衔接,可以使得进位链上的逻辑级数最小,从而使得电路上的传输时延达到最小上。
图2
2 具体实现
2.1 4位加法器模块的实现
在具体的电路设计中,先将32位数据通道划分成了高低两部分,然后以4位为单位划分成更小的模块。这些模块在结构上是基本一致的,但在功能上要完成本模块四组操作数(A[k:k+3]和B[k:k+3])与进位Ck的加法运算,并要产生模块的中间变量Ggroup和Pgroup的运算。
对于单一的每一位,定义它的G和P分别为:Gi=AiBi,Pi=Ai+Bi,加法器的和SUMi=Ai+Bi+Ci-1=Pi+Ci-1,考虑到器件的实际驱动能力,结合加法器的另一个功能——减法运算,设计出如图2所示的带减法功能的一位加法器电路。
设计的4位加法器进位链如图3所示,除C0外,输入(Pi和Gi)都是由图2的一位加法器产生的,所有4位进位链Ci都按超前进位加法器连接方式直接接入相应位置。由此可以看出,进位信号到达各位的逻辑级数是相当的,只要在进位信号到达之间使所有的中间信号Gi和Pi都能及时产生,就能及时得到每一位的和(SUM)。
图3
图4是产生4位加法器块进位及块的Ggroup和Pgroup信号的电路。借鉴于超前进位加法器的传递逻辑电路,可知并不是所有的4位加法器都需要向它的下一个模块传送进位信号,而只要产生传递进位所需的Ggroup和Pgroup信号即可。而有些位置,由于进位链设计的实际需要,要需要利用4位加法器模块产生的进位信号,而不必采用传递逻辑产生的进位信号,而不必采用传递逻辑产生的进位信号,具体的情况还是有区别的。为了充分利用图3中产生的相关信号的复位,在进位信号C4的产生电路部分,进位链方向上的逻辑级数只有两组,可以说还是比较简单了。可是,综合前面所谈到的4位加法器的电路,可以发现有一些中间信号(Pi和Gi)的负载是不均衡的,如P2的负载比P3或P4要重很多。所以在设计的时候,如果考虑到尽量降低版图的复杂程度,就要在面积上做出适当的牺牲,尽量以最大负载进行考虑,使得器件的设计符合时延上的要求;同时还要充分考虑到在深亚微米工艺条件下导线的时延问题,即设计的电路不但要考虑到所承受的器件的负载,而且还要结合版图设计中实现的导线负载,定出上述电路的合理尺寸。
2.2 传递逻辑电路实现
完成上述基本4位加法器的电路设计后,要构造一个完整的32位加法器还需借助于传递逻辑电路。传递逻辑电路要吧对4位加法器模块的进位进行传递,也可以对由两个4位加法器模块组成的8位加法器模块的进位进行传递。对于8位加法器模块,由于低4位的进行可以表示为C4=C0Ggroup+Pgroup,则8位加法器模块的进位为:
C8=C4Ggroup"+Pgroup"=Pgroup"(C0Ggroup+Pgroup)+Ggroup
=Pgroup"PgroupC0+Pgroup"Ggroup+Ggroup"
由此可以设计如图5和图6所示的两种进位传递逻辑电路。
图4
2.3 溢出逻辑电路实现
设计中还采用了判断溢出的方法。当两个有符号数进行加减法运算时,若最高的数值位符号位的进位(本设计中的C30)值与符号位产生的进位(本设计中的C31)输出值不同,则表明加减运算产生了溢出。
由上述可知,加法器时延的关键路径在进位链上,而进行溢出判断所需要的信息C30与C31都在这条路径上。于是采用类似于进位跳加法器(Carry-Skip Adder)的方法,使得低位的进位快速跳位到高位,使C30与C31快速产生,具体实现如下:
①溢出的逻辑表达式推导
由于Joverflow=(C30+C31)%26;#183;Overflag(Overflag)表示当前ALU加法器进行有符号运算),需要进行溢出判断(它是ALU控制模块在译码阶段产生的,在指令执行阶段起始段就输出到数据通道,所以它不在关键路径上)。
图5、6
对于C31与C30,有C31=C30P31+G31,所以
C30+C31=C30C31+C30C31
=(C27G28G29G30G31+C27P28P29P30P31G31) (1)
+(P28G28G29G30G31+G28P29P30P31G31)+P29G29G30G31+P30G30G31+G29P30P31G31+G30P31G31 (2)
显然,分式(1)是和进位链无关的一部分,可以在每一个流水线的指令执行阶段起始段很快得到,而分式(2)则是和进位链有关的部分,其具体逻辑值将取决于进位G27的值。分式(1)中高位的Gi和Pi都可以在进位C27到来之间预先得到,只要C27一到就可以进行逻辑判断,得到相应的逻辑。
所以令P1=G28G29G30G31+C27P28P29P30P31G31
P2=P28P29P30P31G31
Gtotal=式(2)
