即将在6月举行的CVPR 2019,是机器视觉方向最重要的学术会议。评选结果已经宣布,今年论文量增加了56%,与无人驾驶相关的论文和项目也是扎堆亮相。其中的一大亮点,就是以自动驾驶视觉为核心的CVPR WAD 挑战赛。
今年的挑战赛中,伯克利和滴滴将分别开放了自家的超大规模驾驶视频数据集BDD100K和D²-City,BDD100K包含10万个美国公开驾驶视频,D²-City提供中国几大城市的超过10000个视频记录。这些数据集都被标注了好了所有道路物体,以及天气、道路和交通条件等关键对象和数据,以此催生能够改变无人驾驶安全隐忧的算法。

按照伯克利的规划,这次挑战将集中在目标检测与目标跟踪任务的域适应上,并能够在中美的不同城市场景中实现自动迁移。
那么,域适应对自动驾驶的安全问题究竟有多重要?我们通过一篇文章来抢先了解一下。
论自动驾驶的倒掉与重生
在解释“域适应”之前,有必要先搞清楚,现在的自动驾驶技术都在头痛哪些问题。
尽管无人驾驶测试车的上路里程和接管数据都越来越漂亮,但对于机器学习模型来说,如何在新的、未知的环境中也能和测试道路上表现的一样优秀,这仍然是一个公开的难题。
举个例子,自动驾驶汽车可以利用在硅谷的道路测试数据集训练出一个表现良好的无人车模型。然而,同样的模型如果被部署在波士顿这样多雪天气的地区,就可能表现得很糟糕,因为机器以前从来没有见过雪。如何在差异化的环境中进行有效的自主操作,复用自己学到的经验,这仍然是机器学习的一个难点。
如果说波士顿和硅谷,由于气候和路况上的巨大差异,在一年的任何时候,都可以被系统标记为不同的域,可以通过不同的模型来解决。那么面对高度相似域,比如同样是城市街景,但北京和重庆却有着不同的道路设计,难度于是再一次升级了。
以往的解决方案是“吃一堑,长一智”。收集训练集(包括失败范例)的数据,提取特征,然后让机器依据经验误差最小准则学习分类器。但这样容易产生三个问题:
一是域之间的迁移效果不稳定。如果训练集和测试集分布一致,则模型的迁移效果较好。如果分布不一致,在源域过拟合,目标域上则表现并不让人满意。
二是有限的变化性。通过标注好的训练数据集所学会的策略,往往只能应对特定的环境和物理系统。而真实的世界常常会遇到动态变化,比如异常光线、特殊气候现象等等,这些都会改变域属性并让无人车不知所措。

三是社会舆论的高风险性。要让无人车系统从失败中吸取经验,首先,它要先犯错。但这在目前普通居民对无人车安全非常担忧的大环境下,无人车碰撞、剐蹭、识别太慢等问题都会被拿出来质疑,再采用依靠事故数据来学习如何避免错误的方法无疑是灾难性的。
显然,我们需要借助其他方法来调教无人车,来减少它在陌生环境中失败的次数。“域自适应”就是其中之一。
那么,到底什么是域自适应学习?
先解释两个关键概念:
一是源域(source domain)表示与测试样本不同的领域,但是有丰富的标注数据。比如伯克利和滴滴的驾驶视频数据集BDD100K,以及D²-City。
一个是目标域(target domain)表示测试样本所在的领域,无标签或者只有少量标签。当一辆无人车测试车从硅谷变换到波士顿的道路上,它面对的就是一个全新的目标域。
如何尽可能地复用它在源域数据集中得到的先验知识,尽可能准确地对目标域物体实现检测、跟踪等学习任务,就成为无人车模型要面临的一大问题。

