引言
运动估计是视频压缩的关键,能进一步减小图像的冗余度,提高编码压缩效率。运动估计就是在帧间预测时设法找到当前帧的像素(或图像块)是从上一帧图像的什么位置移动过来的,以该位置上的像素(或图像块)作为预测依据,以此提高预测的准确性。由于H.264中的运动估计采用了一系列新技术,如七种块尺寸(将一个宏块分割成16×16、16×8、8×16、8×8、8×4、4×8、4×4七种类型的子块进行运动估计)、1/4像素精度运动补偿技术和多参考帧技术等,在使压缩效率至少提高两倍的同时,计算量也大大增加。实验结果表明,运动估计占H.264编码器的60%~80%的时间。H.264中的运动估计由整数运动估计和分数运动估计两部分组成。由于不论是自然视频图像序列或是合成视频图像序列,实际对象的运动精度都是任意小的,所以引入分数运动估计能非常准确地描述对象的运动轨迹,能更进一步去除视频图像序列的时间冗余,其精度达到了1/8像素精度。分像素的运动矢量如图1所示。
图1 分像素运动矢量
一般在实际应用中,运动估计普遍采用分级搜索算法:首先在搜索区内找到最佳整像素运动矢量,再在整像素最佳匹配点下寻找最佳1/2匹配点,得到半像素精度的运动矢量,接着在该半像素精度最佳匹配点周围进行1/4像素点搜索,得到1/4像素精度最佳匹配点以及相应的运动矢量。由于分像素运动估计运算量大,很多学者对分像素运动估计从算法上进行优化,提出了很多快速搜索算法,减少搜索点数目以达到降低运算复杂度的目的。本文就是基于这个目的,在块匹配算法的基础上,提出了一种1/4像素精度的亚像素运动估计的硬件实现方法。在整像素运动估计的基础上用10×10整像素阵列实现半像素精度和1/4像素精度的最佳匹配点搜索,在空间上具有更高的并行度,硬件实现简洁有效。
FME的运动矢量
帧间编码宏块中的每个块或亚宏块分割区域都是根据参考帧中同尺寸的区域预测得到的,它们之间的关系用运动矢量来表示。H.264对亮度成分和色度成分进行亚像素搜索时,两者之间的运动矢量是有差异的,对亮度成分采用1/4像素精度,色度成分采用1/8像素精度。如图2所示,大写字母代表整像素点,小写字母代表1/2像素点。

图2 亮度半像素内插
假定点H是在整像素运动估计中找到的最佳匹配点,在此基础上再进行1/2像素点的搜索,如点(bb,aa等),如果MV的垂直和水平分量为整数,参考块相应像素实际存在;如果其中一个或两个为分数,则参考块相应的亮度和色度像素并不存在,需利用邻近已编码点进行内插而得。
内插像素生成的步骤如下:
首先生成参考图象亮度成分的半像素点。半像素点(如b、h、m)通过对相应整像素点进行6抽头滤波得出,权重为(1/32、-5/32、5/8、5/8、-5/32、1/32)。b通过下式计算得出:
b=round((E-5F=20G+20H-5I+J)/32) (1)
类似的,h由A、C、G、M、R、T滤波得出。一旦邻近(垂直或水平方向)整像素点的所有像素都计算出来,剩余的半像素点便可通过对6个垂直或水平方向的半像素点滤波得到。例如,j由cc、dd、h、m、ee、ff滤波得出。
半像素点计算出来后,在此基础上,1/4像素点可通过线性内插得出,如图3所示。

图3 亮度1/4像素内插
1/4像素点(如a、c、i、k、d、f、n、q)由邻近像素内插而得,如
a=round((G+b)/2) (2)
剩余1/4像素点(p,r)由一对对角半像素点线性内插得出,如e由b和h获得。相应地,对于色度成分的1/8像素精度的运动矢量,也同样通过整像素点线性内插得出,如图4所示。
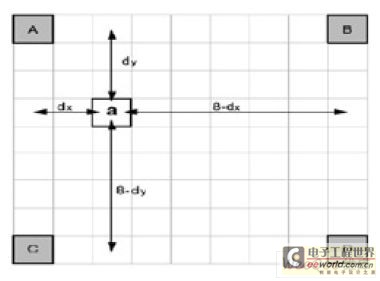
图4 色度1/8像素内插
其中:
a=round([(8-dx)(8-dy)A+dx(8-dy)B+(8-dx)dyC+dx dyD]/64) (3)
FME模块算法原理及硬件实现
在本设计中,FME搜索采用的是如图5所示的菱形全搜索方法。