则 Overflow=(C30+C31)%26;#183;Overflag=(C27P1+C27P2+Gtotal) %26;#183;Overflag (3)
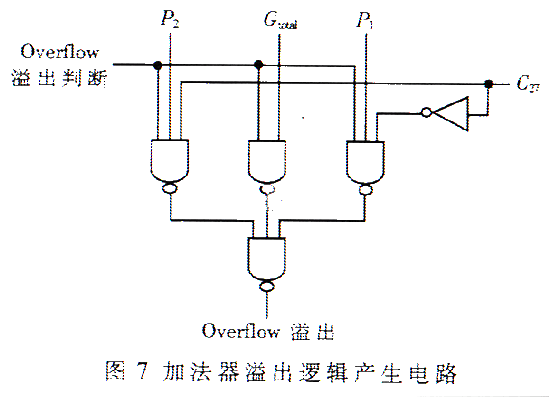 ②溢出逻辑电路实现
根据式(3)的逻辑表达式,可设计出加法器溢出逻辑产生电路,如图7所示。
设计得到的32位加法器在SMIC流片后,经测试,运算速度在400MHz以上,满足设计要求,为后续浮点加法器的设计提供了很好的铺垫。
②溢出逻辑电路实现
根据式(3)的逻辑表达式,可设计出加法器溢出逻辑产生电路,如图7所示。
设计得到的32位加法器在SMIC流片后,经测试,运算速度在400MHz以上,满足设计要求,为后续浮点加法器的设计提供了很好的铺垫。
引用地址:一款32位嵌入式CPU的定点加法器设计
省先从进位选择加法器(Carry-Select Adder)得到提示,将32位加法器一分为二,分为低16位加法器和高16位加法器,再将低16位加法器的进位输出作为选择信号,用于选择高16位加法器的和及第27位的进位输出(这个进位输出要在溢出逻辑判断中使用,而普通的加法器则不用产生进位)。通过这样的处理,将一个32位的加法器简化就成了两上16位的加法器,如图1所示。
另外,从超前进位加法器(Carry-Look-Ahead Adder)获得提示,在超前进位加法器中引入中间变量G和P用于加速进位链的速度。而G和P在逻辑表达式上与前一级的进位无关,只与每一级的操作数输入有关,而且它们又是构成本级进位的必要部分。在微处理器的数据通道上,数据传输是并行进行的,即两个32位操作数几乎同一时间到达时加法器。所以,G和P不论是加法器的最低位还是加法器的最高位,几乎都可以在相同的时间内得到,因而进位链上就可以借鉴这个特点加速进位的传递。以一个四位加法器为例,有如下的逻辑推导过程:
C4=C3P4+G4=(C2P3+G3)%26;#183;P4=G4=C2P3P4+G3P4+G4=(C1P2+G2) %26;#183;P3%26;#183;P4+G3P4+G4=C1P2P3P4+G2P3P4+G3P4=(C0P1+G1) %26;#183;(P2P3P4)+(G2P3P4+G3P4+G4)=C0%26;#183;(P1P2P3P4)+(G1P2P3P4+G2P3P4+G3P4+G4)
令上式中P1P2P3P4为Pgroup,G1P2P3P4+G2P3P4+G3P4+G4为Ggroup,如果将32位加法器划分为若干的小块,则每一个小块都可以有自己相对应的Ggroup和Pgroup。由此可知对于整个加法器的时延来说,关键路径的时延总值可以由三部分组成:①产生Ggroup和Pgroup的时延;②进位传递逻辑上的器件时延;③加法器进位链上的导线时延。对于这三类时延,时延①与时延(②+③)存在重叠的部分,于是使这两类时延合理衔接,可以使得进位链上的逻辑级数最小,从而使得电路上的传输时延达到最小上。
图2
2 具体实现
2.1 4位加法器模块的实现
在具体的电路设计中,先将32位数据通道划分成了高低两部分,然后以4位为单位划分成更小的模块。这些模块在结构上是基本一致的,但在功能上要完成本模块四组操作数(A[k:k+3]和B[k:k+3])与进位Ck的加法运算,并要产生模块的中间变量Ggroup和Pgroup的运算。
对于单一的每一位,定义它的G和P分别为:Gi=AiBi,Pi=Ai+Bi,加法器的和SUMi=Ai+Bi+Ci-1=Pi+Ci-1,考虑到器件的实际驱动能力,结合加法器的另一个功能——减法运算,设计出如图2所示的带减法功能的一位加法器电路。
设计的4位加法器进位链如图3所示,除C0外,输入(Pi和Gi)都是由图2的一位加法器产生的,所有4位进位链Ci都按超前进位加法器连接方式直接接入相应位置。由此可以看出,进位信号到达各位的逻辑级数是相当的,只要在进位信号到达之间使所有的中间信号Gi和Pi都能及时产生,就能及时得到每一位的和(SUM)。
图3
图4是产生4位加法器块进位及块的Ggroup和Pgroup信号的电路。借鉴于超前进位加法器的传递逻辑电路,可知并不是所有的4位加法器都需要向它的下一个模块传送进位信号,而只要产生传递进位所需的Ggroup和Pgroup信号即可。而有些位置,由于进位链设计的实际需要,要需要利用4位加法器模块产生的进位信号,而不必采用传递逻辑产生的进位信号,而不必采用传递逻辑产生的进位信号,具体的情况还是有区别的。为了充分利用图3中产生的相关信号的复位,在进位信号C4的产生电路部分,进位链方向上的逻辑级数只有两组,可以说还是比较简单了。可是,综合前面所谈到的4位加法器的电路,可以发现有一些中间信号(Pi和Gi)的负载是不均衡的,如P2的负载比P3或P4要重很多。所以在设计的时候,如果考虑到尽量降低版图的复杂程度,就要在面积上做出适当的牺牲,尽量以最大负载进行考虑,使得器件的设计符合时延上的要求;同时还要充分考虑到在深亚微米工艺条件下导线的时延问题,即设计的电路不但要考虑到所承受的器件的负载,而且还要结合版图设计中实现的导线负载,定出上述电路的合理尺寸。