我们再将任务分门别类梳理一下:
1.域适应的可能性。简单来说,就是满足哪些条件才有可能实现域自适应学习。这对模型的学习能力(算法也有学霸和学渣之分)、源域和目标域的相关性(比如硅谷和重庆的路面差异)、算法的误差界分析(源域和目标域必须同时满足最小近似误差)、学习任务的先验知识等,这四个问题的妥善解决,才能有效帮助机器进行域自适应学习。
2.鲁棒性。在域自适应学习中,训练样本和测试样本之间的分布不一致,因此导致源域上训练的模型往往不适用于目标域的学习。而域自适应学习的鲁棒性则能够度量算法对训练样本改变的敏感程度,从而克服目标域泛化误差界的“扰动”。简单来说域自适应学习模型就是一枚“暖男”,对误差的包容性更强。
3.统计估计的一致性。在确保模型可以对目标域进行学习之后,就需要解决域适应学习有效性的问题了。
这往往依赖于有效的源域和目标域的概率分布判断也就是最考验机器智商的一致性分析。使用尽可能少的样本数,实现最小的误差上界。好的域自适应性学习算法是不允许“偏科”的,泛化能力得非常强才行。

说了这么多,不难看出域自适应性学习本质上和人类的学习模式极为相似:在课堂上学习前人总结好的科学知识,然后在与现实的交流过程中不断扩充新的知识并进行探索,完成对复杂事物的认知,从而达到自主学习、适应新科目的目的。
无人车的域自适应性学习也是同样的逻辑:先利用已有的标注数据进行初始化学习,然后在大量未标注的数据中不断依据先验知识进行样本挖掘,以增量地学习模型和适配未标注数据,从而在陌生的道路环境中也能表现良好地完成学习任务。
目前看来,域自适应性学习也是完成无人驾驶视觉任务成本效益较高的方式。
新的算法还在路上
既然“域适应”对于无人驾驶来说如此重要,那么目前究竟有哪些比较值得一览的算法呢?
目前看来,由于无人驾驶任务自身的复杂性,往往需要 从多数据源向目标域进行迁移学习,这就必须考虑两个难题:
一是多种源域数据本身之间具有偏差,比如伯克利的数据集BDD100K覆盖了不同的时间、光照、天气和地理位置,甚至包含了GPS和IMU以及对应的时间戳信息;
二是多种源域数据间类别存在偏差。比如滴滴D²-City数据集中,将注释了包围框和跟踪ID的道路对象分为12个不同的类别,而伯克利的数据集BDD100K中的GT框标签则只有10个类别。
这些都对算法性能提出了不少挑战。在此,我们不妨列举几个具有代表性的算法,看看他们是如何解决无人驾驶相关技术难题的:
1.自适应曝光算法。前面提到,不同城市和路面环境的光线强弱都是不同的,为保证无人驾驶车辆在各种光线环境都能够获取可靠的道路信息,有研究人员提出了一种自适应曝光算法。利用光学传感器将采集图像转化为灰度值,并逐行进行动态阈值比对处理,快速获取下一周期正确曝光点。在道路实际的测试中,该算法能够快速并有效获取道路信息,后续的边界处理较为清晰。

