摘要:通过对心理声学模型的简化,并在子带滤波器和量化编码模块采用快速算法,大大降低了运算量,在一片100MIPS的定点DSP上实现了实时压缩。
关键词:音频编码 掩蔽阈值 心理声学模分析子带滤波器
MP3是MPEG-1国际标准中音频压缩层3的简称,单声道比特率一般取64kbps,在采样率44.1kHz的情况下,其压缩比可达12倍以上,被广泛应用于互联网等许多场合。由于解码比编码过程简单很多,MP3播放机或随身听已随处可见,但MP3编码在单片机定点DSP上实现,并要保证音质,则鲜有耳闻。考虑到心理声学模型在整个MP3音频编码算法中所占比例巨大,笔者从简化该模型入手,采用快速算法减少了带编码的运算量和数据量,尽可能少量化编码的迭代循环次数,从而在一片美国德州仪器公司的TMS320C549芯片上实现了MP3的实时压缩,用标准解码软件回放,主观评定,对于通常的音频能达到接近CD的音质。
 1 MP3编码算法及处理
图1是MP3编码器的系统方框图。每声道以1152个采样值为一帧进行处理。首先,分析子带滤波器采用正交镜像滤波器组,将20kHz左右带宽的信号划分成相等带宽的32个子带。然后对子样值作MDCT以补偿子带滤波的不足,主要是为提高频率分辨率、消除由子带滤波引起的带间混迭。
同时采样值通过心理声学模型计算出各频带的掩蔽阈值。
失真控制循环和非归一化量化控制循环是量化编码循环过程,它通过量化减少各MDCT系数的精度,使编码比特数得以降低。不同系数采用不同的量化阶,从耳敏感的频率量化精度高,不敏感的频率量化精度低,量化误差则不会被人耳察觉。选择量化阶的依据就是心理声学模型计算出的掩蔽阀值。
1 MP3编码算法及处理
图1是MP3编码器的系统方框图。每声道以1152个采样值为一帧进行处理。首先,分析子带滤波器采用正交镜像滤波器组,将20kHz左右带宽的信号划分成相等带宽的32个子带。然后对子样值作MDCT以补偿子带滤波的不足,主要是为提高频率分辨率、消除由子带滤波引起的带间混迭。
同时采样值通过心理声学模型计算出各频带的掩蔽阈值。
失真控制循环和非归一化量化控制循环是量化编码循环过程,它通过量化减少各MDCT系数的精度,使编码比特数得以降低。不同系数采用不同的量化阶,从耳敏感的频率量化精度高,不敏感的频率量化精度低,量化误差则不会被人耳察觉。选择量化阶的依据就是心理声学模型计算出的掩蔽阀值。
 最后将量化阶等信息以及霍夫曼码打包成比特流,供解码用。
那么为什么掩蔽阈值能反映人耳的听觉特点呢?
人耳的听觉特性涉及生理声学和心理声学方面的问题。例如人耳对不同频率的声音感觉不同就是生理方面的问题,其中对2kHz~4kHz的声音最敏感,且低频较高频敏感。敏感程度具体体现为静态掩蔽阈值,如图2虚线所示,表示在安静的情况下,各种频率的声音刚好被听到的音量。与人的心理知觉有关的有掩蔽效应等。掩蔽效应指一个声音的听觉感受受到另一个声音影响的现象,分为时间掩蔽(前向、后向掩蔽)和频率掩蔽(同时掩蔽)。例如,当一个较强的声音停止后,要过一会儿才能听到另一个较强的声音,这就是时间掩蔽效应。频率掩蔽是指一个声音对与其同时存在的临近频率的声音产生的影响,如图2实线所示。其中标志1的实线表示:当1kHz的掩蔽声音为60dB时,不同频率的声音刚好被听到的分贝值,可见越临近频率被掩蔽得越厉害,且低频更易掩蔽高频。
因此心理声学模型就先用FFT分析信号中包含的频率分量,将每个频率处受到其他所有频率分量掩蔽的值加起来,连线得到的曲线就是掩蔽阈值,是频率的函数。当某频率分量的能量处曲线下方时,不能被人耳感觉到,则该频率分量可用零比特编码;另一方面,选择量化阶时若能保证量化噪声低于掩蔽曲线,也不被人耳察觉,所以掩蔽值越大的频率分量量化阶可以越大。因此用掩蔽阈值作为量化编码的依据,就能够信证压缩后的声音质量。由于声音信号随时间改变,因此每帧信号都要计算两次心理声学模型,其中要用到大量的实验测试数据,运算量之在是可想而知的。
2 算法的简化和优化
2.1 分析子带滤波器的快速算法
分析子带滤波器的输入是32个采样值,输出是32个频率等间隔的子带样值。它首先将32个采样值放入一个长度512的先进先出(FIFO)缓存;对该缓存加窗;然后512个缓存中每8个值累加,转换成64个中间值;最后通过(1)或将64个中间值变换成32个采样值:
最后将量化阶等信息以及霍夫曼码打包成比特流,供解码用。
那么为什么掩蔽阈值能反映人耳的听觉特点呢?
