作者:德州仪器 冯华亮
摘要
TMS320C6678 有8 个C66x 核,典型速度是1GHz,每个核有 32KB L1D SRAM,32KB L1P SRAM 和 512KB LL2 SRAM;所有 DSP 核共享 4MB SL2 SRAM。一个 64-bit 1333MTS DDR3 SDRAM 接口可以支持8GB 外部扩展存储器。
存储器访问性能对 DSP 上运行的软件是非常关键的。在 C6678 DSP 上,所有的主模块,包括多个DSP 核和多个DMA 都可以访问所有的存储器。
每个DSP 核每个时钟周期都可以执行最多128 bits 的load 或store 操作。在1GHz 的时钟频率下,DSP 核访问L1D SRAM 的带宽可以达到16GB/S。
DSP 的内部总线交换网络,TeraNet,提供了 C66x 核(包括其本地存储器),外部存储器, EDMA 控制器,和片上外设之间的互连总共有 10 个 EDMA 传输控制器可以被配置起来同时执行任意存储器之间的数据传输。
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
1. 存储器系统简介
TMS320C6678 有8 个C66x 核,每个核有:
32KB L1D (Level 1 Data) SRAM,它和DSP 核运行在相同的速度上,可以被用作普通的数据存储器或数据cache。
32KB L1P (Level 1 Program) SRAM,它和DSP 核运行在相同的速度上,可以被用作普通的程序存储器或程序cache。
512KB LL2 (Local Level 2) SRAM,它的运行速度是DSP 核的一半,可以被用作普通存储器或cache,既可以存放数据也可以存放程序。
所有DSP 核共享4MB SL2 (Shared Level 2) SRAM,它的运行速度是DSP 核的一半,既可以存放数据也可以存放程序。
TMS320C6678 集成一个64-bit 1333MTS DDR3 SDRAM 接口,可以支持8GB 外部扩展存储器,既可以存放数据也可以存放程序。它的总线宽度也可以被配置成32 bits 或16 bits。
存储器访问性能对 DSP 上软件运行的效率是非常关键的。在 C6678 DSP 上,所有的主模块,包括多个DSP 核和多个DMA 都可以访问所有的存储器。
每个DSP 核每个时钟周期都可以执行最多128 bits 的load 或store 操作。在1GHz 的时钟频率下,DSP 核访问 L1D SRAM 的带宽可以达到 16GB/S。当访问二级(L2)存储器或外部存储器时,访问性能主要取决于访问的方式和cache。
每个 DSP 核有一个内部 DMA (IDMA),在 1GHz 的时钟频率下,它能支持高达 8GB/秒的传输。但IDMA 只能访问L1 和LL2 以及配置寄存器,它不能访问外部存储器。
DSP 的内部总线交换网络,TeraNet,提供了 C66x 核 (包括其本地存储器) ,外部存储器, EDMA 控制器,和片上外设之间的互联。总共有 10 个 EDMA 传输控制器可以被配置起来同时执行任意存储器之间的数据传输。芯片内部有两个主要的 TeraNet 模块,一个用 128 bit 总线连接每个端点,速度是DSP 核频率的1/3,理论上,在1GHz 的器件上每个端口支持 5.333GB/秒的带宽;另一个 TeraNet 内部总线交换网络用 256 bit 总线连接每个端点,速度是DSP 核频率的1/2,理论上,在1GHz 的器件上每个端口支持16GB/秒的带宽。
总共有10 个EDMA 传输控制器可以被配置起来同时执行任意存储器之间的数据传输。它们中的两个连接到256-bit, 1/2 DSP 核速度的 TeraNet 内部总线交换网络;另外8 个连接到128-bit, 1/3 DSP 核速度的 TeraNet 内部总线交换网络。
图1 展示了TMS320C6678 的存储器系统。总线上的数字代表它的宽度。大部分模块运行速度是DSP 核时钟的1/n,DDR 的典型速度是1333MTS(Million Transfer per Second)。

图1 TMS320C6678 存储器系统
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
本文对分析以下常见问题会有所帮助:
1.应该用DSP 核还是DMA 来拷贝数据?
2.一个频繁访问存储器的函数会消耗多少时钟周期?
3.当多个主模块共享存储器时,对某个模块的性能会有多大的影响?
