1 使用VxWorks标准UDP协议栈存在的问题
在VxWorks标准的IP协议实现的前提下,其UDP协议的实现存在于IP层。在VxWorks中有一个网络任务(亦即进程),用于完成以太网包的收发处理及与各种网络协议的接口,其名为tNetTask,优先级低于一般的系统任务而高于应用程序任务。系统的上层网络协议,如Telnet、FTP等,在服务器端有一个相应的任务,处理网络任务转交过来的数据报。
应用程序想要实现UDP数据报的收发,就要使用操作系统提供的socket编程接口,主要包括创建socket,绑定socket和源IP与端口号,发送UDP数据报和接收socket中收到的内容。在VxWorks中有4个函数与之相对应,分别是:socket()、bind()、sendto()和recvfrom()。在VxWorks操作系统中,socket号是与文件打开描述符(fd)同样管理的,一个socket与源IP和一个源端口相对应。Sendto()函数调甩时指明目的的IP地址和服务端口号。
本文描述的UDP协议栈使用背景可简要描述如下:该系统使用的主要硬件CPU平台是摩托罗拉公司的MPC860的CPU,主频为50 MHz;操作系统使用美国WindRiver公司的VxWorks。系统中各个设备(均有以太网接口)之间要在以太网上进行信令与语音、数据业务的传输,各种数据包采用统一的消息头编码格式。
使用标准UDP协议栈最大的问题是效率。在该系统平台上,网络传输的速率成为最大的瓶颈,并由此影响了系统的容量。根据测试的极限速率,使用10M以太网的实际有效传输速率仅有1.8 Mb/s,使用100M以太网口电没有明显的提高。另外,还有一个问题,网络任务经常会挂起,在开机运行较长时间后此现象尤为明显,这对系统的可用性和无故障工作时间构成威胁。而项目的目标是实现高效稳定的以太网包处理。
2 改进UDP协议栈的思想与理由
根据对VxWorks操作系统的研究,发现它对以太网包的处理与一般的IP协议栈有所不同。MAC层的控制由硬件寄存器来实现,实现了发送方以太网帧的成帧和接收的以太网帧头确认以后,通过DMA方式实现内存与网络介质间的通信,网络任务与硬件之间通过设备中断进行通信。在该操作系统中,有一个MUX层,它提供统一的发送函数,其参数为发送的网络设备管理表指针和发送的数据报指针。我们知道,在一个有多个网络设备同时工作的计算机系统中,标准的IP协议栈要完成选取从哪个网络设备端口(gate way)发送和判断ARP的Cache中是否有对端的MAC地址,从而决定是否启动ARP进行解析。在VxWorks中。是通过查Route表和ARP表来完成以上两项工作的。Route表中储存的是与每一个通信的子网的gart way,ARP表中储存的是已知的IP地址与MAC地址的对应关系。另外,数据报接收的处理过程中是在IP数据报存入内存后申请MUX层的队列缓冲区,然后依次调用各上层协议的处理函数。
根据以上情况,考虑在MUX层修改UDP协议栈,在发送过程中,跳过socket接口,直接使用MUX层的发送函数。这样,可以减少从UDP层网络数据报缓冲区到MUX层缓冲区之间的复制工作,从而提高发送效率。在接收数据包的处理过程中,在MUX层收到数据报后钩挂(hook)一个处理函数,对UDP协议的数据包进行分检,优先于其他协议的处理。这样可减少从MUX层缓冲区到UDP层网络数据报缓冲区之间的复制,而且可以不再要求上层使用轮诲的方法检查socket的缓冲区中的内容,提高了处理的实时性。
3 改进UDP协议栈出现的新问题
VxWorks的muxLib类库中允许用户自己定义一个协议栈,将协议栈绑定到一个具体的网络端口上,同时要有一个处理函数对该网络设备上收到的包进行处理。加载改进后的协议栈要先创建一组缓冲区,每种缓冲区对应不同的数据报长。预先分配一大块内存,可避免发送数据包时再去分配内存,并可根据各种长度的数据报的使用频度申请不同个数的缓冲区。发送过程中,要填写IP首部的其他内容,如协议版本号、UDP协议编号、idenfication域、IP首部校验和等等。在填写的过程中,可以有意识地按照CPU的作业宽度和整数边界进行内存赋值,提高发送效率。在接收过程中,要先判断是否为UDP协议的数据报(根据第24字节为Oxll),然后做合法检验。对本协议栈处理的数据报,处理后要将其从MUX层的缓冲区队列中删除,未删除的数据报由其他协议的处理函数处理。