2.2 传递逻辑电路实现
完成上述基本4位加法器的电路设计后,要构造一个完整的32位加法器还需借助于传递逻辑电路。传递逻辑电路要吧对4位加法器模块的进位进行传递,也可以对由两个4位加法器模块组成的8位加法器模块的进位进行传递。对于8位加法器模块,由于低4位的进行可以表示为C4=C0Ggroup+Pgroup,则8位加法器模块的进位为:
C8=C4Ggroup"+Pgroup"=Pgroup"(C0Ggroup+Pgroup)+Ggroup
=Pgroup"PgroupC0+Pgroup"Ggroup+Ggroup"
由此可以设计如图5和图6所示的两种进位传递逻辑电路。
图4
2.3 溢出逻辑电路实现
设计中还采用了判断溢出的方法。当两个有符号数进行加减法运算时,若最高的数值位符号位的进位(本设计中的C30)值与符号位产生的进位(本设计中的C31)输出值不同,则表明加减运算产生了溢出。
由上述可知,加法器时延的关键路径在进位链上,而进行溢出判断所需要的信息C30与C31都在这条路径上。于是采用类似于进位跳加法器(Carry-Skip Adder)的方法,使得低位的进位快速跳位到高位,使C30与C31快速产生,具体实现如下:
①溢出的逻辑表达式推导
由于Joverflow=(C30+C31)%26;#183;Overflag(Overflag)表示当前ALU加法器进行有符号运算),需要进行溢出判断(它是ALU控制模块在译码阶段产生的,在指令执行阶段起始段就输出到数据通道,所以它不在关键路径上)。
图5、6
对于C31与C30,有C31=C30P31+G31,所以
C30+C31=C30C31+C30C31
=(C27G28G29G30G31+C27P28P29P30P31G31) (1)
+(P28G28G29G30G31+G28P29P30P31G31)+P29G29G30G31+P30G30G31+G29P30P31G31+G30P31G31 (2)
显然,分式(1)是和进位链无关的一部分,可以在每一个流水线的指令执行阶段起始段很快得到,而分式(2)则是和进位链有关的部分,其具体逻辑值将取决于进位G27的值。分式(1)中高位的Gi和Pi都可以在进位C27到来之间预先得到,只要C27一到就可以进行逻辑判断,得到相应的逻辑。
所以令P1=G28G29G30G31+C27P28P29P30P31G31
P2=P28P29P30P31G31
Gtotal=式(2)
则 Overflow=(C30+C31)%26;#183;Overflag=(C27P1+C27P2+Gtotal) %26;#183;Overflag (3)
②溢出逻辑电路实现
根据式(3)的逻辑表达式,可设计出加法器溢出逻辑产生电路,如图7所示。
设计得到的32位加法器在SMIC流片后,经测试,运算速度在400MHz以上,满足设计要求,为后续浮点加法器的设计提供了很好的铺垫。
上一篇:基于8051软核的SOPC系统设计与实现
下一篇:x86构架的SoC及STPC的一种应用
- 热门资源推荐
- 热门放大器推荐
 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用 TC52N3933ECTRT
TC52N3933ECTRT
小广播
热门活动
换一批
更多

最新嵌入式文章

更多精选电路图






更多热门文章
更多每日新闻
- 宁德时代巧克力换电生态大会将举行,什么是“巧克力换电”?1.5分钟换电能实现吗?
- 新型生物材料与高端医疗器械广东研究院、远诺技术转移中心加入面向初创企业的 MathWorks
- S5PV210 Linux字符驱动之PWM蜂鸣器驱动
- 尼得科机床新增可实现高效加工的高速主轴产品线
- Gartner发布2025年影响基础设施和运营的重要趋势
- 智谱清言英特尔酷睿Ultra专享版发布,离线模型玩转AIPC
- Bourns推出全新高效能、超紧凑型气体放电管 (GDT) 浪涌保护解决方案
- S5PV210之UBOOT-2011.06启动过程解析
- 六个理由告诉您为什么应该将模拟无线麦克风更换为数字无线麦克风
- S5PV210启动过程分析
更多往期活动
厂商技术中心




 京公网安备 11010802033920号
京公网安备 11010802033920号