有潜可挖的性能
据基于客户设计的性能基准测试显示,与前一代 Virtex-4 器件相比,Virtex-5 系列的
ExpressFabric 技术平均提高 30% 的性能,这大约相当于两个速度等级。
Virtex-5 系列是高性能设计的选择平台;其逻辑结构和硬 IP 模块可以在 550 MHz 时钟速率下运行。例如,其逻辑结构中的许多功能都有能力在这一时钟速率下运行,如计
数器、加法器以及 LUT 结构的存储器 (RAM/ROM)。硬 IP 模块(存储器和 DSP)也是为了在同样速度下运行而设计的。
ExpressFabric 技术
新型 ExpressFabric 技术以使用对角对称互连模式的 6 输入 LUT 架构和布线为基础。
6 输入 LUT 架构
查找表 (LUT)、特别功能(如进位链和专用复用器)和触发器 (FF) 的组合以及连接这
些元件的方法决定着实现逻辑及算术功能的性能和效率。
Virtex-5 系列 ExpressFabric 技术是在 Xilinx 多年经验的基础上演进的一步。自从二十世纪八十年代中期推出和生产第一款 FPGA 以来,大多数 FPGA 都是以相同的基础架构为基础,即 4 输入 LUT。过去,所有 FPGA 的一个共同特点是,需要四个以上输入的功能必须使用若干 LUT 和/ 或复用器的组合才能实现。
Virtex-5 系列是第一个提供具有完全独立(非共享)输入的真正 6 输入 LUT 的 FPGA平台。这一点带来了一些令人瞩目的优势。为了提高逻辑结构的性能,至关重要的是要通过 LUT 尽量缩短关键路径延迟。
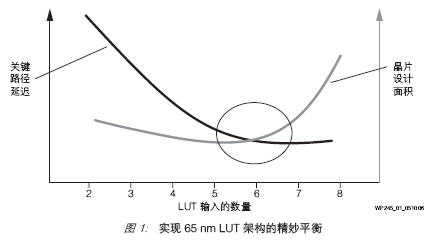
LUT 的输入架构是决定性因素。65 nm 的 6 输入 LUT 实现了关键路径延迟与晶片设计尺寸之间的精妙平衡,如图1 所示。
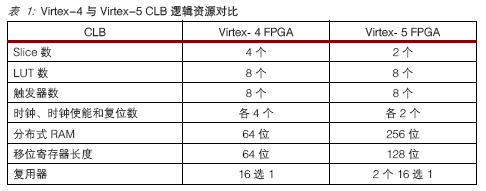
Virtex-5 系列在逻辑架构上也有所不同。表1 概述了 Virtex-4 与 Virtex-5 系列可配置逻辑块 (CLB) 之间的区别。
Virtex-4 系列的基本逻辑元件由一个 4 输入 LUT 和一个触发器及其他元件(如一个功
能扩展器和一个算术单元)组成。功能扩展器的作用是允许构建较大的 LUT 结构(如
5 输入或 6 输入 LUT)。在 RAM 模式下,Virtex-4 LUT 可实现一个 16 位存储元件和一个 16 位移位寄存器,甚至还能实现一个可以在运行中改变其内容的可加载 LUT。
Xilinx FPGA 特有的这种分布式 RAM 模式可提供效率很高的小型存储器。
与过去的 Xilinx FPGA 系列一样,Virtex-5 SLICEL 可以用专用的进位链实现逻辑功
能、寄存器和算术功能。请见图2。
稍复杂的 SLICEM 增加了用 LUT 实现分布式 RAM 和移位寄存器 (SRL) 的功能。
新型 6 输入 LUT 另有一个输出端,可用来初始化进位链或者将 6 输入 LUT 变成两个共用输入端的 5 输入 LUT。请见图3。


