定义一台抽象机器,用于描述 Mali GPU和驱动程序软件对应用程序可见的行为。此机器的用意是为开发人员提供 OpenGL ES API 下有趣行为的一个心智模型,而这反过来也可用于解释影响其应用程序性能的问题。我在本系列后面几篇博文中继续使用这一模型,探讨开发人员在开发图形应用程序时常常遇到的一些性能缺口。
这篇博文将继续开发这台抽象机器,探讨 Mali GPU系列基于区块的渲染模型。你应该已经阅读了关于管线化的第一篇博文;如果还没有,建议你先读一下。
“传统”方式
在传统的主线驱动型桌面 GPU 架构中 — 通常称为直接模式架构 — 片段着色器按照顺序在每一绘制调用、每一原语上执行。每一原语渲染结束后再开始下一个,其利用类似于如下所示的算法:
1. foreach( primitive )
2. foreach( fragment )
3. render fragment
由于流中的任何三角形可能会覆盖屏幕的任何部分,由这些渲染器维护的数据工作集将会很大;通常至少包含全屏尺寸颜色缓冲、深度缓冲,还可能包含模板缓冲。现代设备的典型工作集是 32 位/像素 (bpp) 颜色,以及 32 bpp 封装的深度/模板。因此,1080p 显示屏拥有一个 16MB 工作集,而 4k2k 电视机则有一个 64MB 工作集。由于其大小原因,这些工作缓冲必须存储在芯片外的 DRAM 中。
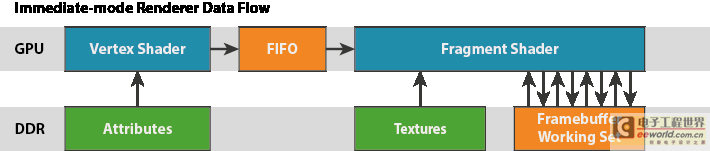
每一次混合、深度测试和模板测试运算都需要从这一工作集中获取当前片段像素坐标的数据值。被着色的所有片段通常会接触到这一工作集,因此在高清显示中,置于这一内存上的带宽负载可能会特别高,每一片段也都有多个读-改-写运算,尽管缓存可能会稍稍缓减这一问题。这一对高带宽存取的需求反过来推动了对具备许多针脚的宽内存接口和专用高频率内存的需求,这两者都会造成能耗特别密集的外部内存访问。
Mali 方式
Mali GPU 系列采用非常不同的方式,通常称为基于区块的的渲染,其设计宗旨是竭力减少渲染期间所需的功耗巨大的外部内存访问。如本系列第一篇博文中所述,Mali 对每一渲染目标使用独特的两步骤渲染算法。它首先执行全部的几何处理,然后执行所有的片段处理。在几何处理阶段中,Mali GPU 将屏幕分割为微小的16x16 像素区块,并对每个区块中存在的渲染原语构建一份清单。GPU 片段着色步骤开始时,每一着色器核心一次处理一个 16x16 像素区块,将它渲染完后再开始下一区块。对于基于区块的架构,其算法相当于:
1. foreach( tile )
2. foreach( primitive in tile )
3. foreach( fragment in primitive in tile )
4. render fragment
由于 16x16 区块仅仅是总屏幕面积的一小部分,所以有可能将整个区块的完整工作集(颜色、深度和模板)存放在和 GPU 着色器核心紧密耦合的快速 RAM 中。
这种基于区块的方式有诸多优势。它们大体上对开发人员透明,但也值得了解,尤其是在尝试了解你内容的带宽成本时:
对工作集的所有访问都属于本地访问,速度快、功耗低。读取或写入外部 DRAM 的功耗因系统设计而异,但对于提供的每 1GB/s 带宽,它很容易达到大约 120mW。与这相比,内部内存访问的功耗要大约少一个数量级,所以你会发现这真的大有关系。
混合不仅速度快,而且功耗低,因为许多混合方式需要的目标颜色数据都随时可用。
区块足够小,我们实际上可以在区块内存中本地存储足够数量的样本,实现 4 倍、8 倍和 16 倍多采样抗锯齿1。这可提供质量高、开销很低的抗锯齿。由于涉及的工作集大小(一般单一采样渲染目标的 4、8 或 16 倍;4k2k 显示面板的 16x MSAA需要巨大的 1GB 工作集数据),少数直接模式渲染器甚至将 MSAA 作为一项功能提供给开发人员,因为外部内存大小和带宽通常导致其成本过于高昂。
Mali 仅仅需要将单一区块的颜色数据写回到区块末尾的内存,此时我们便能知道其最终状态。我们可以通过 CRC 检查将块的颜色与主内存中的当前数据进行比较 — 这一过程叫做“事务消除”— 如果区块内容相同,则可完全跳过写出,从而节省了 SoC 功耗。我的同事 Tom Olson 针对这一技术写了一篇 优秀的博文,文中还提供了“事务消除”的一个现实世界示例(某个名叫“愤怒的小鸟”的游戏;你或许听说过)。有关这一技术的详细信息还是由 Tom 的博文来介绍;不过,这儿也稍稍了解一下该技术的运用(仅“多出的粉色”区块由 GPU 写入 - 其他全被成功丢弃)。

我们可以采用快速的无损压缩方案 — ARM 帧缓冲压缩 (AFBC) — ,对逃过事务消除的区块的颜色数据进行压缩,从而进一步降低带宽和功耗。这一压缩可以应用到离屏 FBO 渲染目标,后者可在随后的渲染步骤中由 GPU 作为纹理读回;也可以应用到主窗口表面,只要系统中存在兼容 AFBC 的显示控制器,如 Mali-DP500。
大多数内容拥有深度缓冲和模板缓冲,但帧渲染结束后就不必再保留其内容。如果开发人员告诉 Mali 驱动程序不需要保留深度缓冲和模板缓冲2— 理想方式是通过调用 glDiscardFramebufferEXT (OpenGL ES 2.0) 或 glInvalidateFramebuffer (OpenGLES 3.0),虽然在某些情形中可由驱动程序推断 — 那么区块的深度内容和模板内容也就彻底不用写回到主内存中。我们又大幅节省了带宽和功耗!
