随着集成电路设计和工艺技术的发展,嵌入式系统已经在PDA、机顶盒、手机等信息终端中被广泛应用。嵌入式系统具有电路尺寸小、成本低廉、可靠性高、功耗低等优点,是未来集成电路发展的方向。而作为嵌入式系统核心的微处理器,其性能直接影响整个系统的性能。为了提高CPU的效率和指令执行的并行性,现代微处理器广泛采用流水线设计,所以,CPU流水线的设计成为决定其性能的关键。
MIPS(Microprocessor without Interlocked Pipeline Stages)是一种典型的RISC(Reduced Instruction Set Computer)微处理器,在嵌入式系统领域中得到广泛的应用。MIPS32TM指令集开放,指令格式规整,易于流水线设计,大量使用寄存器操作。与CISC(Complex Instruction Set Computer)微处理器相比,RISC具有设计更简单、设计周期更短等优点,并可以应用更多先进的技术,开发更快的下一代处理器。
1 基于MIPS指令集的CPU流水线结构
1.1 指令集的选取
设计实现了指令兼容MIPS系列RISC处理器的指令集。由于MIPS32TM指令集是开放的指令集,指令格式非常简单,按照指令格式可分为寄存器类型(R-type)指令、立即数类型(I-type)指令和跳转类型(J-type)指令。这三类指令均为32 bit,而且指令操作码在固定的位置上。这种特点易于指令代码的拆分,易于流水线CPU的设计。
指令类型参考MIPS处理器的指令集设计原则。所有指令的运算都在寄存器中进行,当需要与内存交换数据时,通过内存访问指令进行内存和寄存器的数据交换。设计实现程序中经常使用的34条指令,实现指令集按照功能分成5种类型:算术运算类指令、逻辑运算类指令、数据传送指令、条件转移和无条件跳转类指令、特殊指令等。
1.2 流水线的设计
在基本的MIPS处理器中有5个流水级,其中各流水级定义与主要功能为:IF为计算下一条指令的地址PC,并从指令存储器读取指令;ID为对指令进行译码,从寄存器堆中取出源操作数;EX为当指令是运算类指令时执行运算,当指令是转移类指令时进行有效地址计算;MEM为从数据存储器读写数据;WB为将数据写回到寄存器堆。按照这一流水线结构,本文设计实现一种较为通用的MIPS CPU,通过VHDL语言实现,各模块之的关系如图1所示。

2 嵌入式CPU流水线中的相关性
由于指令以流水线形式并行处理,必产生指令相关性问题,一般存在三种相关:结构相关、数据相关和控制相关,引起流水线竞争。
结构相关问题是指由于硬件资源不足而导致流水线不畅通,例如只有一个存储器模块时,就不能对存储器同时取指令和数据。数据相关问题是指一条指令的后续指令要使用该条指令的结果。而控制相关问题是指转移指令从取指到转向目标地址要花几个时钟周期,但流水线CPU在每个周期都取指令。
解决结构相关问题的方法是尽量增加硬件电路资源,本设计采用哈佛架构,使用指令存储器和数据存储器避免结构竞争。对于寄存器组存在的结构竞争,采用由D-FF构建寄存器予以避免,当写入地址和读出地址相同时,直接用写入数据驱动读出总线。数据相关问题可以用数据前推技术得到缓解。数据前推技术对于ALU计算指令非常有效,但对于存储器读数据指令,如果下面的指令想立即使用其结果,则必须暂停流水线一个周期。至于控制相关,可以使用指令重组优化及延迟转移技术等软件编译方法解决。
3 关键模块的实现
3.1 ALU的实现
ALU是数据通路中的重要部件,负责完成各种运算功能。根据CPU要实现的指令集,确定出ALU的操作控制信号数据宽度为5 bit,运算的数据位数为32 bit。操作控制信号(ALU_OP)和ALU的源数据选择信号根据不同指令的译码由控制逻辑产生。
3.2 控制单元的设计
控制单元要根据输入的指令码产生一系列的控制信号,用于控制数据通路上的多路选择器和各功能部件,保证每一条指令都能够正确执行。
控制单元的输入信号必须设计为32 bit的指令码,而输出信号则要根据需要进行设计。
在IF阶段,控制单元需要根据指令的译码情况,决定PC的更新值,如果是顺序执行的指令,则PC自动加4,对于分支和跳转指令,需要发出跳转指令信号和分支指令信号,从而决定PC的更新值。
在ID阶段,控制单元对指令进行译码,根据指令的操作码和功能部分,发出相应的控制信号;根据指令中的操作数字段,控制单元给出寄存器号,从寄存器堆中读出操作数送入ID与EXE之间的流水线寄存器。如果发生数据相关,数据前置逻辑产生前置控制信号。
在EXE阶段,控制单元给出ALU数据来源的选择信号,以及ALU的运算选择信号。
在MEM阶段,控制单元需要给出数据存储器的读写信号,片选信号等。存储器需要向控制单元返回响应信号。
在WB阶段,控制单元主要控制数据的流向,给出多路选择器的选择信号,选择将存储器读出的数据或ALU的运算结果写回寄存器组。
3.3 数据前推技术的设计
对于数据竞争的检测,通过比较连续3条指令的寄存器标号,把本条指令的rs和rt及前面2条指令的操作数结果寄存器分别进行比较,比较器的输出信号传递到EXE阶段用于选择ALU操作数的来源。
而对于LOAD指令发生的数据相关,必须等到MEM阶段完成之后才能得到有效的数据,因此发生数据相关的下一条指令,只能通过延迟一个周期才能利用数据前置技术,如果配合MIPS编译器,通过使用延迟槽技术可以解决LOAD类型的数据相关。
3.4 指令cache的实现
系统实现了一个容量为2 KB指令Cache,每个Cache行为16 B数据,这样可以利用存储器的16 B的突发式传送。采用2路组相联方式,支持通写(Write Through)模式。由同步SRAM实现。
数据Cache由控制模块、命中与缺失比较模块、访问内存模块、替换模块、输出模块组成。其中控制模块是整个Cache的主控部件,它控制存储器和cache协调工作:当执行单元有取指请求时,以指令的物理地址作为索引看是否命中,如果不命中则控制逻辑启动访存逻辑到内存中去取指,当指令取回时控制逻辑启动替换逻辑对指令Cache进行替换并将指令输出;如果命中,则将指令输出。
使用VHDL来设计和实现上述各关键模块。综合后的接口信号图如图2所示。