人耳的听觉特性涉及生理声学和心理声学方面的问题。例如人耳对不同频率的声音感觉不同就是生理方面的问题,其中对2kHz~4kHz的声音最敏感,且低频较高频敏感。敏感程度具体体现为静态掩蔽阈值,如图2虚线所示,表示在安静的情况下,各种频率的声音刚好被听到的音量。与人的心理知觉有关的有掩蔽效应等。掩蔽效应指一个声音的听觉感受受到另一个声音影响的现象,分为时间掩蔽(前向、后向掩蔽)和频率掩蔽(同时掩蔽)。例如,当一个较强的声音停止后,要过一会儿才能听到另一个较强的声音,这就是时间掩蔽效应。频率掩蔽是指一个声音对与其同时存在的临近频率的声音产生的影响,如图2实线所示。其中标志1的实线表示:当1kHz的掩蔽声音为60dB时,不同频率的声音刚好被听到的分贝值,可见越临近频率被掩蔽得越厉害,且低频更易掩蔽高频。
因此心理声学模型就先用FFT分析信号中包含的频率分量,将每个频率处受到其他所有频率分量掩蔽的值加起来,连线得到的曲线就是掩蔽阈值,是频率的函数。当某频率分量的能量处曲线下方时,不能被人耳感觉到,则该频率分量可用零比特编码;另一方面,选择量化阶时若能保证量化噪声低于掩蔽曲线,也不被人耳察觉,所以掩蔽值越大的频率分量量化阶可以越大。因此用掩蔽阈值作为量化编码的依据,就能够信证压缩后的声音质量。由于声音信号随时间改变,因此每帧信号都要计算两次心理声学模型,其中要用到大量的实验测试数据,运算量之在是可想而知的。
2 算法的简化和优化
2.1 分析子带滤波器的快速算法
分析子带滤波器的输入是32个采样值,输出是32个频率等间隔的子带样值。它首先将32个采样值放入一个长度512的先进先出(FIFO)缓存;对该缓存加窗;然后512个缓存中每8个值累加,转换成64个中间值;最后通过(1)或将64个中间值变换成32个采样值:
 寻找快速算法的关键就是这最后一步。将系数设数组:
寻找快速算法的关键就是这最后一步。将系数设数组:
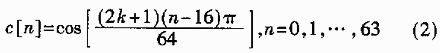 可以发现该数组具有如下的对称性:
c[16+n]=c[16-n],n=0,1,…,16 (3)
c[48+n]=-c[48-n],n=0,1,…,15 (4)
所以合并系数相等或相反的项,(1)式变成:
可以发现该数组具有如下的对称性:
c[16+n]=c[16-n],n=0,1,…,16 (3)
c[48+n]=-c[48-n],n=0,1,…,15 (4)
所以合并系数相等或相反的项,(1)式变成:
 其中,
其中,
 可见用(5)式代替(1)式可以减少一半的乘法运算。又发现(5)式和标准的IDCT非常相似,可以将Lee提出的快速IDCT算法稍加改动推导(5)式的快速算法。所以又将32点变换分解成以下的两个16点变换:
可见用(5)式代替(1)式可以减少一半的乘法运算。又发现(5)式和标准的IDCT非常相似,可以将Lee提出的快速IDCT算法稍加改动推导(5)式的快速算法。所以又将32点变换分解成以下的两个16点变换:

 其中,
其中,
 最终的子带样值是如下的蝶形组合:
X[K]=Xe[k]+(1/cos[(2k+1)π/64]Xo[k],k=0,1,…,15 (11)
X[31-k]=Xe[k]-(1/cos[(2k+1)π/64])Xo[k],k=0,1,…,15 (12)
直接计算(1)式需要64%26;#215;32次乘法和63%26;#215;32次加法,采用快速算法需16%26;#215;16%26;#215;2+16%26;#215;2次乘法和15%26;#215;16%26;#215;2+16%26;#215;2+31+15次加法,运算量原来的1/4,而且数据表格所占用的存储空间也减少为原来的1/8左右。
2.2 心理声学模型的简化