本文中的大部分数据是在C6678 EVM (EValuation Module)板上测试得到的,它上面有64-bit 1333MTS 的DDR 存储器。
2. DSP 核,EDMA3,IDMA 拷贝数据的性能比较
数据拷贝的带宽由下面三个因素中最差的一个决定:
1.总线带宽
2.源端吞吐量
3.目的端吞吐量
表1 总结了C6678 上C66x 核,IDMA 和EDMA 的理论带宽。

表1 1GHz C6678 上C66x 核,IDMA 和EDMA 的理论带宽
表2 总结了C6678 EVM(64-bit 1333MTS DDR)上各种存储器端口的理论带宽。

表2 1GHz C6678 上各种存储器端口的理论带宽
表3 列出了在1GHz C6678 EVM( 64-bit 1333MTS DDR)上,在不同情况下用EDMA,IDMA 和DSP 核做大块连续数据拷贝测得的吞吐量。
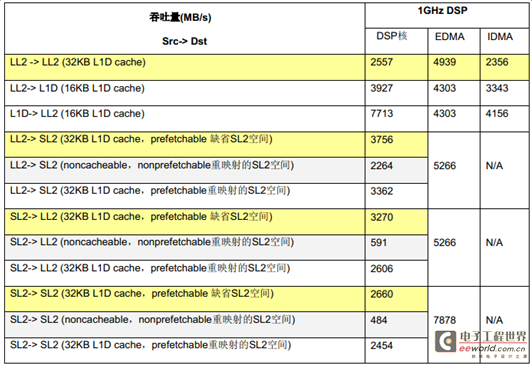

在这些测试中,L1 上的测试数据块的大小是8KB;IDMA LL2->LL2 拷贝的数据块的大小是32KB;其它DSP 核拷贝测试的数据块的大小是64KB,其它EDMA 拷贝测试的数据块大小是128KB。
吞吐量由拷贝的数据量除以消耗的时间得到。
表3 DSP 核,EDMA 和IDMA 数据拷贝的吞吐量比较
总的来说,DSP 核可以高效地访问内部存储器,而用DSP 核访问外部存储器则不是有效利用资源的方式;IDMA 非常适用于DSP 核本地存储器 (L1D,L1P,LL2) 内连续数据块的传输,但它不能访问共享存储器 (SL2, DDR) ;而外部存储器的访问则应尽量使用EDMA。
Cache 配置显著地影响DSP 核的访问性能,Prefetch buffer 也能提高读访问的效率,但它们不影响EDMA 和IDMA。这里所有DSP 核的测试都是基于cold cache(cache 和Prefetch buffer 在测试前被清空)。
对DSP 核,SL2 可以通过从0x0C000000 开始的缺省地址空间被访问,通常这个地址空间被设置为cacheable 而且prefetchable。SL2 可以通过XMC (eXtended Memory Controller) 被重映射到其它存储器空间,通常重映射空间被用作non-cacheable, nonprefetchable 访问(当然它也可以被设置为cacheable 而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点。
前面列出的EDMA 吞吐量数据是在EDMA CC0 (Channel Controller 0) TC0 (Transfer Controller 0)上测得的,EDMA CC1 和EDMA CC2 的吞吐量比EDMA CC0 低一些,后面有专门的章节来比较10 个EDMA 传输控制器的差别。
3. DSP 核访问存储器的时延
L1 和 DSP 核的速度相同,所以DSP 核每个时钟周期可以访问L1 存储器一次。对一些特殊应用,需要非常快的访问小块数据,可以把L1 的一部分配置成普通RAM(而不是cache)来存放数据。
通常,L1 被全部配置成cache,如果cache 访问命中(hit),DSP 核可在一个周期完成访问;如果cache 访问没有命中(miss),DSP 核需要等待数据从下一级存储器中被读到cache 中。
本节讨论DSP 核访问内部存储器和外部DDR 存储器的时延。下面是时延测试的伪代码:

3.1 DSP 核访问LL2 的时延
图2 是在1GHz C6678 EVM 上测得的DSP 核访问LL2 的时延。DSP 核执行512 个连续的LDDW (LoaD Double Word) 或STDW (STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。这个测试使用了32KB L1D cache。
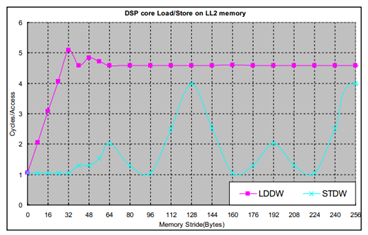
图2 DSP 核访问LL2
对LDB/STB 和LDW/STW 的测试表明,它们的时延与LDDW/STDW 相同。
由于L1D cache 只有在读操作时才会被分配,DSP 核读LL2 总是通过L1D cache。所以,DSP核访问LL2 的性能高度依赖cache。多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache;大于或等于64 字节的地址偏移导致每次访问都miss L1 cache 因为L1D cache 行大小是64 bytes。
由于L1D cache 不会在写操作时被分配,并且这里的测试之前cache 都被清空了,所以任何对LL2 的写操作都通过L1D write buffer (4x16bytes)。对多个写操作,如果地址偏移小于16 bytes,这些操作可能在write buffer 中被合并成一个对LL2 的写操作,从而获得接近平均每个写操作用1 个时钟周期的效率。
当多个写操作之间的偏移是128 bytes 整数倍时,每个写操作都访问LL2 的相同sub-bank (LL2包含两个banks,每个bank 包含4 个总线宽度为16-byte 的sub-bank),对相同sub-bank 的连续访问的时延是4 个时钟周期。对其它的访问偏移量,连续的写操作会访问LL2 不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