上表中可以清晰地看出,基于区块的渲染具有诸多优势,尤其是可以大幅降低与帧缓冲数据相关的带宽和功耗,而且还能够提供低成本的抗锯齿功能。那么,有些什么劣势呢?
任何基于区块的渲染方案的主要额外开销是从顶点着色器到片段着色器的交接点。几何处理阶段的输出、各顶点可变数和区块中间状态必须写出到主内存,再由片段处理阶段重新读取。因此,必须要在可变数据和区块状态消耗的额外带宽与帧缓冲数据节省的带宽之间取得平衡。
当今的现代消费类电子设备正大步向更高分辨率显示屏迈进;1080p 现在已是智能手机的常态,配备Mali-T604 的 Google Nexus 10 等平板电脑以 WQXGA (2560x1600) 分辨率运行,而 4k2k 正逐渐成为电视机市场上新的“不二之选”。屏幕分辨率以及帧缓冲带宽正快速发展。在这一方面,Mali 确实表现出众,而且以对应用程序开发人员基本透明的方式实现 - 无需任何代价,就能获得所有这些好处,而且还不用更改应用程序!
在几何处理方面,Mali 也能处理好复杂度。许多高端基准测试正在接近每帧百万个三角形,其复杂度比 Android 应用商店中的热门游戏应用程序高出一个(或两个)数量级。然而,由于中间几何数据的确到达主内存,所以可以应用一些有用的技巧和诀窍,来优化 GPU 性能并充分发挥系统能力。这些技巧值得通过一篇博文来细谈,所以我们会在这一系列的后续博文中再予以介绍。
小结
在这篇博文中,我比较了桌面型直接模式渲染器与 Mali 所用的基于区块方式的异同,尤其探讨了两种方式对内存带宽的影响。
关键字:OpenGL Mali GPU
引用地址:
Mali GPU: 抽象机器(二) – 基于区块的渲染
推荐阅读最新更新时间:2024-05-02 23:12
Imagination B系列GPU助力赛昉科技构建强大RISC-V生态
Imagination Technologies宣布:业界领先的RISC-V 处理器、平台及解决方案提供商赛昉科技有限公司(StarFive,以下简称“赛昉科技”)授权采用了Imagination的B系列图形处理器(GPU)知识产权(IP),以支持其最新RISC-V单板计算机(SBC)的开发。Imagination的GPU在设计之初就考虑到能够与所有处理器架构协同工作,本次两家企业的合作充分展现了Imagination对开放且发展迅猛的RISC-V生态的良好支持。 赛昉科技将在2021年1月发布的星光人工智能(AI)单板计算机的后续量产版本上加入Imagination GPU,以添加强大、灵活的图形处理性能,使该单板计算机的功
[嵌入式]
技术文章—PowerVR GPU如何优化汽车仪表盘以实现高效渲染
“只是简单的刻度盘!他们怎么能够设计的这么糟糕?”信不信由你,这个问题我已经提到过很多次了。 如果你想知道我们究竟在说什么,请看下文。 我们所谈论的是数字仪表盘上的刻度盘,我们可以在越来越多的现代汽车上找到它。自上世纪80年代首次设计出现,这种数字式仪表盘现在又重新流行起来,这是未来发展的趋势。数字仪表盘比传统的刻度盘能够提供更精确、更丰富而且更加清晰的信息。它可以是自适应的、动态的,准确的显示驾驶员在任何时刻需要看到的信息。如果得到制造商的许可,仪表盘还可以根据驾驶员的个人喜好进行定制。它们也可以看起来非常的酷炫,这在当今时代是非常重要的。 与其他数字显示器一样,这些数字仪表盘需要GPU来驱动,作为汽车领域的主要参与
[汽车电子]

国产GPU追上GTX 1080 Ti?景嘉微:等流片回来才能比
在GPU领域,AMD及NVIDIA的领先优势是其他公司无法比的,尤其是高性能显卡领域。国产GPU这两年也在快速追赶,景嘉微最新的JM9系列此前被认为可追上GTX 1080 Ti显卡,让人眼前一亮。 在最新的沟通交流会上,景嘉微公司也回应了一些热点话题,有人询问了景嘉微最新的GPU进展情况,是否可以追赶GTX 1080 Ti显卡。 对此,景嘉微方面表示,新产品还没有流片回来,性能要等流片回来,才能比较,希望在3季度能出来。 景嘉微早前提到,今年的JM9系列GPU,希望能达到2017年底2018年初的水平。 根据官方所列规格,JM9231 的性能可达到2016年中低端产品水平,而JM9271 核心频率不低于1.8
[家用电子]