根据试验观察发现每帧的掩蔽阈值曲线大致相同,所以考虑采用静态声学心理模型,具体做法是:首先对某一具有代表性的音频帧,
最终的子带样值是如下的蝶形组合:
X[K]=Xe[k]+(1/cos[(2k+1)π/64]Xo[k],k=0,1,…,15 (11)
X[31-k]=Xe[k]-(1/cos[(2k+1)π/64])Xo[k],k=0,1,…,15 (12)
直接计算(1)式需要64%26;#215;32次乘法和63%26;#215;32次加法,采用快速算法需16%26;#215;16%26;#215;2+16%26;#215;2次乘法和15%26;#215;16%26;#215;2+16%26;#215;2+31+15次加法,运算量原来的1/4,而且数据表格所占用的存储空间也减少为原来的1/8左右。
2.2 心理声学模型的简化
根据试验观察发现每帧的掩蔽阈值曲线大致相同,所以考虑采用静态声学心理模型,具体做法是:首先对某一具有代表性的音频帧,
 根据心理声学模型计算出掩蔽阈值曲线,在压缩其它音频源时,不再计算每帧的心理声学模型,而是认为每帧信号与上述被分析过的代表帧具有相同的掩蔽特性。这样,虽然不是很准确,但通常情况下,误差不会太大,不易被人耳察觉,省去心理学模型需的巨大运算量和存储空间。实践证明编码效果令人满意,而且对于要求不是很高的应用场合,可以认为掩蔽阈值是频率的常数函数,每个频带采用相同的量化阶,也听不出声音质量的明显下降。
2.3 量化编码迭代循环的简化
量化编码迭代是两重循环过程,图3是外迭代循环流图,迭代的目的是在可用比特数的限制之内,以各频带的掩蔽值为依据,确定全局增益(体现了全局量化阶)和各频带的缩放因子(体现了局部量化阶)。内循环逐步增加量化器步长,即全局增益,直到MDCT系数量化后可被可用比特进行霍夫曼编码,即通过增加全局量化阶以降低编码比特数;外循环依据掩蔽阈值检测各缩放因子带的失真,若超过允许失真,则扩大该带的MDCT系数,即增大该带的缩放因子,以降低局部失真;最后一次迭代的结果作为最终的霍夫曼码。每一次循环都要用当前量化阶量化并霍夫曼编码一次,运算量相当大。从外循环可以看出掩蔽阈值最终决定缩放因子,为了能省去外控代循环,将代表帧的缩放因子作成表格,供每帧采用。
由于上述三个模块是最主要并且运算量最大的模块,通过对它们的简化和优化,程序大小和运算量可得到极大的减少。
3 用定点DSP实现MP3压缩算法
为了实现MP3的实时编码,必须采用高速DSP芯片。采用美国德州仪器(TI)公司的主流定点DSP芯片TMS320C549,其运算速度100MIPS,调试开发的环境是TI公司的第三方Spectrum Digital公司的EVM评估板,板上除了TMS320C549自带32K字片上内存外,还有128K字片外内存,数模转换采用TI的TLC320AD55,与PC机通过JTAG口实现数据与程序的加载和调试。
由于评估板与主机的接口速度太慢,即使能做到实时压缩,将比特流传给PC机存盘的速度也会跟不上。因此笔者采用的办法是:将原始PCM音频数据从PC机的硬盘文件加载到板上的片外内存,压缩后的数据传给PC机存盘,再加载后续文件,压缩存盘,直到整个音频文件全部压缩完,最后用C语言程序将各数据块拼成MP3文件,用软件解码程序回放。是否能达到实时要求只能通过测试每帧运行的指令数判断。
在运用快速算法计算子带分析滤波器时,考虑到DSP芯片的特点,每分解一次,要作一次加(10)式的加法,势必降低精度,另外(11)和(12)式的系数动态范围太大,精度也会受到影响,因此,只分解到16点DCT运算。
采用静态心理声学模型,心理声学模型和量化编码外循环所需的运算量就为零。代表帧的心理声学模型和缩放因子采用C语言或MATLAB语言编程计算,或者将网上下载MP3文件中的缩放因子信息破译出来加以利用,子带分析滤波器之后的MDCT全部采用长块。表1是静态缩放因子比特数和缩放因子的一种设置方案。
