PRMA多址接入协议就是一种以时分多址为基础,结合话音的统计模型有效提高系统容量的一种方法。PRMA协议是G00dman等学者早在1989年提出的。伴随着第三代移动通信技术的发展,PRMA协议又一次获得了人们的关注,其与CDMA的联合多址技术,即CDMA/PRMA多址接入协议,使系统容量得到明显提高。
1 PRMA协议介绍
PRMA(Packet Reservation Multiple Access)协议,即分组预约多址协议,是利用人们在通话过程中的空闲期来增加系统容量的。据统计,人们在通话过程中,传输话音的带宽占总带宽的35%~50%,另外约50%的带宽都是空闲的。PRMA 协议的内容是将时间轴分为时隙,若干个时隙组成一帧。每一帧中的时隙被分为两类:一类是被预约的时隙,另一类是可用的空闲时隙。时隙的类别是根据在时隙末尾接收到的基站应答信息来确定的。每个移动台在话音突发开始时,采用ALOHA协议来竞争可用的空闲时隙。若移动台竞争成功,则它就预定了后续帧中相同的时隙。在后续帧中,它将不会与其它移动台的分组发生碰撞。当一个话音突发传输结束后,该移动台将释放预约的时隙,使该时隙从预约状态变成可用状态。释放的方法就是在预约的时隙内不传输任何信息,基站检测到该空闲时隙后,就会指明该时隙为可用时隙。图1是PRMA系统的工作示例。

图1中,各时隙内的Rx表示该时隙已经被节点x预约,而I表示该节点还未被预约。对于每一个时隙,如果有两个或两个以上的节点同时发送,那么在基站处必然导致碰撞发生,如第I帧的时隙2。如果发送终端处标记为“一”,则表示相应的时隙是空闲的,没有节点发送信息。由图1可见,在第I帧,时隙2处,节点6、4碰撞,基站无法识别信息,因而节点6和4收不到基站的应答,所以预约第I+1帧的时隙2没有成功。在第I帧的时隙3处,节点3没有发送信息,表示节点3要释放该时隙,因此第I+1帧的时隙3不再处于预约状态。节点6和4在第I+1帧的时隙3和4分别接入成功,并且预约了第I+2帧的时隙3和4。
经过仿真分析,如果物理信道总数为20,即l帧被时分为20个时隙,采用PRMA协议后,系统可容纳的用户总数最多可达37个。然而,若只采用TDMA协议,最多可容纳的用户数是20个,系统容量得到明显提高。
CDMA/PRMA协议的基本思想与PRMA协议类似,只是在cDMA/PRMA协议中,基站无法检测到碰撞事件的发生,基站只能根据多址干扰,即MAI,来判断信道状态并确定是否允许时隙的预约。这样,在每个时隙里,系统所允许的用户数不再是一个,而是多个(如5~7个)。当然,各用户采用的码字必须不同。
2 PRMA专用控制芯片的设计
2.1 处理器的选择
显然,实现PRMA协议几乎不需要什么复杂的算法,而主要依靠程序的控制,因此选择单片机。在系统中,由于信道的通信速率较高,如几百Kbps,单片机是不能胜任的,因此,选用了32位的嵌入式处理器。嵌入式处理器有很多种,但是处理内核主要有以下4种:MIPs内核(64位)、ColdFire内核、PowerPC内核和ARM内核。
powerPC处理器由于其较强的处理能力,在电信级的高端产品中应用较多;而ARM处理器由于其优异的功耗性能,因此在便携式设备中应用广泛。图2是几款处理器的性能对比.(该图引自EEMBC总裁Markus Levy的文章。)