C66x 核在C64x+核的基础上有很多改进,C66x 核的L2 存储器控制器和DSP 核速度相同,而 C64x+的L2 存储器控制器的运行速度是DSP 核速度的1/2。图3 比较了C66x 和C64x+ Load/Store LL2 存储器的性能。
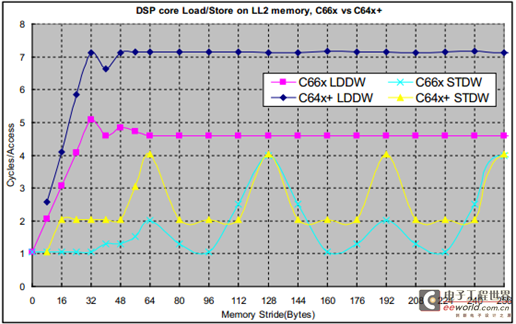
图3 C66x 和C64x+核在LL2 上Load/Store 的时延比较
3.2 DSP 核访问SL2 的时延
图4 是在1GHz C6678 EVM 上测得的DSP 核访问SL2 的时延。DSP 核执行512 个连续的LDDW (LoaD Double Word) 或STDW (STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D 被配置成32KB cache。

图4 DSP 核访问SL2
对LDB/STB 和LDW/STW 的测试表明,它们的时延与LDDW/STDW 相同。
DSP 核读SL2 通常会通过L1D cache,所以,和访问LL2 一样,DSP 核访问SL2 的性能高度依赖cache。
XMC 中还有一个prefetch buffer (8x128bytes) ,它可以被看作是一个额外的只对读操作可用的cache。DSP 核之外的每16-MB 存储器块都可以通过MAR (Memory Attribute Register) 的PFX (PreFetchable eXternally) bit 被配置为是否通过prefetch buffer 读,使能它会对多个主模块共享存储器的效率有很大帮助;它也能显著地改善对SL2 连续读的性能。不过,prefetch buffer 对写操作没有任何作用。
SL2 可以通过从0x0C000000 开始的缺省的地址空间访问,这个空间总是cacheable,通常它也被配置为prefetchable。SL2 可以通过XMC 的配置被重映射到其它地址空间,通常重映射空间被用作non-cacheable, nonprefetchable 访问(当然它也可以被设置为cacheable 而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点,因为地址重映射需要一个额外的时钟周期。
由于L1D cache 不会在写操作时被分配,并且这里的测试之前cache 都被清空了,所以任何对SL2 的写操作都通过L1D write buffer (4x16bytes)。对多个写操作,如果地址偏移小于16 bytes,这些操作可能在write buffer 中被合并成一个对SL2 的写操作,从而获得比较高的效率。XMC也有类似的写合并buffer,它可以合并两个在32 bytes 内的写操作,所以,对偏移小于32 bytes 的写操作,XMC 的写buffer 改善了写操作的性能。
当写偏移是N*256 bytes 时,每个写操作总是访问SL2 相同的bank (SL2 存储器组织结构是4 bank x 2 sub-bank x 32 bytes),对相同bank 的连续访问间隔是4 个时钟周期。对其它的访问偏移量,连续的写操作会访问SL2 不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
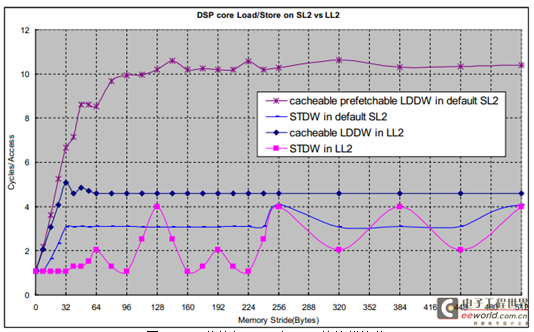
图5 比较了DSP 核访问SL2 和LL2 的访问时延。对地址偏移小于16 bytes 的连续访问,访问SL2 的性能和LL2 几乎相同。而对地址偏移比较大的连续访问,访问SL2 的性能比LL2 差。因此,SL2 最适合于存放代码。
图5 DSP 核访问SL2 和LL2 的性能比较
3.3 DSP 核访问外部DDR 存储器的时延
DSP 核访问外部DDR 存储器高度依赖cache。当DSP 核访问外部存储器时,一个传输请求会被发给XMC。根据cacheable 和prefetchable 的设置,传输请求可能是下列情况中的一种:
一个数据单元 – 如果存储器空间是non-cacheable,nonprefetchable
一个L1 cache line - 如果存储器空间是cacheable 而没有L2 cache,
一个L2 cache line - 如果存储器空间是cacheable 并且设置了L2 cache。
如果要访问的数据在L1/L2 cache 或prefetch buffer 中,则不会有传输请求发出。
如果被访问的空间是prefetchable 的,可能还会产生额外的prefetch 请求。
外部存储器的内容可以被缓存在L1 cache 或/和L2 cache,或者都不用。DSP 核之外的每16-MB存储器块都可以通过MAR (Memory Attribute Register)的PC (Permit Copy) bit 被配置为是否通过cache 访问。如果PC 比特为0,这段空间就不是cacheable 的。如果PC 比特是1 而L2 cache 大小为0 (所有LL2 都被用作普通SRAM),那外部存储器的内容只会被L1 cache 缓存。如果PC比特是1 并且L2 cache 大于0,则外部存储器的内容可以被L1 和L2 cache 同时缓存。
