本文是创投观察系列的第82篇
分享人:北极光创投投资经理 赵顾

编者按:近期关于AI芯片(ASIC)与FPGA的关系、地位正在业内被讨论。因此,我们也就这个话题邀请了一些业内创业者、投资人进行探讨。本文是这个系列中的其中一篇,分享人为北极光创投投资经理赵顾。以下为正文。也欢迎对这个话题感兴趣的业内人士投稿参与讨论(投稿邮箱:syq@36kr.com;投稿微信:15300063873)
回顾芯片发展史,是一部摩尔定律驱动的制程演进史,也是一部应用定义的架构演进史,所以谈起ASIC是不是会被FPGA取代,本身是一个门外汉的问题。
在摩尔定律放缓的背景下,应用场景定义的芯片架构乃至软硬件系统将更加重要。正如GPU、DSP、视频处理芯片等一波波新应用带来的专用芯片架构的变革,AI在这一波浪潮当中也会随着算法的演进和收敛,逐渐沉淀出一些更加高效的架构来,并且这些芯片架构是和场景应用软件高度融合,平衡功耗、性能、成本的设计。
计算架构主要有三个核心要素组成,包括计算,存储和网络,因此芯片种类也基本上可以按照三类来划分,这样方便理解。
首先,我们谈一谈计算芯片,Intel和ARM的CPU、nVidia的GPU、CEVA的DSP都属于这一类芯片或者IP,主要任务就是完成逻辑和数学运算,支撑了IT世界的云计算,手机终端应用和信号处理,乃至AI等等。FPGA是其中一个小门类,在整个Intel的营收当中不到5%,通常FPGA可以做到一些CPU不擅长的加速运算,比如信号处理,AI推理等场景。但是FPGA的缺点也非常明确,FPGA强调的是逻辑的通用性,支持软件改写和配置,导致计算密度是有瓶颈的,并且通用逻辑带来了大量冗余,这意味着成本和功耗的大幅度上升。在移动互联网和物联网时代,用户数和应用复杂度急剧上升,计算密度(单位功耗支撑的计算力)是核心竞争力,FPGA显然无法胜任,虽然FPGA可以在加速场景能够比CPU提升一个数量级,但是相对于专用的AI引擎又低了至少一个数量级。
有人会质疑ASIC是不是通用型不够,其实这个答案很简单,通用型和计算密度是一种折衷,比如理论上CPU是可以做任何的运算,但是通用架构带来了计算密度的损失,举个例子,最好的服务器CPU大致也只能提供1Tflops的AI推理算力;再看看GPU,轻松可以做到10Tflops,但是GPU并不能完成复杂的逻辑运算,因此它永远无法取代CPU;FPGA是介于CPU和ASIC中间的一个物种,有一定的灵活性但是性价比低,无法满足主流的需求,比如说手机行业,为了节省几美分的成本在不停的优化设计,面对如此巨大的行业,点滴的成本节省都是巨大的利益,因此FPGA的命运一直是市场早期的过渡产品或者服务于小批量的细分市场。
最近我们注意到一件有趣的事情,Intel收购了一家从事结构化ASIC设计的公司,可以基于FPGA的设计裁剪掉部分冗余逻辑加速从FPGA逻辑设计到ASIC的开发过程,从这一点也可以看出ASIC才是主流市场的终极答案。
基于这样的逻辑,北极光投资了四家AI芯片公司,分别针对云计算的登临,自动驾驶的黑芝麻,消费电子和安防的亿智,超低功耗传感器融合的Ours,这些公司分别是针对不同应用场景优化过AI引擎,未来的芯片公司不能只是生产硬件的公司,必须深刻理解用户的需求,界定灵活性的边界,才能定义出最好的产品。客户真正关心的不是通用性,否则用CPU就好了,而是满足场景需求的计算密度下的成本。
还有人质疑新兴公司抢不到产能,ASIC的目的就是用最主流和相对便宜的制程去完成FPGA用最先进制程才能做到的事情,不存在产能问题,比如说北极光投资的亿智只需要用40nm和28nm的制程就可以提供1TOPS以上的算力,成本只是FPGA的1/10甚至更低,最先进的制程适合的是通用芯片设计,但是在摩尔定律放缓的背景下,会成为一个巨大的负担。
这里也想谈下深鉴被收购的个人观点,FPGA开发者非常少,使用困难,因此自动化工具对FPGA是有价值的,深鉴的软件工具可以加速FPGA的AI开发进度,但是Xilinx是否还会继续投入AI专用芯片的研发拭目以待。作为行业老大的Intel在自动驾驶,消费,安防和云计算都有专用AI芯片的布局,包括BAT都在各自研发AI芯片,这个方向还是具有相当的共识。
我们概括一下观点,场景定义AI专用芯片和异构计算是下一个计算架构变革周期的主旋律。
其实,中国投资AI芯片公司不是太多而是太少了,真正具备产业经验的成熟团队才是投资界应该追逐和主持的标的,也是国家未来的战略资源。
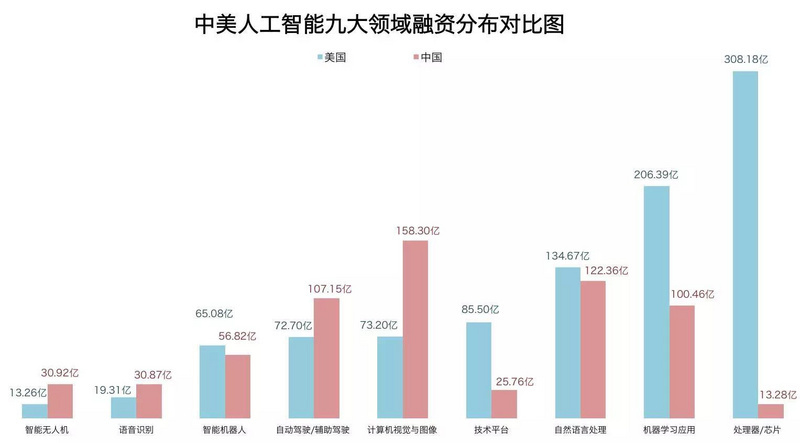
图片来自于:腾讯研究院发布的《中美两国人工智能产业发展全面解读》
上一篇:印度研制出第一款RISC-V芯片原型Shakrti
下一篇:美高森美推出高性能企业级Gen 4 PCIe控制器样品
推荐阅读最新更新时间:2024-05-03 03:09

 人工智能芯片技术体系研究综述
人工智能芯片技术体系研究综述 Electric Motor Control: DC, AC, and BLDC Motors
Electric Motor Control: DC, AC, and BLDC Motors










 京公网安备 11010802033920号
京公网安备 11010802033920号