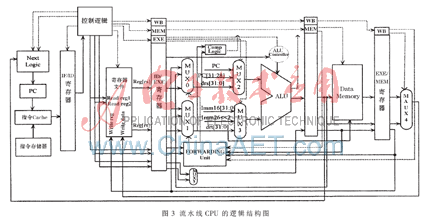
对关键模块和其他模块进行融合,最后得到的CPU流水线结构图如3所示。
4 系统的仿真与验证
使用VHDL实现对各功能模块的设计,并完成功能仿真后,将设计的控制单元和数据通路的各模块进行合并,形成一个完整的嵌入式RISC CPU核,进行系统级仿真。基于系统实现的指令集编写了一个简单的测试程序。
add $5.$0,$0
addi $7,$0,1
sw $7,10($5)
lw $8,10($5)
将指令码写入指令存储器的仿真文件,测试程序运行得到的仿真波形图如图4所示。

每个时钟周期为10 ns,第一个时钟周期T1从10 ns处开始,根据仿真波形可以看出,在T5周期,指令sw $7,10($5)处于EXE阶段,第二条指令addi $7,$0,1处于MEM阶段,需要进行数据前推,Forward_2的值为”10”,通过对测试结果分析可以看出,数据前推成功。通过分析仿真波形图中各个输出信号的波形,根据程序的运行过程,可以判断信号波形正确,达到设计要求。
本文给出了流水线CPU的关键模块的VHDL实现,经过逻辑综合和仿真,仿真结果表明在时序上设计的嵌入式CPU很好地满足了流水线的要求。生成位流数据文件对FPGA进行器件编程,FPGA芯片可以在50 MHz的时钟频率下稳定的运行。
上一篇:一款32位嵌入式CPU的定点加法器设计
下一篇:TI C2000™ 外设资源管理器套件与免费教学 ROM
推荐阅读最新更新时间:2024-03-16 12:30

 独辟蹊径品内核: Linux 内核源代码导读
独辟蹊径品内核: Linux 内核源代码导读 模拟集成电路设计与仿真
模拟集成电路设计与仿真设计资源 培训 开发板 精华推荐
- 【下载】LAT1416 借助 DMA 将内存图像旋转 90 度
- 【下载】LAT1426 IAR flashloader 下载算法制作介绍
- 【下载】LAT1431 STM32 AI Model Zoo 的安装及实例介绍
- 【下载】LAT1435 使用 GPDMA 进行 SPI LCD 整屏传输
- 【下载】LAT1438 AFCI 上位机用户手册
- 【下载】LAT1440 如何在特定串口工具上以不同颜色显示信息








- 再见2019,你好2020!写下你的年终总结和新年计划
- 有奖评测:100套东芝最小光继电器TLP3547的评估板免费申请中!
- Microchip最新SAM 以及 PIC32单片机软件开发平台-- MPLAB® Harmony V3介绍 ”
- 有奖直播|解锁汽车电子黑科技 开创未来驾乘新境界
- 有奖调查|跟泰克一起了解【半导体材料与器件测试知识】(材料科学篇)
- 直播|基于英特尔® Agilex™ FPGA F-Tile的以太网硬核IP详解及如何使用oneAPI对FPGA编程
- 有奖评测+DIY:玩转新版1.3元单片机CH554,赢以太网分析仪器/USB分析仪
- 用富士通Cortex-M3 Easy Kit开发板,DIY出你的精彩!l
- 灵动MM32 eMiniBoard免费测评试用
- “搜器件”小程序又添新功能!




 京公网安备 11010802033920号
京公网安备 11010802033920号