1 引言
Viterbi译码算法是一种最大似然译码算法,目前广泛应用于各种数据传输系统,特别是卫星通信和移动通信系统中。近年来随着FPGA技术的迅速发展,使得基于FPGA实现Viterbi译码的算法成为研究的热点。
由于Viterbi译码器的复杂性随约束长度k成指数增加,大约束度不但使Viterbi译码器硬件复杂度大为增加,同时也限制了译码速度。而其中以加比选(Add Compareselect,ACS)运算为最主要的瓶颈,的递归运算使流水线结构的应用变得困难。本文以(2,1,9)卷积码为例,用FPGA实现大约束度Viterbi译码器,其中ACS设计采用串并结合的方法来兼顾面积和速度,并用流水线结构来提高译码速度,对路径度量存储则采用同址存储方法,实现了在占用少量硬件资源的前提下,提高译码速度。
2 算法简述及系统结构分析
Viterbi译码原理详见文献[1,2],下面仅作简要说明。
图1为(2,1,9)卷积码的2个状态之间的状态转移图。根据输入路径的不同(图中实线表示输入为0,虚线表示输入为1),仅仅首位不同的两个状态可转移到仅仅末位不同的两个状态。将所有状态的状态转移图按时间往前衍生,即可得到(2,1,9)卷积码的网格(Trellis)图。Viterbi译码过程就是:根据接收序列,按照最大似然法则,分段地在网格图上计算寻找有最大度量的路径的过程。一般来说,维特比泽码器主要有4个单元所组成,其结构框图如图2所示。
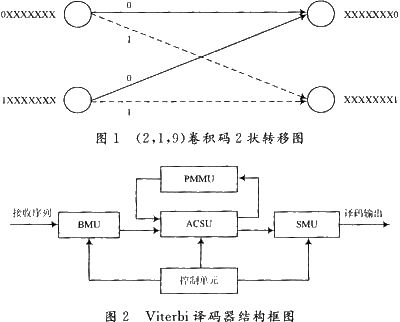
分支度量单元(BMU) 主要是计算分支度量值。所谓分支度量值就是码字与接收码之间的距离。
加-比较-选择单元(ACSU) 主要是做路径度量值与分支度量值的叠加,并决定幸存路径度量值及决定位元(decision bit)。
路径度量存储单元(PMMU) 主要用来存储幸存路径度量值。
幸存路径存储单元(SMU) 主要用来存储决定位元。
如图2所示,接收序列先通过分支度量单元计算出各状态所有分支度量,然后经过ACS单元,将上一时刻的路径度量值与当前时刻的分支度量值作加-比较-选择等运算,计算出当前时刻的幸存路径和路径度量值,并找出决定位元(decision bit),把新的路径度量值存储到路径度量存储单元(PMMU),并把相应的幸存路径的决定位元(de-cision bit)存储到幸存路径存储单元(SMU),当译码到译码深度后,判决输出单元输出译码序列。由此可见:
(1) 每计算一接收序列,所有状态的路径度量都要更新一次。若这些路径度量存储于一块RAM中,则RAM读写的次数为待译卷积码的状态数,当卷积码的约束度比较大时,对RAM的读写周期要求将会很高,很可能成为限制译码速度的瓶颈;
(2) 在ACS单元,要完成路径度量的累加,比较并选择有最大度量的路径,是算法实现的关键电路,也是硬件资源耗费最大的部分。所以ACS单元的数目太多会大大增加译码器的硬件规模,太少则影响译码速度。因此,合理安排ACS单元与路径度量RAM是提高译码速度,减少硬件消耗的关键所在。
针对问题(1),本文从改进Viterbi译码算法和路径度量RAM分块两方面同时人手。首先,表示Viterbi算法过程的网格图可以进行分解与折叠。图3所示为(2,1,9)卷积码的部分网格图的分解与折叠。可以看出折叠后,ACS计算时由读写状态路径度量,得出一步后的更新结果,变为读写四状态路径度量,得出两步后的更新结果。省去了中间路径度量的读写,减少了RAM的读写次数。