表1 缩放因子数据表格
缩放因子带
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
缩放因子比特数
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
缩放因子
1
1
0
0
1
1
4
5
3
7
5
3
0
3
0
1
0
7
5
0
3
另外在内循环中,首先初步选择一个全局增益使最大量化值小于码表可编码的最大值,标准推荐的作法是全局增益从小开始,每循环一次量化后,比较最大量化值,并调整一次全局增益,直到满足要求为止。本程序省去了这一循环,事先根据最大谱线值计算出应有的全局增益,作成数据表格,程序中只需根据最大谱线值查表即可。初始化全局增益确定后,要分区、量化、编码并计算编码比特数,如果比特数太大或太小都还要调整全局增益。对这一迭代循环过程,采用折半搜索的办法实现,也就是说第一次循环时全局增益取上述初始化值的一半,若编码比特数超出要求,则再取一半作为新的全局增益,否则增大一半,如此不断循环直到无法折半为止。这种折半搜索的方法比逐一搜索要快很多。
采用了这些简化、优化措施以及编程技巧,整个编码程序运算量仅需74MIPS左右,片上存储空间占用27K字左右。用标准的MP3回放软件解码,通过主观测评,音质接收CD。
由于本系统对心理声学模型进行了大量的简化,对于一般的音乐,这种简化带来的声音质量的下降并不明显,尤其是在要求不高的应用场合完全可行。但是当应用到某些编码难度较高的音频信号,例如响板时,声音质量下降较明显。因此如果采用更高运算速度的DSP,可在该编码系统中加入一个完备的或简化的动态心理声学模型,编码质量可进一步提高,至于简化的动态心理声学模型还有待进一步摸索。
根据心理声学模型计算出掩蔽阈值曲线,在压缩其它音频源时,不再计算每帧的心理声学模型,而是认为每帧信号与上述被分析过的代表帧具有相同的掩蔽特性。这样,虽然不是很准确,但通常情况下,误差不会太大,不易被人耳察觉,省去心理学模型需的巨大运算量和存储空间。实践证明编码效果令人满意,而且对于要求不是很高的应用场合,可以认为掩蔽阈值是频率的常数函数,每个频带采用相同的量化阶,也听不出声音质量的明显下降。
2.3 量化编码迭代循环的简化
量化编码迭代是两重循环过程,图3是外迭代循环流图,迭代的目的是在可用比特数的限制之内,以各频带的掩蔽值为依据,确定全局增益(体现了全局量化阶)和各频带的缩放因子(体现了局部量化阶)。内循环逐步增加量化器步长,即全局增益,直到MDCT系数量化后可被可用比特进行霍夫曼编码,即通过增加全局量化阶以降低编码比特数;外循环依据掩蔽阈值检测各缩放因子带的失真,若超过允许失真,则扩大该带的MDCT系数,即增大该带的缩放因子,以降低局部失真;最后一次迭代的结果作为最终的霍夫曼码。每一次循环都要用当前量化阶量化并霍夫曼编码一次,运算量相当大。从外循环可以看出掩蔽阈值最终决定缩放因子,为了能省去外控代循环,将代表帧的缩放因子作成表格,供每帧采用。
由于上述三个模块是最主要并且运算量最大的模块,通过对它们的简化和优化,程序大小和运算量可得到极大的减少。
3 用定点DSP实现MP3压缩算法
为了实现MP3的实时编码,必须采用高速DSP芯片。采用美国德州仪器(TI)公司的主流定点DSP芯片TMS320C549,其运算速度100MIPS,调试开发的环境是TI公司的第三方Spectrum Digital公司的EVM评估板,板上除了TMS320C549自带32K字片上内存外,还有128K字片外内存,数模转换采用TI的TLC320AD55,与PC机通过JTAG口实现数据与程序的加载和调试。