图2中,条状图对应的单位是Telemark。该单位的含义与传统衡量处理器处理能力的单位Dhrystone的含义类似,是对处理器处理能力的一种定义。曲线的单位则是Telemark对功率的归一化,即Telemark/mW。显然,MPC7455的绝对处理能力是最强的,但是考虑到功耗后,ARMl020E的性能显然是最优的。我们最终选用的是ARM9处理器。
考虑到与传输系统的接口以及对接入系统的调试方便,设计中除了实现PRMA协议外,还包括基带收发系统。显然,基带收发系统应该使用FPGA实现。这样,设计可采用如下两种方案:方案①,扩展的FPGA器件挂接在ARM处理器的外部扩展总线上;方案②,选用A1tera公司的SoPC系统。
SoPC系统,即可编程片上系统,将处理器内核与FPGA集成于一体。目前,ALtera公司的SoPC系统主要有两类:一类是硬核SoPC系统,另一类是软核SoPC系统。硬核SoPC系统采用的是ARM处理器。该处理器固化在芯片内,是不能被重新加载的。软核SoPC系统采用的是Altera公司的N10s或N10S.II内核。该内核在每次上电或复位时与FPGA内部的逻辑电路一起重新加载。采用SoPc系统的好处在于用户可根据实际需要在FPGA内部添加外围设备,方便系统设计。同时,Altera公司免费提供一些常用外围设备的IP核,如:网卡控制器、串口控制器、USB控制器等等。通过使用Altera的QUARTUS-II和SoPC开发软件,可以在soPc系统上轻松地构建专用控制芯片。
另外,在SoPC系统内,处理器内核与FPGA间采用标准系统总线,如上述硬核soPc系统内部采用的是ARM公司的AMBA-AHB总线。这样,处理器和FPGA间的数据交换速率要比上述方案①快许多。在我们的设计中,采用了Altera公司的EXPAl处理器。该处理器的内核为ARM922T。
2.2 PRMA协议的实现
2.2.1 帧结构的设计
根据系统要求,采用TDD的双工方式,每帧设置20个时隙,每时隙分为上行和下行两个微时隙;系统采用上下行对称链路,信道传输速率为512kbps,每个微时隙内共有256位。帧及上行时隙结构如图3所示。
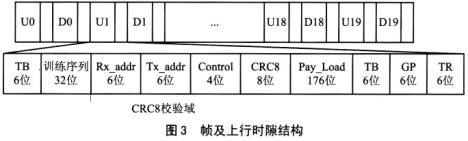
图3中,ux为上行时隙;Dx为下行时隙;TB为发信机输出功率上升下降保护时间; Raddr为接收台地址; Tx—addr为发射台地址;Control为控制比特;Pay load为业务负载;GP为保护间隔; TR为收发转换时间。
与TDMA多址接入技术不同,PRMA是一种面向分组的多址接入技术,因此,分组头的开销是不可避免的。由图3可见,收发地址域分别有6位,因此网络最多可识别64个用户。显然,这样的网络容量是远远不够的。如果采用IPV4的寻址方式,网络容量虽可以达到要求,但是收发地址域就要占用64位的开销,这是无法接受的。因此,对分组头的压缩是必须设法解决的问题。
根据理论仿真结果,一个基站最多可以同时接入37个用户通信,因此,6位的地址识别域对于一个小区而言是足够的。在网络中,当一个移动台发起呼叫或被呼时,该小区的基站首先将其在全网内的唯一识别地址(如IPv4地址)写入自己的数据库中,同时为其分配一个本小区内唯一的临时地址(6位)。移动台与基站通信时,使用6位的临时地址,当分组进入支撑网络后,则使用全网内的唯一地址。地址码的转换在基站处完成。
控制域共有4位,由左到右,分别将其标记为C.0、C.1、C.2和C.3。在上行信道中,用C.0和C.1标记该时隙为业务时隙,如C.0C.1=00.C.2和C.3则预留给以后的功能扩展。
下行信道的时隙结构与上行信道的时隙结构基本相同,只是控制域的含义不同。C.0表示上行信道接入的分组是否正确,C.1表 示是否预约下一帧的该时隙。C.2和C.3预留给以后的功能扩展。
由于信道速率为512kbps,因此6位的保护时间最多可以提供3.5km的传播时延保护。
2.2.2 网络同步的设计
在每个超帧里,设置一个专用的同步广播信道,基站利用该信道广播一个特定的同步训练序列。当移动台进入基站的服务区时,即可检测到该同步训练序列,完成开环同步。
当移动台发起呼叫时,首先向基站发出随机接入分组。随机接入突发的时隙格式如图4所示。Rx_addr标记为基站地址,如全网定义地址“000000”为所有基站的空中接口地址,而在支撑网络内,各基站使用全网唯一的IPv4地址。控制域的C.0和C.1设置为“01”,指示该分组为接入突发分组。Pay_load域只使用48位。该信息为主呼台的全网唯一地址(附有1 6位的校验保护)。Pay 10ad域的其它位合并给GP域。