像访问SL2 一样,对外部存储器的读操作也可以利用XMC 里的prefetch buffer。它可以通过MAR (Memory Attribute Register)的PFX (PreFetchable eXternally) bit 来配置。
多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache 和prefetch buffer;大于或等于64 字节的地址偏移导致每次访问都miss L1 cache 因为L1D cache行大小是64 bytes;大于或等于128 字节的地址偏移导致每次访问都miss L2 cache 因为L2 cache 行大小是128 bytes。
如果发生cache miss,DSP 需要等待外部数据传输完成。等待的时间是请求发出时间,数据传输时间或数据返回时间的总和。
图6 是在1GHz C6678 EVM(64-bit 1333MTS DDR)上测得的DSP 核访问DDR 的时延。DSP核执行512 个连续的LDDW (LoaD Double Word) 或STDW (STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D 被配置成32KB cache,LL2的256KB 被设置为cache。
对LDB/STB 和LDW/STW 的测试表明,它们的时延与LDDW/STDW 相同。
注意,下面第二和第三个图实际上是第一个图左边的放大。
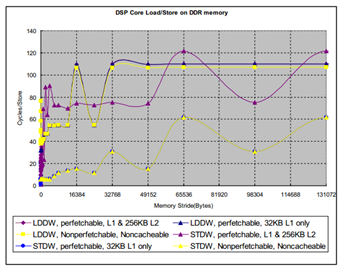

图6 DSP 核对DDR Load/Store 的时延
对地址偏移小于128 bytes 的访问,性能主要受cache 的影响。
L2 cache 会在写操作时被分配,对任何写操作,cache 控制器总是先把被访问的数据所在的cache 行(128 bytes)读进L2 cache,然后在cache 中改写数据。被改写是数据会在发生cache冲突或手工cache 回写操作时被最终写到外部存储里。当写操作的地址偏移是1024 bytes 的整数倍时,多个访问在L2 cache 中发生冲突的概率很大,所以L2 cacheable 写操作的时延会显著地增加。最坏的情况下,每个写操作都会导致一个cache 行的回写 (之前的数据因为冲突而被替换/回写)和一个cache 行的读入(新的数据被分配到cache 中)。
当地址偏移大于512 bytes 时,DDR 页(行)切换开销成为性能下降的主要因素。C6678 EVM上的DDR 页(行)大小或bank 宽度是8KB,而DDR3 存储器包含8 个banks。最坏的情况是,当访问地址偏移量是64KB 时,每个读或写操作都会访问相同bank 中一个新的行,而这种行切换会增加大约40 个时钟周期的时延。请注意,不同的DDR 存储器的时延可能会不一样。
关键字:DSP 存储器
引用地址:TMS320C6678 存储器访问性能 (上)
摘要
TMS320C6678 有8 个C66x 核,典型速度是1GHz,每个核有 32KB L1D SRAM,32KB L1P SRAM 和 512KB LL2 SRAM;所有 DSP 核共享 4MB SL2 SRAM。一个 64-bit 1333MTS DDR3 SDRAM 接口可以支持8GB 外部扩展存储器。
存储器访问性能对 DSP 上运行的软件是非常关键的。在 C6678 DSP 上,所有的主模块,包括多个DSP 核和多个DMA 都可以访问所有的存储器。
每个DSP 核每个时钟周期都可以执行最多128 bits 的load 或store 操作。在1GHz 的时钟频率下,DSP 核访问L1D SRAM 的带宽可以达到16GB/S。
DSP 的内部总线交换网络,TeraNet,提供了 C66x 核(包括其本地存储器),外部存储器, EDMA 控制器,和片上外设之间的互连总共有 10 个 EDMA 传输控制器可以被配置起来同时执行任意存储器之间的数据传输。
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
1. 存储器系统简介
TMS320C6678 有8 个C66x 核,每个核有:
32KB L1D (Level 1 Data) SRAM,它和DSP 核运行在相同的速度上,可以被用作普通的数据存储器或数据cache。
32KB L1P (Level 1 Program) SRAM,它和DSP 核运行在相同的速度上,可以被用作普通的程序存储器或程序cache。
512KB LL2 (Local Level 2) SRAM,它的运行速度是DSP 核的一半,可以被用作普通存储器或cache,既可以存放数据也可以存放程序。
所有DSP 核共享4MB SL2 (Shared Level 2) SRAM,它的运行速度是DSP 核的一半,既可以存放数据也可以存放程序。
TMS320C6678 集成一个64-bit 1333MTS DDR3 SDRAM 接口,可以支持8GB 外部扩展存储器,既可以存放数据也可以存放程序。它的总线宽度也可以被配置成32 bits 或16 bits。
存储器访问性能对 DSP 上软件运行的效率是非常关键的。在 C6678 DSP 上,所有的主模块,包括多个DSP 核和多个DMA 都可以访问所有的存储器。
每个DSP 核每个时钟周期都可以执行最多128 bits 的load 或store 操作。在1GHz 的时钟频率下,DSP 核访问 L1D SRAM 的带宽可以达到 16GB/S。当访问二级(L2)存储器或外部存储器时,访问性能主要取决于访问的方式和cache。