由于它直接在 LUT 中实现较宽的功能,使寄存器之间的逻辑级数减少,从而提高
了性能。
它实现的逻辑显著大于四输入 LUT。
较大 LUT 减少了所需互连(布线资源)量,从而降低了功耗。
Virtex-5 系列 SLICEM LUT 还提供了其他好处:
分布式 RAM 的新长宽比:每个 LUT 都可以配置成 64 x 1 或 32 x 2 分布式 RAM。
给设计人员带来的好处是,能够以高得多的密度和速度以及更大的灵活性实现分布
式 RAM。
更长的 SRL 链:一个 LUT 即可支持一个 32 位的 SRL。因此,一个 Slice 即可实现一个多达 128 位的移位寄存器,与过去的架构相比,显著节约了面积并减少了布
线资源。只有 Xilinx 器件中才有移位寄存器这种功能。Xilinx ISE? 软件封装机自
动封装两个共用寻址但不同数据的 16 位 SRL。换言之,如果应用需要,在一个
Slice 中即可实现 16 位长和 8 位宽的移位寄存器。
布线和互连架构
随着处理技术的进步,互连时序延迟可占关键路径延迟的 50% 以上。专为 Virtex-5
系列开发的新型对角对称互连模式能以较少中继段到达较多地点,从而提高性能。这
种新模式允许在 2 到 3 个中继段之内制作更多逻辑连接。而且,更规则的布线模式使
Xilinx ISE 软件可以更容易地找到最佳布线。所有互连功能对于 FPGA 设计人员都是透
明的,但却能转化为更高的整体性能和更容易的设计可布线性。从本质上说,Virtex-
5 系列的互连模式可根据距离提供快速、可预见结果的布线。
图4 比较了 CLB 中一个源寄存器引起的延迟,该 CLB 用于驱动一个 LUT,这个 LUT
与周边一个 CLB 中的另一寄存器封装在一起,其目的是衡量布线延迟增大对 Virtex-4
和 Virtex-5 系列两种架构的影响。

设计示例
下列示例详细说明了新型 6 输入 LUT 架构的优点。
复用器
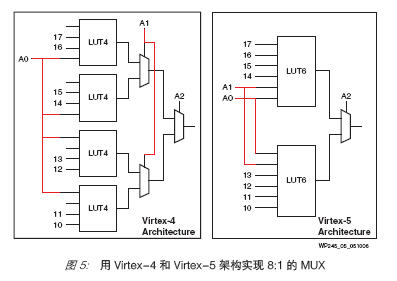
最简单的示例之一是复用器。一个 4 输入 LUT 可以实现一个 2:1 的 MUX。具有两个以上输入的每种复用器都需要额外的逻辑资源。在 Virtex-4 架构中,一个 4:1 的 MUX 需要两个 4 输入 LUT 和一个 MUXF。现在使用新型 6 输入 LUT,用一个 LUT 即可实现这个 4:1 的 MUX。在 Virtex-4 器件中,一个 8:1 的 MUX 需要四个 LUT 和三个 MUXF。
使用新型 Virtex-5 系列架构,只需要两个 6 输入 LUT,因而性能和逻辑利用率更高。请见图5。
分布式 RAM 和移位寄存器
分布式存储功能 (LUT RAM) 从几个方面受益于较大的 LUT。新的长宽比可显著提高小
型存储功能的封装密度,从而产生显著的性能效益。请见图6。

算术功能
在 Virtex-5 系列架构中实现的算术功能也有几项改进:
支持三进制加法(使用一个进位链)
复杂进位启动逻辑
用于初始化进位功能的“自由”地线或 VCC
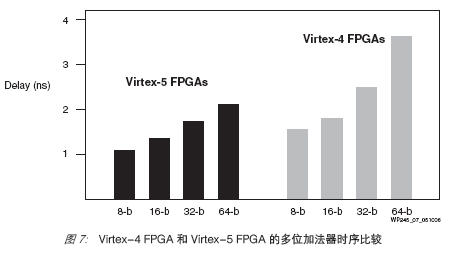
以路径延迟衡量的算术功能性能显著改善,如图7 所示。
功能模块的性能优势
表2 所示为 Virtex-4 与 Virtex-5 系列之间的逻辑和算术功能性能比较。所示特性是针对各器件系列的最高速度等级。各设计是通过 ISE 8.1i 软件运行的。