当然,这种分解与折叠很容易扩展为基8或基16的网格图,RAM的读写次数将进一步减少,但此时ACS要同时处理8个或16个路径度量,复杂性几乎成指数增加,其计算速度也可能成为新的瓶颈。综合考虑,本文采用4个基4算法,每次同时处理16个状态。在基于4个基4算法的16个状态路径度量读写中,本文将路径度量RAM分为16块,每块存储16个状态的路径度量。16块RAM并行工作时,对每块RAM的读写周期要求降为原来的1/16。
针对问题(2),综合考虑资源占用与译码速度,并兼顾基4算法的实现,决定采用4个基4蝶形单元并行工作,每个蝶形单元(ACS)串行处理16个状态的串并结合方式。
在Viterbi译码器的实现过程中,计算当前时刻的路径度量需用到前一时刻的路径度量,所以必须对路径度量加倍缓存。本文提出了一种同址的路径度量存储方法,可以减少存储单元数量,而不影响译码速度。下面将详述该方法的原理及实现过程。
3 路径度量同址存储的原理与实现
Viterbi译码器的复杂性及所需存储器容量随着约束长度K成指数增加,Viterbi译码器每解码一位信息位就需对2K-1=28=256个寄存器进行路径度量,并对相应的存储单元进行读写,这样度量路径的存储管理就成了提高译码速度的一个重要环节。
通常,计算出来的度量路径可以存储在RAM中或者是寄存器中。对于约束度很大的Viterbi译码器而言,在VLSI应用中使用RAM来存储比使用寄存器更节省芯片面积,所以本文采用RAM存储的方式。状态度量的更新有两种模式,一种是ping-pong模式,即乒乓模式,一种是同址存储模式。乒乓模式是使用两块存储器,一块存储前一时刻的路径度量,另一块则存储更新后的路径度量。当前时刻ACS从一块存储器中读取前一时刻的路径度量,然后进行加比选运算,更新完的路径度量存入另一块存储器中。这种模式的缺点是需要两块路径度量存储器,优点是控制电路比较简单。另一种同址存储模式只需要一块路径度量存储器来进行度量的更新,每一次的更新度量都覆盖前一时刻的路径度量。因此这种模式所需的存储器容量只是乒乓模式的一半。
在维特比算法中,译码状态的转移导致路径度量的读出和写人状态不同,这样在用FPGA实现时,可以用双口RAM来实现。同时,为配合4个基4蝶形单元同时读出和写入16个路径度量的需要,应将各个路径状态分组,因此,我们采用16块双口Block RAM。
根据上面分析结果,16块RAM的RAM1~RAM16分别存储状态的路径度量,这里以状态来代替其相应的路径度量。设第n时刻路径度量在各RAM的存储示意如表1所示。
(1) 从n时刻到n+1时刻路径度量更新过程如下:
首先,读表1中RAM1,5,9,13,RAM2,6,10,14,RAM3,7,11,15,RAM4,8,12,16的数据,对应第1~第4个基4;例如从RAM1,5,9,13中读取第0位的状态0,64,128,192,经过第1个基4单元运算后,得到状态0,1,2,3,存入原来的状态0,64,128,192的位置(如表2所示)。这样从第1~16位依次读取数据,经过相应的基4蝶形单元运算,写入RAM1~RAM16中相应的位置,这样,从n时刻到n+1时刻的所有状态的路径度量都得到了更新,但存储于各RAM中的状态位置发生了变化,其路径度量如表2所示。

(2) 从n+l时刻到n+2时刻的路径度量的更新
此时,读表2中RAM1,2,3,4,RAM5,6,7,8,RAM9,10,11,12,RAM13,14,15,16的数据,对应第1~第4个基4。例如读RAM1~4的第0,4,8,2位的状态0,64,128,192,经过第一个基4单元运算后,得到数据0,1,2,3,存入原来的状态0,64,128,192的位置(如表3所示)。读写的过程与写回RAM时的原理同上(同址存储),不同之处是读写RAM时的地址厕序,其读写地址如表5所示。更新后的n+2时刻的路径度量存储于各RAM的示意图如表3所示。
(3) 从n+2时刻到n+3时刻的路径度量的更新
此时,读表3中RAM1,2,3,4,RAM5,6,7,8,RAM9,10,11,12,RAM13,14,15,16的数据,对应第1~第4个基4。例如读RAM1~4的第0,1,2,3位的状态0,64,128,192,经过第一个基4单元运算后,得到状态0,1,2,3,存入原来的状态0,64,128,192的位置(如表4所示)。读写的过程与写回RAM时的原理同上(同址存储),不同之处是读写RAM时的地址顺序,其读写地址如表6所示。更新后的n+3时刻的路径度量存储于各RAM的示意图如表3所示。

同理,从n+3时刻到n+4时刻的路径度量的更新可得到如表1所示的形式。可以发现,表4运算后的路径度量在各RAM的存储结构与表1完全相同。也就是说以后的过程只是上面四步的循环而已。
本文在FPGA实现时,路径度量RAM采用了FPGA内的双口Block RAM,故可在同一时间内对存储器执行读和写操作,因此可有效地降低读写次数和提高译码速度。RAM读写地址的产生:RAM1~RAM16的读地址用查找表产生。而RAM1~RAM16的写地址分别为读地址延时1个时钟周期得到,用FPGA实现非常简单。
4 仿真与实现
根据本文提出的结构,用Verilog语言完成上述结构设计,用ModelSim 6.0a对其进行波形仿真,地址产生的波形如图4所示。
选择Xilinx spartan3为目标器件,利用ISE软件完成设计的综合及布局布线等设计流程,图5列出了XilinxISE对本设计提供的综合布线参数。

5 结 语
本文重点从FPGA实现的角度对Viterbi译码器的路径度量进行了讨论,从译码速度和硬件资源消耗两方面考虑,探讨了Viterbi译码器的优化,提出了一种串并行结构和同址路径度量存储的方法,显著提高了译码器速度和减小了电路规模,并以(2,1,9)卷积码为例给出了实现过程。该译码器通过了ModelSim 6.0a的功能仿真,并已在ISE 7.1i环境中,用Xilinx的spartan3实现。对实现的结果进行了复杂度分析,发现资源的利用相当合理,其不足之处就是连线较多。
上一篇:基于FPGA的LDPC编码器设计与实现
下一篇:数字化应用中的多核DSP
推荐阅读最新更新时间:2024-05-02 20:37

- 热门资源推荐
- 热门放大器推荐
 汽车电子硬件设计九大要素
汽车电子硬件设计九大要素






- Allegro MicroSystems 在 2024 年德国慕尼黑电子展上推出先进的磁性和电感式位置感测解决方案
- 左手车钥匙,右手活体检测雷达,UWB上车势在必行!
- 狂飙十年,国产CIS挤上牌桌
- 神盾短刀电池+雷神EM-i超级电混,吉利新能源甩出了两张“王炸”
- 浅谈功能安全之故障(fault),错误(error),失效(failure)
- 智能汽车2.0周期,这几大核心产业链迎来重大机会!
- 美日研发新型电池,宁德时代面临挑战?中国新能源电池产业如何应对?
- Rambus推出业界首款HBM 4控制器IP:背后有哪些技术细节?
- 村田推出高精度汽车用6轴惯性传感器
- 福特获得预充电报警专利 有助于节约成本和应对紧急情况




 京公网安备 11010802033920号
京公网安备 11010802033920号