由于评估板与主机的接口速度太慢,即使能做到实时压缩,将比特流传给PC机存盘的速度也会跟不上。因此笔者采用的办法是:将原始PCM音频数据从PC机的硬盘文件加载到板上的片外内存,压缩后的数据传给PC机存盘,再加载后续文件,压缩存盘,直到整个音频文件全部压缩完,最后用C语言程序将各数据块拼成MP3文件,用软件解码程序回放。是否能达到实时要求只能通过测试每帧运行的指令数判断。
在运用快速算法计算子带分析滤波器时,考虑到DSP芯片的特点,每分解一次,要作一次加(10)式的加法,势必降低精度,另外(11)和(12)式的系数动态范围太大,精度也会受到影响,因此,只分解到16点DCT运算。
采用静态心理声学模型,心理声学模型和量化编码外循环所需的运算量就为零。代表帧的心理声学模型和缩放因子采用C语言或MATLAB语言编程计算,或者将网上下载MP3文件中的缩放因子信息破译出来加以利用,子带分析滤波器之后的MDCT全部采用长块。表1是静态缩放因子比特数和缩放因子的一种设置方案。
表1 缩放因子数据表格
缩放因子带
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
缩放因子比特数
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
缩放因子
1
1
0
0
1
1
4
5
3
7
5
3
0
3
0
1
0
7
5
0
3
另外在内循环中,首先初步选择一个全局增益使最大量化值小于码表可编码的最大值,标准推荐的作法是全局增益从小开始,每循环一次量化后,比较最大量化值,并调整一次全局增益,直到满足要求为止。本程序省去了这一循环,事先根据最大谱线值计算出应有的全局增益,作成数据表格,程序中只需根据最大谱线值查表即可。初始化全局增益确定后,要分区、量化、编码并计算编码比特数,如果比特数太大或太小都还要调整全局增益。对这一迭代循环过程,采用折半搜索的办法实现,也就是说第一次循环时全局增益取上述初始化值的一半,若编码比特数超出要求,则再取一半作为新的全局增益,否则增大一半,如此不断循环直到无法折半为止。这种折半搜索的方法比逐一搜索要快很多。
采用了这些简化、优化措施以及编程技巧,整个编码程序运算量仅需74MIPS左右,片上存储空间占用27K字左右。用标准的MP3回放软件解码,通过主观测评,音质接收CD。
由于本系统对心理声学模型进行了大量的简化,对于一般的音乐,这种简化带来的声音质量的下降并不明显,尤其是在要求不高的应用场合完全可行。但是当应用到某些编码难度较高的音频信号,例如响板时,声音质量下降较明显。因此如果采用更高运算速度的DSP,可在该编码系统中加入一个完备的或简化的动态心理声学模型,编码质量可进一步提高,至于简化的动态心理声学模型还有待进一步摸索。
引用地址:基于定点DSP的MP3间频编码算法研究及实现
1 MP3编码算法及处理
图1是MP3编码器的系统方框图。每声道以1152个采样值为一帧进行处理。首先,分析子带滤波器采用正交镜像滤波器组,将20kHz左右带宽的信号划分成相等带宽的32个子带。然后对子样值作MDCT以补偿子带滤波的不足,主要是为提高频率分辨率、消除由子带滤波引起的带间混迭。
同时采样值通过心理声学模型计算出各频带的掩蔽阈值。
失真控制循环和非归一化量化控制循环是量化编码循环过程,它通过量化减少各MDCT系数的精度,使编码比特数得以降低。不同系数采用不同的量化阶,从耳敏感的频率量化精度高,不敏感的频率量化精度低,量化误差则不会被人耳察觉。选择量化阶的依据就是心理声学模型计算出的掩蔽阀值。
最后将量化阶等信息以及霍夫曼码打包成比特流,供解码用。
那么为什么掩蔽阈值能反映人耳的听觉特点呢?