抢攻游戏阵地 ARM推新款Mali GPU架构
在可携式游戏机绘图处理器(GPU)领域,除了nVIDIA、AMD、Imagination和DMP之外,安谋科技(ARM)也正在鸭子滑水抢占GPU市占率。在Mali- 200和Mali-400绘图处理架构之后,今年底前ARM也会推出下一代Mali绘图架构,可同时支持Apple积极推广的OpenCL和微软的 Direct X多媒体预算环境。 ARM目前在可携式游戏机(game handheld)绘图处理器架构的市占率约为65%,在任天堂游戏机的市占率已接近100%。在iPhone的带动下,可携式游戏机和智能型手机游戏功能的蓬勃发展备受看好。特别是具开放作业架构的Android应用框架,有助于提升多元化游戏软件的嵌入设计,
[嵌入式]
抢滩高阶GPU,ARM新一代Mali年底现身
采用安谋国际(ARM)新一代绘图处理器(GPU)架构--Mali-T658的行动装置将在年底面市。为瞄准行动装置高阶GPU市场商机,ARM推出最高可支援八核心的全新GPU核心架构--Mali-T658,并已获得富士通(Fujitsu)、三星(Samsung)、海思、新岸线以及乐金(LG)等厂商导入晶片设计。
ARM消费及移动运算市场总监Jeff Chu指出,在行动装置朝向高解析度以及重视3D影像处理的设计趋势下,GPU架构已从单核心加速迈向多核心时代。 ARM消费及移动运算市场总监Jeff Chu表示,为提升行动装置在高解析度面板、使用者介面(UI)、三维(3D)游戏以及高画质(HD)影
[手机便携]
景嘉微停牌或带来重磅消息 下一代GPU芯片将开始流片
集微网消息,在军民融合的产业趋势下,专注GPU图形处理的IC公司景嘉微核心技术正向军事中延展,或将带来重磅消息。日前,景嘉微发布公告称,经申请,公司股票于10月12日开市起停牌,预计停牌时间不超过10个交易日,公司将通过指定信息披露媒体披露本次非公开发行股票相关公告后复牌。 业内人士认为,景嘉微停牌的原因或许在于其将要策划重大事项而申请停牌,但具体策划的内容有待景嘉微正式公布。从10月12日开始停牌,景嘉微披露停牌事项或复牌最迟将在10月25日。 作为军民融合的IC企业代表,景嘉微之所以备受行业关注,是因为景嘉微无线图像传输数据链系统,已经通过无线信号传输实时视频图像和其他数据信息,可用于飞行器、舰船、地面车辆或单兵之间共
[手机便携]
VR应用GPU负担吃重 DPU出手解围
安谋(Arm)日前推出了Mali-D71、CoreLink MMU-600及Assertive Display 5这三项全新的显示解决方案。其中,Mali-D71是安谋推出的新概念方案,称为显示处理器(DPU),定位为绘图处理器(GPU)的协处理器。该处理器可支持4K 120FPS画面输出,有助于降低GPU工作量,对运算任务吃重的VR应用而言,将是一大福音。 有鉴于VR带动市场对高阶行动装置屏幕的需求逐渐上升,4K以上分辨率以及更高的帧率,衍生出不少系统效能方面的难题。对此,Mali-D71采用固定功能的硬件组件来执行迭加、旋转、高质量缩放以及其他图像处理,GPU完全不须参与这些作业,故可有效降低GPU工作量。 Arm多媒体处理器
[半导体设计/制造]
蔡崇信:中国一定能制造高端GPU芯片 不一定要用英伟达
阿里巴巴集团董事会主席蔡崇信近日接受了挪威主权财富基金投资总监Nicolai Tangen的采访。谈及芯片短缺和限制,他认为中国有能力自己制造高端GPU,并不一定要用英伟达。 对于美国收紧向中国出口芯片和相关技术,蔡崇信直言这会影响云计算和高阶运算业务,并在中短期内持续产生影响,但长远来看,中国将能够制造高端GPU。 他表示,目前中国企业的芯片存货可以支持AI大模型未来18个月的训练需求,并指出AI大模型的建立非常需要高运算能力,但在下一阶段的应用,即业界所称的“推论(Inference)”阶段,市场上有很多选择,并不一定要使用英伟达最顶级的高端芯片。 在被问及近年来投资界最热门的人工智能发展时,蔡崇信认为,中国目前落后于最顶尖的
[嵌入式]




 深度学习轻松学:核心算法与视觉实践 (冯超)
深度学习轻松学:核心算法与视觉实践 (冯超)











 京公网安备 11010802033920号
京公网安备 11010802033920号