当基站接收到随机接入突发后,将Rx_MAC_addr记录入数据库中,为其分配一个本小区内的6位地址。同时,基站根据接收到的训练序列相关峰的位置可以计算出移动台与其的传播时延。将上述两信息在随后的下行信道中一同发给主呼移动台,完成网络的闭环同步。
2.2.3 时隙状态寄存器的设计
在PRMA系统中,每一个时隙有两种状态,即可用状态和预约状态。当节点还没有预约到信道时,它只能在可用时隙处竞争;当节点预约到信道后,它不能再去竞争信道,只能在自己的预约信道上传输数据。因此,每个节点对时隙状态的准确跟踪和识别是全网正确工作的基础。时隙状态寄存器就是起到这样的作用。图5是系统的时隙
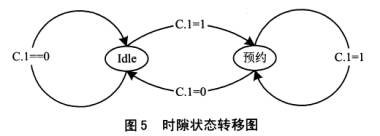
Idle状态即该时隙还未被预约,预约(Resetred)状态表示该时隙已被预约。每个接入节点要跟踪每一个下行信道,分析控制域的C.1位,判断该时隙在下一帧的状态,完成时隙状态的跟踪。在每一个上行信道起始处,各接入节点判断当前时隙的状态,以决定是否发送分组。
时隙状态寄存器为每一个时隙保留3位空间。我们定义:“000”表示信道空闲;“001”表示信道被其它节点预约;“Oll”表示信道被本节点预约。其它状态预留给以后的功能扩展。
2.2.4 分组缓存的设计
话音是对时延有严格要求的业务。在系统中,采用的话音编码器每20ms输出1个分组,话音时延最大不能超过40ms。显然,每个节点设置2个语音分组缓存就足够了。我们将这两个语音分组缓存分别标记为VB1和VB2。
如果VBl和VB2已满,假设VBl中的分组为竞争接入的分组,VB2中的分组为排队等待分组。这时第三个语音分组到达,那么该分组就直接缓存在VB1中,第一个语音分组被丢弃掉,同时VB2中的分组成为竞争接入分组。
2.2.5 分组缓存状态寄存器的设计
如上所述,每个分组缓存可能是空的,也可能已被占用,其中的分组可能是接入分组,也可能是等待分组,还有可能被丢弃掉。因此,要对分组缓存的状态,包括其缓存分组的状态予以跟踪。图6为分组缓存状态转移图,图7为缓存状态寄存器的结构。

图6、7中,Bs为缓存状态位,“1”表示缓存已满,“0”表示缓存空闲,即Idle。As为接入状态位,“1”表示当前分组为接入分组,“0”表示当前分组为等待分组。Drop Counter为丢弃计数器。当Bs=l后,每个时隙到达时,Drop Counter计数器就累加1。当DropCounter累加到门限值时,当前分组就被丢弃掉,缓存恢复为Idle状态。当然,系统还需要一个寄存器存储分组丢弃门限值(drop threshold)。

2.2.6 币点状态寄存器
综上所述,接入节点的状态可能是空闲状态(即Idle,无等待分组传输)、竞争状态(即:Compete,有分组等待传输,但还未预约到信道)及预约状态(即Reserve,有分组等待传输且已经预约到信道)。接入节点的状态转移如图8所示。

由于衰落、噪声和干扰等因素的存在,无线信道是极不可靠的,常常产生误比特,有时甚至出现误帧的情况。当节点处于预约状态时,由于上传的分组错误较多,基站无法识别该分组,那么随后的下行信道就会空闲,该节点就丢弃了对该时隙的预约权,由预约状态转移为竞争状态。
图8中,Wp表示等待分组的数目,在目前的系统中可取0、1、2三个数值。C.0是下行信道控制域的第0位。节点状态寄存器只需占用2位,区分节点的上述3种状态。
2.2.7 节点的行为
时隙状态、缓存状态和节点状态的转移都发生在由Dx到U(x+1)的收发转换时间(TR)处。无论U(x+1) 处是否发送了分组,节点都要分析Dx处基站发出的分组头,刷新时隙状态。另外,处理器还要检测高层是否有语音分组发给自己,刷新Wp及缓存状态,如果Drop Cou“ter数值已经达到Drop Threshold时,相应的分组应 该被丢弃掉,置Bs位为0。结合Dx处下行分组的C.0位 及Wp值,节点状态发生相应的改变。
在每个上行时隙Ux前,节点首先判断时隙x的状 态。如果该时隙被其它节点预约,则节点等待;如果该 时隙被自己预约,则准备传输,假如此时缓存已经为空,即节点已经处于空闲状态,那么Ux将空闲,节点释放对x时隙的预约权;如果该时隙未被预约,且节点 处于竞争状态,那么节点将准备竞争该时隙。
2.2.8基带收发器
由于PRMA是全网同步系统,因此需要高稳定度高精度的时钟源。实际中,我们采用了16.384MHz、O.1×1 0-6时钟源。由于分组在VBx中并不包含信道需要的训练序列和TB时间等,因此在串并转换器与发送缓存间加入了输出控制模块。同样,接收到的数据通过输入控制后,将训练序列等物理层的协议开销就屏蔽掉,进入接收缓存的数据是PRMA接入控制系统所需要的数据,如图9所示。