每个 DSP 核有一个内部 DMA (IDMA),在 1GHz 的时钟频率下,它能支持高达 8GB/秒的传输。但IDMA 只能访问L1 和LL2 以及配置寄存器,它不能访问外部存储器。
DSP 的内部总线交换网络,TeraNet,提供了 C66x 核 (包括其本地存储器) ,外部存储器, EDMA 控制器,和片上外设之间的互联。总共有 10 个 EDMA 传输控制器可以被配置起来同时执行任意存储器之间的数据传输。芯片内部有两个主要的 TeraNet 模块,一个用 128 bit 总线连接每个端点,速度是DSP 核频率的1/3,理论上,在1GHz 的器件上每个端口支持 5.333GB/秒的带宽;另一个 TeraNet 内部总线交换网络用 256 bit 总线连接每个端点,速度是DSP 核频率的1/2,理论上,在1GHz 的器件上每个端口支持16GB/秒的带宽。
总共有10 个EDMA 传输控制器可以被配置起来同时执行任意存储器之间的数据传输。它们中的两个连接到256-bit, 1/2 DSP 核速度的 TeraNet 内部总线交换网络;另外8 个连接到128-bit, 1/3 DSP 核速度的 TeraNet 内部总线交换网络。
图1 展示了TMS320C6678 的存储器系统。总线上的数字代表它的宽度。大部分模块运行速度是DSP 核时钟的1/n,DDR 的典型速度是1333MTS(Million Transfer per Second)。
图1 TMS320C6678 存储器系统
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
本文对分析以下常见问题会有所帮助:
1.应该用DSP 核还是DMA 来拷贝数据?
2.一个频繁访问存储器的函数会消耗多少时钟周期?
3.当多个主模块共享存储器时,对某个模块的性能会有多大的影响?
本文中的大部分数据是在C6678 EVM (EValuation Module)板上测试得到的,它上面有64-bit 1333MTS 的DDR 存储器。
2. DSP 核,EDMA3,IDMA 拷贝数据的性能比较
数据拷贝的带宽由下面三个因素中最差的一个决定:
1.总线带宽
2.源端吞吐量
3.目的端吞吐量
表1 总结了C6678 上C66x 核,IDMA 和EDMA 的理论带宽。
表1 1GHz C6678 上C66x 核,IDMA 和EDMA 的理论带宽
表2 总结了C6678 EVM(64-bit 1333MTS DDR)上各种存储器端口的理论带宽。
表2 1GHz C6678 上各种存储器端口的理论带宽
表3 列出了在1GHz C6678 EVM( 64-bit 1333MTS DDR)上,在不同情况下用EDMA,IDMA 和DSP 核做大块连续数据拷贝测得的吞吐量。
在这些测试中,L1 上的测试数据块的大小是8KB;IDMA LL2->LL2 拷贝的数据块的大小是32KB;其它DSP 核拷贝测试的数据块的大小是64KB,其它EDMA 拷贝测试的数据块大小是128KB。
吞吐量由拷贝的数据量除以消耗的时间得到。
表3 DSP 核,EDMA 和IDMA 数据拷贝的吞吐量比较
总的来说,DSP 核可以高效地访问内部存储器,而用DSP 核访问外部存储器则不是有效利用资源的方式;IDMA 非常适用于DSP 核本地存储器 (L1D,L1P,LL2) 内连续数据块的传输,但它不能访问共享存储器 (SL2, DDR) ;而外部存储器的访问则应尽量使用EDMA。
Cache 配置显著地影响DSP 核的访问性能,Prefetch buffer 也能提高读访问的效率,但它们不影响EDMA 和IDMA。这里所有DSP 核的测试都是基于cold cache(cache 和Prefetch buffer 在测试前被清空)。
对DSP 核,SL2 可以通过从0x0C000000 开始的缺省地址空间被访问,通常这个地址空间被设置为cacheable 而且prefetchable。SL2 可以通过XMC (eXtended Memory Controller) 被重映射到其它存储器空间,通常重映射空间被用作non-cacheable, nonprefetchable 访问(当然它也可以被设置为cacheable 而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点。
前面列出的EDMA 吞吐量数据是在EDMA CC0 (Channel Controller 0) TC0 (Transfer Controller 0)上测得的,EDMA CC1 和EDMA CC2 的吞吐量比EDMA CC0 低一些,后面有专门的章节来比较10 个EDMA 传输控制器的差别。
3. DSP 核访问存储器的时延
L1 和 DSP 核的速度相同,所以DSP 核每个时钟周期可以访问L1 存储器一次。对一些特殊应用,需要非常快的访问小块数据,可以把L1 的一部分配置成普通RAM(而不是cache)来存放数据。
通常,L1 被全部配置成cache,如果cache 访问命中(hit),DSP 核可在一个周期完成访问;如果cache 访问没有命中(miss),DSP 核需要等待数据从下一级存储器中被读到cache 中。
本节讨论DSP 核访问内部存储器和外部DDR 存储器的时延。下面是时延测试的伪代码:
3.1 DSP 核访问LL2 的时延