Block RAM
Virtex-5 系列的 Block RAM 基址大小已经从 Virtex-4 系列的 18 Kbit 增加到 36 Kbit。
这就使得在 Virtex-5 器件中构建较大存储器阵列更为容易。另外,可以将 36 Kb 的
Block RAM 用作两个独立的 18 Kbit Block RAM ;因此,构建多个 18 Kbit 的或更小的片上 RAM 阵列实质上不会有任何问题。
Virtex-5 系列的 Block RAM 可在简单双端口模式下运行,从而有效地加倍 Block RAM的带宽。简单双端口模式允许将 Virtex-5 系列的 Block RAM 宽度扩展到 32 位以上,每个 Block RAM 可高达到 72 位。
新型(即增强)Block RAM 的功能包括:
带有可选纠错回写功能的集成 64 位 ECC
硬编码同步 FIFO 选项
支持 FIFO 可达单块宽度 72 位
双端口总宽度可达 x36
简单双端口宽度可达 x72
Block RAM 中的新型电源管理电路:在每个 18K 的块内;如果使用 9K 或以下,
另一半自动关闭(减少约 50%)
内建级联逻辑,允许将相邻的 Block RAM 级联成一个 64Kx1 的 RAM
Block RAM 运行频率高达 550 MHz,可提供比 500 MHz 的 Virtex-4 FPGA 更高的性能水平
DSP
Virtex-5 系列采用了 DSP48E Slice,这种新型 DSP Slice 与 Virtex-4 FPGA 中的
DSP48 Slice 相比有重大提升:
增加了乘法器宽度:Virtex-5 的 DSP48E Slice 以 25 x 18 位的乘法器为基础(与
Virtex-4 器件中的 18 x 18 位形成对比)。增加到 25 x 18 位可以减少级联的级数,
从而提高总体性能和使用率。
浮点运算是使用较强乘法能力的一种应用,这种运算使用 24 x 24 位的无符号乘法
器进行单精度浮点乘法运算。两个 DSP48E Slice 构建一个 24 x 24 位无符号乘法
器,这是 Virtex-4 DSP48 Slice 所需数量的一半。支持单精度浮点运算的实际上是
两个 DSP48E Slice 所提供的 35 x 25 位能力的一个子集。在 Virtex-4 器件中,两
个 DSP48 Slice 创建一个 35 x 18 位乘法器;而四个 DSP48 Slice 创建一个 24 x 24位无符号乘法器,其中一个 24 x 24 位无符号乘法器是一个子集。
独立的 C 寄存器:在 Virtex-5 器件中,可用于 DSP48E Slice 的信号数量增加了,因而允许使用独立的 C 寄存器。这使 DSP 算法更为灵活且更容易实现。
逻辑单元的功能性:在 Virtex-5 器件中,加法器的级已经扩展到可以支持逻辑功
能。所支持的部分逻辑功能有:按位“异或”功能、按位“异或非”功能、按位“与”功能以及当第一级乘法器旁路时的按位“非”功能。
运行频率高达 550 MHz 的 DSP48E Slice:可提供比 500 MHz 的 Virtex-4 FPGA更高的性能水平。
并行 I/O
使 FPGA 实现高速内部运行只完成了任务的一半。最高系统性能需要 FPGA 与其他系
统组件之间的高性能互连。
Virtex-5 系列的 SelectIO 技术包含 Virtex-4 器件中的许多热门功能,如支持单端与差分功能的 ChipSync 技术和数控阻抗 (DCI)。
增强项包括:
每插槽 40 个 I/O:这是从 Virtex-4 器件的每槽 64 个 I/O 减少后的数量,因此可以使间隔尺寸更小。
多达 1,200 个用户 I/O:其中每个 I/O 中都有 ChipSync 技术。
ODELAY:在 Virtex-4 系列的 ChipSync 逻辑中,为便于时钟数据对齐,在所有输
入端上都提供了可编程的 IDELAY 元件。在 Virtex-5 系列中,可对模块进行编程
以提供输入或输出延迟。输出延迟对解决 PCB 偏移问题很有用。
Virtex-5 系列 I/O 的性能是单端每秒 800 Mb,差分每秒 1.25 Gb。
LVDS 带宽
借助其更高性能的差分 I/O 功能和更大的封装,Virtex-5 器件有能力实现每秒 600 x
1.25 Gb = 750 Gb 的流量。
存储器接口
每个 I/O 中内建的 ChipSync 技术使高性能存储器接口具有无与伦比的可靠性。它针对加大的设计余量提供了可调整的数据时钟校准,其分辨率为 75 ps。这种调整可以补
偿系统变化,如处理过程、电压和温度的变化。
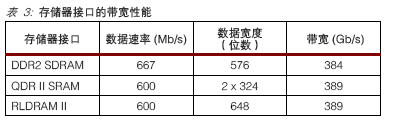
Virtex-5 器件可以为最新的存储架构实现更宽和更快的接口。请见表3。
性能增强技术
Virtex-5 FPGA 采用了一种低偏移、低抖动 的 550 MHz 差分时钟结构,从而可确保时钟与数据信号的一致性。新型时钟管理模块将针对精密时钟合成的数字时钟管理器
(DCM) 与针对减少抖动的锁相环 (PLL) 结合起来,从而显著提高了灵活性。
由 ASMBL 专利技术和大量 PWR/GND 引脚促成的稀疏锯齿形 (Sparse chevron) 封装技术和倒装芯片组装技术,实现了封装和 PCB 电感最小化,从而提高了信号的完整性。片上有源信号终端技术为最佳化调整组件互连提供了数控阻抗 (DCI),同时极大地降低了系统的组件数和成本。有关详情,请参阅白皮书 WP247 《Virtex-5 系列的先进封装》,网址是:
http://www.xilinx.com/cn/bvdocs/whitepapers/wp247.pdf。
较低的每兆赫功耗在您的功率预算内提高了性能。在利用 65 nm 技术降低动态功耗的
同时,Virtex-5 FPGA 还用三栅极氧化层技术将静态功耗降至最低。有关详情,请参
阅白皮书 WP246 《65 nm FPGA 功耗》,网址是:
http://www.xilinx.com/cn/bvdocs/whitepapers/wp246.pdf。
设计输入方法和性能基准测试
为了进一步评价 Virtex-5 系列的性能改进,我们用 ISE 软件实现了一组客户设计。最
大的改进是在具有众多逻辑级数的设计上观测到的。与 Virtex-4 FPGA 相比,新型
ExpressFabric 技术将这些设计的性能提高了高达 58%。将所有设计考虑在内,性能
平均提高了 30%,如图8 所示。