EXPA 1系统的内部总线采用的是ARM公司的AHB总线。该总线通过桥按器与FPGA相连。我们在FPGA内部设计的AHB SLAVE接口(AHB从接口)就是与该桥接器相连,完成AHB桥接器与FPGA数据交换的功能。
3 几点说明
上述内容是针对PRMA系统中移动节点侧接入控制芯片的讨论。由于篇幅的限制,关于基站侧接入系统的设计不再论述。
通过实验测试,系统可以完成PRMA的功能要求,而且进行一些改进后,系统性能可以得到提高。例如:在上行分组的Control域内利用C.3位向基站指示下一帧的该时隙是否继续预约,这样就可以减少信道空闲造成的浪费。
由于使用了SoPC芯片,因此在系统上不需要太多的外设开销,系统设计十分精简。而且,如果使用更大容量的SoPC芯片,如EXPA4或EXPA10,那么完全可以将中频部分也集成于该芯片内。
上一篇:满足射频调制要求的A/V信号处理
下一篇:相邻信道抑制/干扰对802.11 WLAN造成的影响
推荐阅读最新更新时间:2024-05-07 15:53

 电力工程设计手册 24 电力系统规划设计
电力工程设计手册 24 电力系统规划设计 控制之美(卷1)——控制理论从传递函数到状态空间
控制之美(卷1)——控制理论从传递函数到状态空间- Wi-Fi 8规范已在路上:2.4/5/6GHz三频工作
- 治理混合多云环境的三大举措
- Microchip借助NVIDIA Holoscan平台加速实时边缘AI部署
- 是德科技 FieldFox 手持式分析仪配合 VDI 扩频模块,实现毫米波分析功能
- 高通推出其首款 RISC-V 架构可编程连接模组 QCC74xM,支持 Wi-Fi 6 等协议
- Microchip推出广泛的IGBT 7 功率器件组合,专为可持续发展、电动出行和数据中心应用而设计
- 英飞凌推出新型高性能微控制器AURIX™ TC4Dx
- Rambus宣布推出业界首款HBM4控制器IP,加速下一代AI工作负载
- 恩智浦FRDM平台助力无线连接






- Allegro MicroSystems 在 2024 年德国慕尼黑电子展上推出先进的磁性和电感式位置感测解决方案
- 左手车钥匙,右手活体检测雷达,UWB上车势在必行!
- 狂飙十年,国产CIS挤上牌桌
- 神盾短刀电池+雷神EM-i超级电混,吉利新能源甩出了两张“王炸”
- 浅谈功能安全之故障(fault),错误(error),失效(failure)
- 智能汽车2.0周期,这几大核心产业链迎来重大机会!
- 美日研发新型电池,宁德时代面临挑战?中国新能源电池产业如何应对?
- Rambus推出业界首款HBM 4控制器IP:背后有哪些技术细节?
- 村田推出高精度汽车用6轴惯性传感器
- 福特获得预充电报警专利 有助于节约成本和应对紧急情况
- 直播已结束| STM32 Summit全球在线大会
- 免费尝鲜:ST 双核无线 MCU STM32WB55 开发板
- 【已结束】直播“戴”“芯”:英飞凌可穿戴设备保姆级解决方案
- “泰”想开车智能篇(下):新一代智能汽车智能化
- nanoPower技术:延长电池寿命,提升传感器性能 2021年1月20日 上午10:00在线研讨会
- 《模拟对话》50周年大合集(2013-2016)
- 【TI有奖直播】新一代低功耗蓝牙微控制器CC2640R2,开发和应用案例解析
- 有奖问答|ADI应用之旅——工业大机器健康篇
- EE邀你一起来玩NXP RAPID IOT套件
- 英特尔FPGA可编程加速平台介绍,走近AI、数据中心、基因工程等大咖工程




 京公网安备 11010802033920号
京公网安备 11010802033920号