图2 是在1GHz C6678 EVM 上测得的DSP 核访问LL2 的时延。DSP 核执行512 个连续的LDDW (LoaD Double Word) 或STDW (STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。这个测试使用了32KB L1D cache。
图2 DSP 核访问LL2
对LDB/STB 和LDW/STW 的测试表明,它们的时延与LDDW/STDW 相同。
由于L1D cache 只有在读操作时才会被分配,DSP 核读LL2 总是通过L1D cache。所以,DSP核访问LL2 的性能高度依赖cache。多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache;大于或等于64 字节的地址偏移导致每次访问都miss L1 cache 因为L1D cache 行大小是64 bytes。
由于L1D cache 不会在写操作时被分配,并且这里的测试之前cache 都被清空了,所以任何对LL2 的写操作都通过L1D write buffer (4x16bytes)。对多个写操作,如果地址偏移小于16 bytes,这些操作可能在write buffer 中被合并成一个对LL2 的写操作,从而获得接近平均每个写操作用1 个时钟周期的效率。
当多个写操作之间的偏移是128 bytes 整数倍时,每个写操作都访问LL2 的相同sub-bank (LL2包含两个banks,每个bank 包含4 个总线宽度为16-byte 的sub-bank),对相同sub-bank 的连续访问的时延是4 个时钟周期。对其它的访问偏移量,连续的写操作会访问LL2 不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
C66x 核在C64x+核的基础上有很多改进,C66x 核的L2 存储器控制器和DSP 核速度相同,而 C64x+的L2 存储器控制器的运行速度是DSP 核速度的1/2。图3 比较了C66x 和C64x+ Load/Store LL2 存储器的性能。
图3 C66x 和C64x+核在LL2 上Load/Store 的时延比较
3.2 DSP 核访问SL2 的时延
图4 是在1GHz C6678 EVM 上测得的DSP 核访问SL2 的时延。DSP 核执行512 个连续的LDDW (LoaD Double Word) 或STDW (STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D 被配置成32KB cache。
图4 DSP 核访问SL2
对LDB/STB 和LDW/STW 的测试表明,它们的时延与LDDW/STDW 相同。
DSP 核读SL2 通常会通过L1D cache,所以,和访问LL2 一样,DSP 核访问SL2 的性能高度依赖cache。
XMC 中还有一个prefetch buffer (8x128bytes) ,它可以被看作是一个额外的只对读操作可用的cache。DSP 核之外的每16-MB 存储器块都可以通过MAR (Memory Attribute Register) 的PFX (PreFetchable eXternally) bit 被配置为是否通过prefetch buffer 读,使能它会对多个主模块共享存储器的效率有很大帮助;它也能显著地改善对SL2 连续读的性能。不过,prefetch buffer 对写操作没有任何作用。
SL2 可以通过从0x0C000000 开始的缺省的地址空间访问,这个空间总是cacheable,通常它也被配置为prefetchable。SL2 可以通过XMC 的配置被重映射到其它地址空间,通常重映射空间被用作non-cacheable, nonprefetchable 访问(当然它也可以被设置为cacheable 而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点,因为地址重映射需要一个额外的时钟周期。
由于L1D cache 不会在写操作时被分配,并且这里的测试之前cache 都被清空了,所以任何对SL2 的写操作都通过L1D write buffer (4x16bytes)。对多个写操作,如果地址偏移小于16 bytes,这些操作可能在write buffer 中被合并成一个对SL2 的写操作,从而获得比较高的效率。XMC也有类似的写合并buffer,它可以合并两个在32 bytes 内的写操作,所以,对偏移小于32 bytes 的写操作,XMC 的写buffer 改善了写操作的性能。
当写偏移是N*256 bytes 时,每个写操作总是访问SL2 相同的bank (SL2 存储器组织结构是4 bank x 2 sub-bank x 32 bytes),对相同bank 的连续访问间隔是4 个时钟周期。对其它的访问偏移量,连续的写操作会访问SL2 不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
图5 比较了DSP 核访问SL2 和LL2 的访问时延。对地址偏移小于16 bytes 的连续访问,访问SL2 的性能和LL2 几乎相同。而对地址偏移比较大的连续访问,访问SL2 的性能比LL2 差。因此,SL2 最适合于存放代码。
图5 DSP 核访问SL2 和LL2 的性能比较
3.3 DSP 核访问外部DDR 存储器的时延