人耳的听觉特性涉及生理声学和心理声学方面的问题。例如人耳对不同频率的声音感觉不同就是生理方面的问题,其中对2kHz~4kHz的声音最敏感,且低频较高频敏感。敏感程度具体体现为静态掩蔽阈值,如图2虚线所示,表示在安静的情况下,各种频率的声音刚好被听到的音量。与人的心理知觉有关的有掩蔽效应等。掩蔽效应指一个声音的听觉感受受到另一个声音影响的现象,分为时间掩蔽(前向、后向掩蔽)和频率掩蔽(同时掩蔽)。例如,当一个较强的声音停止后,要过一会儿才能听到另一个较强的声音,这就是时间掩蔽效应。频率掩蔽是指一个声音对与其同时存在的临近频率的声音产生的影响,如图2实线所示。其中标志1的实线表示:当1kHz的掩蔽声音为60dB时,不同频率的声音刚好被听到的分贝值,可见越临近频率被掩蔽得越厉害,且低频更易掩蔽高频。
因此心理声学模型就先用FFT分析信号中包含的频率分量,将每个频率处受到其他所有频率分量掩蔽的值加起来,连线得到的曲线就是掩蔽阈值,是频率的函数。当某频率分量的能量处曲线下方时,不能被人耳感觉到,则该频率分量可用零比特编码;另一方面,选择量化阶时若能保证量化噪声低于掩蔽曲线,也不被人耳察觉,所以掩蔽值越大的频率分量量化阶可以越大。因此用掩蔽阈值作为量化编码的依据,就能够信证压缩后的声音质量。由于声音信号随时间改变,因此每帧信号都要计算两次心理声学模型,其中要用到大量的实验测试数据,运算量之在是可想而知的。
2 算法的简化和优化
2.1 分析子带滤波器的快速算法
分析子带滤波器的输入是32个采样值,输出是32个频率等间隔的子带样值。它首先将32个采样值放入一个长度512的先进先出(FIFO)缓存;对该缓存加窗;然后512个缓存中每8个值累加,转换成64个中间值;最后通过(1)或将64个中间值变换成32个采样值:
寻找快速算法的关键就是这最后一步。将系数设数组:
可以发现该数组具有如下的对称性:
c[16+n]=c[16-n],n=0,1,…,16 (3)
c[48+n]=-c[48-n],n=0,1,…,15 (4)
所以合并系数相等或相反的项,(1)式变成:
其中,
可见用(5)式代替(1)式可以减少一半的乘法运算。又发现(5)式和标准的IDCT非常相似,可以将Lee提出的快速IDCT算法稍加改动推导(5)式的快速算法。所以又将32点变换分解成以下的两个16点变换:
其中,
最终的子带样值是如下的蝶形组合:
X[K]=Xe[k]+(1/cos[(2k+1)π/64]Xo[k],k=0,1,…,15 (11)
X[31-k]=Xe[k]-(1/cos[(2k+1)π/64])Xo[k],k=0,1,…,15 (12)
直接计算(1)式需要64%26;#215;32次乘法和63%26;#215;32次加法,采用快速算法需16%26;#215;16%26;#215;2+16%26;#215;2次乘法和15%26;#215;16%26;#215;2+16%26;#215;2+31+15次加法,运算量原来的1/4,而且数据表格所占用的存储空间也减少为原来的1/8左右。
2.2 心理声学模型的简化
根据试验观察发现每帧的掩蔽阈值曲线大致相同,所以考虑采用静态声学心理模型,具体做法是:首先对某一具有代表性的音频帧,
根据心理声学模型计算出掩蔽阈值曲线,在压缩其它音频源时,不再计算每帧的心理声学模型,而是认为每帧信号与上述被分析过的代表帧具有相同的掩蔽特性。这样,虽然不是很准确,但通常情况下,误差不会太大,不易被人耳察觉,省去心理学模型需的巨大运算量和存储空间。实践证明编码效果令人满意,而且对于要求不是很高的应用场合,可以认为掩蔽阈值是频率的常数函数,每个频带采用相同的量化阶,也听不出声音质量的明显下降。
2.3 量化编码迭代循环的简化
量化编码迭代是两重循环过程,图3是外迭代循环流图,迭代的目的是在可用比特数的限制之内,以各频带的掩蔽值为依据,确定全局增益(体现了全局量化阶)和各频带的缩放因子(体现了局部量化阶)。内循环逐步增加量化器步长,即全局增益,直到MDCT系数量化后可被可用比特进行霍夫曼编码,即通过增加全局量化阶以降低编码比特数;外循环依据掩蔽阈值检测各缩放因子带的失真,若超过允许失真,则扩大该带的MDCT系数,即增大该带的缩放因子,以降低局部失真;最后一次迭代的结果作为最终的霍夫曼码。每一次循环都要用当前量化阶量化并霍夫曼编码一次,运算量相当大。从外循环可以看出掩蔽阈值最终决定缩放因子,为了能省去外控代循环,将代表帧的缩放因子作成表格,供每帧采用。