本对比中使用的所有设计都是基于 RTL (VHDL 和 Verilog)的设计。其中几个包含了
CORE Generator 软件的 EDIF 格式网表,用来实现 FIFO 和存储器。
合成过程使用了 XST,然后运行了 ISE 布局布线,其难度等级设置为 HIGH。时钟约
束以 5% 小量递增迭代收紧,直到出现负松弛。
有关如何达到最佳性能的详细信息和提示,请参阅白皮书 WP218 《在 Virtex-4 FPGA中实现性能突破》的最后部分,网址是:
http://www.xilinx.com/cn/bvdocs/whitepapers/wp218.pdf。
结论
借助其新型 ExpressFabric 技术与其他较高性能的硬 IP 模块和 I/O 的紧密结合,与上一代架构相比,Virtex-5 系列表现出了显著的性能提升。
如欲了解更多赛灵思技术文档,请访问http://china.xilinx.com/china/documentation/
上一篇:基于DDX技术的全数字功放解决方案
下一篇:使用IDELAY 实现高效8 倍过采样异步串行数据恢复
推荐阅读最新更新时间:2024-05-02 20:37

 电力工程设计手册 02 火力发电厂热机通用部分设计
电力工程设计手册 02 火力发电厂热机通用部分设计 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用










 京公网安备 11010802033920号
京公网安备 11010802033920号