DSP 核访问外部DDR 存储器高度依赖cache。当DSP 核访问外部存储器时,一个传输请求会被发给XMC。根据cacheable 和prefetchable 的设置,传输请求可能是下列情况中的一种:
一个数据单元 – 如果存储器空间是non-cacheable,nonprefetchable
一个L1 cache line - 如果存储器空间是cacheable 而没有L2 cache,
一个L2 cache line - 如果存储器空间是cacheable 并且设置了L2 cache。
如果要访问的数据在L1/L2 cache 或prefetch buffer 中,则不会有传输请求发出。
如果被访问的空间是prefetchable 的,可能还会产生额外的prefetch 请求。
外部存储器的内容可以被缓存在L1 cache 或/和L2 cache,或者都不用。DSP 核之外的每16-MB存储器块都可以通过MAR (Memory Attribute Register)的PC (Permit Copy) bit 被配置为是否通过cache 访问。如果PC 比特为0,这段空间就不是cacheable 的。如果PC 比特是1 而L2 cache 大小为0 (所有LL2 都被用作普通SRAM),那外部存储器的内容只会被L1 cache 缓存。如果PC比特是1 并且L2 cache 大于0,则外部存储器的内容可以被L1 和L2 cache 同时缓存。
像访问SL2 一样,对外部存储器的读操作也可以利用XMC 里的prefetch buffer。它可以通过MAR (Memory Attribute Register)的PFX (PreFetchable eXternally) bit 来配置。
多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache 和prefetch buffer;大于或等于64 字节的地址偏移导致每次访问都miss L1 cache 因为L1D cache行大小是64 bytes;大于或等于128 字节的地址偏移导致每次访问都miss L2 cache 因为L2 cache 行大小是128 bytes。
如果发生cache miss,DSP 需要等待外部数据传输完成。等待的时间是请求发出时间,数据传输时间或数据返回时间的总和。
图6 是在1GHz C6678 EVM(64-bit 1333MTS DDR)上测得的DSP 核访问DDR 的时延。DSP核执行512 个连续的LDDW (LoaD Double Word) 或STDW (STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D 被配置成32KB cache,LL2的256KB 被设置为cache。
对LDB/STB 和LDW/STW 的测试表明,它们的时延与LDDW/STDW 相同。
注意,下面第二和第三个图实际上是第一个图左边的放大。
图6 DSP 核对DDR Load/Store 的时延
对地址偏移小于128 bytes 的访问,性能主要受cache 的影响。
L2 cache 会在写操作时被分配,对任何写操作,cache 控制器总是先把被访问的数据所在的cache 行(128 bytes)读进L2 cache,然后在cache 中改写数据。被改写是数据会在发生cache冲突或手工cache 回写操作时被最终写到外部存储里。当写操作的地址偏移是1024 bytes 的整数倍时,多个访问在L2 cache 中发生冲突的概率很大,所以L2 cacheable 写操作的时延会显著地增加。最坏的情况下,每个写操作都会导致一个cache 行的回写 (之前的数据因为冲突而被替换/回写)和一个cache 行的读入(新的数据被分配到cache 中)。
当地址偏移大于512 bytes 时,DDR 页(行)切换开销成为性能下降的主要因素。C6678 EVM上的DDR 页(行)大小或bank 宽度是8KB,而DDR3 存储器包含8 个banks。最坏的情况是,当访问地址偏移量是64KB 时,每个读或写操作都会访问相同bank 中一个新的行,而这种行切换会增加大约40 个时钟周期的时延。请注意,不同的DDR 存储器的时延可能会不一样。
上一篇:莱迪思推出Lattice Diamond、iCEcube2等设计工具套件最新版本
下一篇:CPU遇摩尔定律瓶颈 FPGA混合元件或成解决方案
推荐阅读最新更新时间:2024-05-02 23:44
DSP软件向桌面和嵌入式系统挑战
如何合理地安排数据流程,使之在DSP的各执行单元间无冲突地顺利执行,仍是DSP开发人员面临的一个非常重要的问题。由于设计的复杂性,将算法映射到DSP具体目标硬件上,尚不能采用高层次编程语言,必须使用汇编语言,并对器件的并行执行机制有十分清楚的了解。而这种局限于汇编语言的编程设计,正是提高软件开发效率的瓶颈。 90年代早期,嵌入式系统" 嵌入式系统和桌面应用的开发人员曾面临相似的问题。当时为提高设计效率而采用的方法现在仍可借鉴使用。一个短期的解决方案是由编程人员自己解决这一问题。但是,编程人员相对短缺,而且DSP领域编程人员更为紧缺。在DSP开发时,可以考虑采用非DSP专业的编程人员,但这些人员一般倾向于使用桌面和嵌入式
[嵌入式]
购买任意波形发生器需要了解的技术指标