2.路面障碍物检测。原理是利用已有的先验知识,比如从源域图像中学会辨识障碍物的颜色、边缘、纹理特征等等,对目标域道路上的不同车辆进行分析并快速提取出障碍物。
这方面的算法很多,比如Zielke等人利用马路边缘的对称性与显著性来提取马路边缘信息。Kuehnle等人基于图像中车轮的对称性来识别车的后轮。Crisman等人利用视觉图像中的颜色信息实现了马路跟随等等,都从不同程度提升了无人驾驶目标检测的性能。
3.多源域数据迁移算法。商汤的研究人员提出了一种名为“鸡尾酒”的网络,以解决将知识从多源域的数据向目标域迁移的问题,来帮助无人车模型更有效地识别新环境。
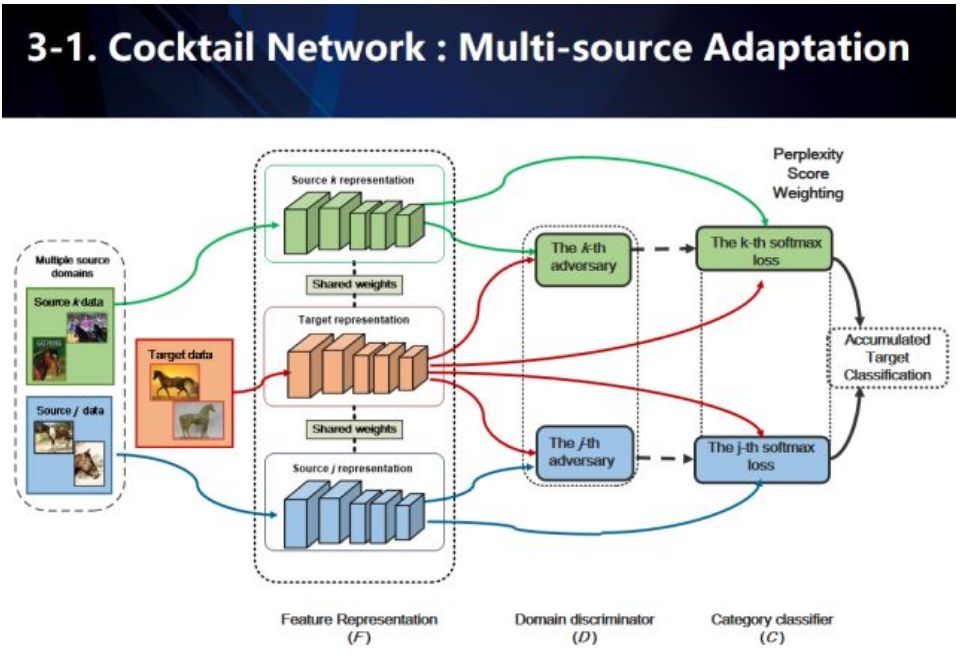
具体的做法是,利用共享特征网络,对所有源域以及目标域进行特征建模,然后利用多路对抗域适应技术(类似于GAN生成器),每个源域分别与目标域进行两两组合对抗,以此明确学习域的不变特征,极大程度地降低系统因数据偏差而对环境进行误判。
归根结底,“域自适应”方法不仅降低了训练风险,也有效地提升了系统的学习性能。从这个角度想,就更期待在CVPR 2019挑战赛中见到新的黑马了!
多说一点:
现在看到“无人驾驶”这四个字,绝大多数人会想到什么?圈内人可能会觉得“凉”,而普通民众则是“反感”。
2019第一季度刚刚过去,关于无人驾驶的负面新闻层出不穷:
去年创下融资纪录的RoadStar.ai星行科技死于内讧,成为第一家倒下的无人车公司;苹果自动驾驶部门裁员190人,无人车数量减少到62辆;有吴恩达背景的美国自动驾驶创业公司Drive.ai上个月也传出了“卖身”的消息。
产业之所以受挫,实在是因为无人车的安全性难以完全说服民众。
就在前两天,有研究人员通过在路上贴贴纸之类的“物理攻击”就让特斯拉的自动驾驶汽车并入了反向车道,甚至还能在没有车主授权的状态下用Xbox 游戏手柄操控。
即便是在无人车最为成熟的湾区,也有不少当地居民扎胎的扎胎,拿枪的拿枪,让人对无人驾驶的未来有点灰心。

而当前景变得不再明朗的时候,或许,追求技术才是最终的续命之道。
以往在计算机视觉、机器学习等领域的顶级会议中,关于域适应的研究都集中在图像分类和语义分割方面,很少看到实例级任务上的应用,如目标检测及跟踪,尽管它们对于无人驾驶来说更加重要。
当然,想要让“域适应”帮助无人车更有效的训练,只靠伯克利和滴滴在CVPR 2019中释放的数据集或某一场比赛还远远不够,还要为研究者提供更多元的支持,比如增强研究团队与车企的联系,围绕真实需求进行配套研发等等。
在此之前,这项复杂的技术还是老老实实地待在实验室和测试道路上吧。
上一篇:Elektrobit (EB) 为大众新一代电动汽车提供开发平台
下一篇:智慧城市需要关注哪些亮点?公共运输或是其中一种
推荐阅读最新更新时间:2024-05-03 03:32

 全自动驾驶汽车报告
全自动驾驶汽车报告 控制系统计算机辅助设计 — MATLAB语言与应用
控制系统计算机辅助设计 — MATLAB语言与应用










 京公网安备 11010802033920号
京公网安备 11010802033920号