图5 菱形全搜索
[page]
即先利用整像素运动估计搜索出最佳整像素点,再在最佳整像素匹配点的基础上搜索出最佳整像素点周围的36个亚像素点(假设在图5中正中心点是最佳整像素匹配点)。等36个亚像素点都计算出来后,加上正中心的最佳整像素点共37个像素点。比较这37个像素点的SATD的值,将SATD值最小的像素点确定为最佳的预测点。
由于H.264采用树形结构运动估计,每个宏块可划分成更小的子块,其中4×4块是宏块划分中最小的子块,任何类型的子块都可由若干个具有相同运动矢量的4×4块组成,因此本设计在硬件实现时将4×4块作为处理的基本单位。考虑到硬件资源的节省及计算的并行度,在本设计模块中每次能并行处理两个4×4块的亚像素点的搜索,一个宏块(16×16)要分8次完成,处理单元的硬件结构框图如图6所示。

图6 FME硬件框图
其中IME单元为FME单元提供10×10整像素点阵列,内插法用于1/2像素点的插值,ave单元用于计算1/4像素精度的像素点,Sram单元用于存储计算出来的亚像素点的值。比较器单元由diff、DCT、satd三个单元组成,用于比较这些亚像素的SATD值,确定最佳的亚像素预测值。
假设当前处理的4×4块在参考帧中的最佳整像素匹配块如图7所示(方框中的4×4块为匹配的块),在硬件实现的过程中为减少搜索次数,只要搜索出图7中对应的5×5块的每个整像素点左上角的15个亚像素点(见图8),然后将相邻整像素点左上角的亚像素点进行组合后就能将当前处理的4×4块中每个整像素点周围的36个亚像素点(见图5)都计算出来。

图7 最佳整像素匹配块

图8 亚像素点
本设计在硬件实现的过程中为提高计算的并行度,利用15个六抽头滤波器,25个均值器等硬件资源来计算图8所示的亚像素点的值,计算依据分别如公式1、2所示,硬件搜索计算过程如图9所示。

图9 亚像素点硬件搜索步骤
通过上述15个步骤就可将图8所示的亚像素点全部计算出来,并将计算出来的亚像素点的值都存入到开辟的Sram中,以便在进行P帧重构时从Sram中直接取出最佳的预测值给相关的模块。由于如上文所述在对每个4×4块进行亚像素搜索时要计算出对应的5×5块(如图7所示4×4块对应的5×5块)的每个整像素点左上角的15个亚像素点的值(如图8所示的15个亚像素点),加上最佳整像素点共16个像素点的值都要存储起来,且对应的5×5块中的每个整像素点左上角的亚像素点的像素值都是并行计算出来的(如step1计算点2,是将对应的5×5块的25个整像素点左上角对应的点2一次全计算出来),所以在进行一个4×4块的亚像素搜索时,要存储的像素点共有25×16个。由于在本设计模块中每次能并行处理两个4×4块单元,即利用两套FME模块资源并行处理两个4×4块的亚像素搜索,一个宏块(16×16)要分8次完成。考虑到数据组织的方便性,本设计在一套FME模块中开辟两块Sram资源,一块大小为104×128,一个地址存储13个像素点的值(每个像素点的值占8bit),另一块大小为96×128,一个地址能存储12个像素点的值(每个像素点的值占8bit),地址深度128刚好能存储8个4×4块的亚像素点的像素值,所以两套FME模块中的Sram资源刚好能把一个宏块的亚像素点的像素值都存储起来。此设计在硬件的实现过程中计算并行度高,硬件实现简洁有效。
根据图6所示的硬件架构及上文描述的算法原理,利用Verilog HDL对其进行建模,建立测试平台在ModelSim环境中进行编译、仿真,验证其功能的准确性。然后使用Synplify工具对其进行综合,工作频率可达68MHz。在FPGA 验证平台上,可实现对高清码流(1920×1080)的编码,利用Design Complier工具进行综合,在中芯国际0.18μm 工艺标准单元库的基础上,综合后面积占150千门,工作时钟频率可达166MHz,达到了预期要求。
结语
H.264中的分数运动估计能有效提高预测精度,但大大增加了计算复杂度。同整数运动估计一样,分数运动估计存在两个主要问题,一是计算量大,二是存储访问量大。而本文提出的用于H.264/AVC的分像素运动估计的硬件实现方法能在全搜索块匹配算法的基础上,采用子块分解,利用10×10整像素点阵列实现1/2像素精度和1/4像素精度的最佳匹配点的并行搜索,与其他实现方法相比在空间上具有更高的并行度,处理能力更高,不但减少了大量中间数据的存储与传输,节省了存储器资源,而且简化了数据流和控制流,使硬件实现简洁有效,非常适合高分辨率视频的分像素运动估计。
上一篇:彩电企业上书炮轰广电总局垄断互联网电视
下一篇:英特尔CTO:将推出更多电视芯片的产品
推荐阅读最新更新时间:2024-05-03 19:25
 深度学习核心技术与实践 (猿辅导研究团队)
深度学习核心技术与实践 (猿辅导研究团队) Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用










 京公网安备 11010802033920号
京公网安备 11010802033920号