通过了解任意波形发生器(AWG)的关键技术指标,有助于让您做出明智的采购决策。您需要知道如何对各类 AWG 和不同厂商的存储器、采样率、动态范围和带宽进行比较。本文将要探讨 任意波形发生器(AWG) 的技术指标,旨在帮助您更深入的理解这些指标。 存储器大小 存储器大小指的是可用于存储长串用户自定义波形的存储器容量。该技术指标的单位为千兆样点(Gsa)。数据被馈入数模转换器(DAC)中,生成所需信号的电压阶跃表示。为了精确地创建已定义的信号,就会需要高采样率和大存储器。 采样率 采样率是 DAC 在给定时间间隔内可以采样的样点数量。该技术指标的单位为千兆样点/秒(Gsa/s)。采样率决定了任意波形发生器输出信号的最大频率分量
[测试测量]

基于DSP的列车应变力测试系统设计
车轮与轨道间的作用力是评价车辆运行品质的重要因素,能否准确及时地获取轮轨间的作用力直接影响着车辆脱轨系数等参数的计算。应变力测试系统是设计列车运行状态地面安全监测平台的关键环节,本文用DSP芯片开发的测试系统正是针对这一需要。 测试系统硬件设计 系统整体结构 测试系统以高速、高精度的DSP为核心,构成了包括模拟信号预处理、A/D转换、D/A转换等环节的实时信号测试处理系统。其原理框图如图1所示。 应变传感器输出的模拟信号,经RC滤波网络初步滤去信号中的高频成分,然后经A/D转换后,变为数字信号。RC滤波网络、A/D转换构成了测试系统的前向通道。 中央处理单元以TMS320VC33为主体,该DSP是一款高精
[测试测量]
可在线更新应用程序代码的DSP自举模块
针对现有DSP自举模块普遍存在程序代码更新不便的缺陷,提出了一种可便捷高效地在线更新用户应用程序代码的DSP自举模块。该模块由基于LabVIEW的图形用户界面(GUI)软件与C8051F340单片机构成。GUI软件完成DSP应用程序代码的格式转换,并通过驱动USB将转换完成的程序代码传送给C8051F340。C8051F340通过其片上USB外设接收DSP程序代码并存储于片上FLASH中,同时借助标准串行总线控制DSP完成应用程序代码的自举操作。该模块采用在线方式,可一键实现DSP应用程序代码的更新升级与自举操作。 TMS320VC54x系列DSP作为一种低功耗高速处理器在消费电子、通信等领域应用广泛 。通常为实现DSP程序代码
[电源管理]
基于闪烁存储器的TMS320VC5409DSP并行引导装载方法
摘要: 闪烁存储器Am29LV400B的主要特点及编程方法;通过把FLASH的前32K映射到DSP TMS320VC5409的数据空间,按照自举表(Boottable)的格式在FLASH中存储程序代码,由DSP引导装载(Bootloader)程序实现了FLASH的16位并行引导装载;结合实例介绍了该引导装载方法的实现过程。
关键词: DSP 闪烁存储器 引导装载
TMS320VC5409是TI公司推出的第一代的高性能、低价位、低功耗数字信号处理器(DSP)。与现在流行的TMS320C5409相比,性能提高了60%,功耗效率提高了50%。它的应用对象大多是要求能脱机运行的内嵌式系统,如
[应用]
用DSP控制器整合马达控制和功率因数校正
随着数字信号处理器(DSP)价格从几百美元降到3美元,DSP在价格敏感的家电(如洗衣机、冰箱、加热器、通风和空调机)中正越来越多地被采用。带特殊外设的高MIPs DSP,除显著地改进这些产品性能外,还大大地简化产品设计过程并提供各种重要的特异性能。DSP非凡的处理能力,使得制造商能满足用户不断增加的要求,如较高的效率和可变速度工作及精确的速度控制特性。
低成本DSP控制器能使很多先进的马达控制算法内置在对成本非常敏感的应用中。DSP控制器的带宽也使设计人员能用一个控制器整合多种功能,如把马达控制、功率因数校正和通信协议整合在一起(见图2)。本文描述采用低成本DSP控制器的单板AC感应马达驱动(带功
[应用]
基于USB和DSP的数据采集系统的设计
介绍了一种利用USB2.0的高速传输特性,基于USB和DSP的数据采集系统。详细论述了系统的总体结构、部分硬件设计,并简要叙述了相应固件程序的实现。 测量仪器一般由数据采集、数据分析和显示三部分组成,而数据分析和显示可以由PC机的软件来完成,因此只要额外提供一定的数据采集硬件就可以和PC机组成测量仪器。这种基于PC机的测量仪器被称为虚拟仪器 。而在一些数据量比较大、采集时间比较长的场合,就需要采用高速的数据传输通道。基于虚拟仪器的思想和高速传输通道的要求,设计了一种基于DSP和USB2.0的高速数据传输接口。
1 数据采集系统硬件
数据采集系统由A/D数据采集单元、USB从接口
[嵌入式]
大连SK海力士非易失性存储器项目开工
5月16日,大连市与SK海力士共创“芯”未来战略合作签约仪式以视频方式在大连市和韩国首尔同步举行。SK海力士·英特尔DMTM半导体 (大连)有限公司非易失性存储器项目在大连金普新区开工。 该项目将建设一座新的晶圆工厂,生产非易失性存储器3D NAND芯片产品。 2020年,SK海力士宣布收购英特尔NAND闪存及存储业务,其中包括英特尔大连工厂。2021年底,SK海力士完成了收购英特尔NAND闪存及SSD业务案的第一阶段,从英特尔手中接管了SSD业务及其位于大连的NAND闪存制造厂的资产。
[手机便携]
 嵌入式系统软硬件协同设计教程:基于Xilinx Zynq-7000 (符意德)
嵌入式系统软硬件协同设计教程:基于Xilinx Zynq-7000 (符意德) 嵌入式网络那些事:LwIP协议深度剖析与实战演练
嵌入式网络那些事:LwIP协议深度剖析与实战演练











 京公网安备 11010802033920号
京公网安备 11010802033920号