由于上述三个模块是最主要并且运算量最大的模块,通过对它们的简化和优化,程序大小和运算量可得到极大的减少。
3 用定点DSP实现MP3压缩算法
为了实现MP3的实时编码,必须采用高速DSP芯片。采用美国德州仪器(TI)公司的主流定点DSP芯片TMS320C549,其运算速度100MIPS,调试开发的环境是TI公司的第三方Spectrum Digital公司的EVM评估板,板上除了TMS320C549自带32K字片上内存外,还有128K字片外内存,数模转换采用TI的TLC320AD55,与PC机通过JTAG口实现数据与程序的加载和调试。
由于评估板与主机的接口速度太慢,即使能做到实时压缩,将比特流传给PC机存盘的速度也会跟不上。因此笔者采用的办法是:将原始PCM音频数据从PC机的硬盘文件加载到板上的片外内存,压缩后的数据传给PC机存盘,再加载后续文件,压缩存盘,直到整个音频文件全部压缩完,最后用C语言程序将各数据块拼成MP3文件,用软件解码程序回放。是否能达到实时要求只能通过测试每帧运行的指令数判断。
在运用快速算法计算子带分析滤波器时,考虑到DSP芯片的特点,每分解一次,要作一次加(10)式的加法,势必降低精度,另外(11)和(12)式的系数动态范围太大,精度也会受到影响,因此,只分解到16点DCT运算。
采用静态心理声学模型,心理声学模型和量化编码外循环所需的运算量就为零。代表帧的心理声学模型和缩放因子采用C语言或MATLAB语言编程计算,或者将网上下载MP3文件中的缩放因子信息破译出来加以利用,子带分析滤波器之后的MDCT全部采用长块。表1是静态缩放因子比特数和缩放因子的一种设置方案。
表1 缩放因子数据表格
缩放因子带
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
缩放因子比特数
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
缩放因子
1
1
0
0
1
1
4
5
3
7
5
3
0
3
0
1
0
7
5
0
3
另外在内循环中,首先初步选择一个全局增益使最大量化值小于码表可编码的最大值,标准推荐的作法是全局增益从小开始,每循环一次量化后,比较最大量化值,并调整一次全局增益,直到满足要求为止。本程序省去了这一循环,事先根据最大谱线值计算出应有的全局增益,作成数据表格,程序中只需根据最大谱线值查表即可。初始化全局增益确定后,要分区、量化、编码并计算编码比特数,如果比特数太大或太小都还要调整全局增益。对这一迭代循环过程,采用折半搜索的办法实现,也就是说第一次循环时全局增益取上述初始化值的一半,若编码比特数超出要求,则再取一半作为新的全局增益,否则增大一半,如此不断循环直到无法折半为止。这种折半搜索的方法比逐一搜索要快很多。
采用了这些简化、优化措施以及编程技巧,整个编码程序运算量仅需74MIPS左右,片上存储空间占用27K字左右。用标准的MP3回放软件解码,通过主观测评,音质接收CD。
由于本系统对心理声学模型进行了大量的简化,对于一般的音乐,这种简化带来的声音质量的下降并不明显,尤其是在要求不高的应用场合完全可行。但是当应用到某些编码难度较高的音频信号,例如响板时,声音质量下降较明显。因此如果采用更高运算速度的DSP,可在该编码系统中加入一个完备的或简化的动态心理声学模型,编码质量可进一步提高,至于简化的动态心理声学模型还有待进一步摸索。
上一篇:PCI总线和DSP芯片的图像处理平台的硬件设计
下一篇:高速数字串行加法器及其应用
- 热门资源推荐
- 热门放大器推荐
 模拟集成电路设计与仿真
模拟集成电路设计与仿真 ALD1706APAXXXX
ALD1706APAXXXX











 京公网安备 11010802033920号
京公网安备 11010802033920号