经过对协议栈的改进发现,在单向收发的环境下,发送效率提高了3倍左右;但是接收方效率的提高很不尽如人意,而且稳定性仍然存在问题,在运行几十小时后,网络任务的挂起现象出现得仍很频繁。关于接收方的问题,原因是:接收方的网络任务每收到一个包,从设备缓冲区搬移到应用缓冲区,然后切换到应用程序任务进行处理,处理结束以后再切换到网络任务收下一包,如果接收速度高于处理速度就会造成阻塞。下面举一个形象的例子:某个酒吧只有一个服务员,假设这个服务员要做两件事情,有顾客来的时候要到门口去给顾客开门,然后再到柜台为顾客服务,顾客依到达次序排队。假设门口和柜台之间的移动时间不能忽略,并且为顾客开门的优先级比较高,就是说如果有新顾客到来,必须先放下正在服务的顾客去开门。在这种情况下,如果顾客的到来间隔是均匀的,为每一位顾客服务要服务员跑两趟。如果顾客到达的间隔比较小,就出现服务员在门口和柜台之间频繁移动的情况。假如能使顾客分拨到达,每次有多个顾客到达,服务员就可以从柜台到门口开门让多个顾客进入,再回柜台为顾客服务。试验证明,在这种模型下接收效率能大幅提高,但是对均匀到达的顾客服务效率的提高难以得到解决。
4 深入网络设备驱动
经过对操作系统更为深入的研究发现,MUX层的发送数据包最终是通过调用网络设备驱动程序中的发送函数实现的。分析网络设备驱动的代码发现,其发送过程可描述为:
◇检查设备缓冲区(BD表)是否有可用BD;
◇根据设备缓冲区的可用情况与发送数据包的长度,判断是否需要进行分片;
◇根据设备缓冲区的可用情况决定传输发送还是拷贝发送;
◇置位设备控制寄存器,启动DMA传输,并引发设备收发中断;
◇清除使用过的设备缓冲区。
另据分析,在设备驱动的安装过程中完成的工作有:
◇根据配置数据申请内存,构建设备缓冲区表;
◇指定DMA使用的通道与工作方式;
◇配置设备寄存器(工作方式、帧类型、设备缓冲区表指针等);
◇连接设备中断处理例程。
接收过程中,是在网络设备收到数据包后启动DMA传输至内存,并引发中断,在中断处理程序中处理缓冲区指针,然后将一个函数处理指针写入一个环型缓冲区,最后是释放一个信号量,通知网络任务对收到的数据包进行处理。通过对该接收处理函数的反汇编解读,发现它的主要工作是申请MUX层的缓冲区并复制,处理设备缓冲区的指针,然后调用各个协议的处理函数。
根据以上的认识,有了一个更为大胆的设想:跳过MUX层,直接使用driver的发函数进行发送;在接收过程中,对本协议栈的数据包不再申请MUX层的缓冲区,而是直接拷贝到应用层缓冲区,并可将处理接口留给用户。另外一个想法是,直接在中断处理例程中进行处理,从而彻底抛弃网络任务。据此在百兆网络设备上完成了修改,其效率又提高将近l倍,满足了使用的要求;而且更为可喜的是,系统的稳定性大幅提高。
5 结论与数据分析
几种情况下的测试结果如下:
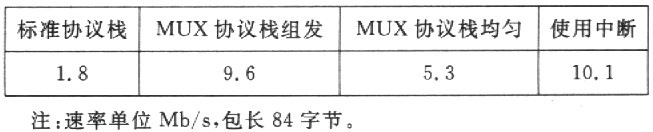
通过对上述数据的分析看出,使用MUX层的协议栈组发环境下,比使用标准协议栈发送的效率提高3倍左右,但是在均匀收发的情况下提高并不明显。直接使用中断方式克服了这一缺陷,比均匀收发的环境下又提高1倍。
但是这个测试结果只是在短包的情况下完成的,包长在100字节以下。通过对长包的测试,发现对512字节以上的长包的影响要稍微小一些。这是因为在同一速率下,使用长包调用的次数要少,改进的效果也就稍差,特别是在CPU主频更高的环境下,这一现象更为明显。
6 对实时操作系统的一点看法
通过对设备驱动的研究发现.在实时操作系统中,中断处理例程的处理时间都比较短,这也是实现实时性的一个重要思想。在改进中,中断处理例程中加入了执行代码,会影响系统的实时性,似乎违背了实时操作系统的初衷。但笔者认为,这个问题要在实际的环境下进行评价,中断中的通知网络任务与网络任务的执行,两者加起来的时间一定要比只在中断中处理需要的时间要长。这与IP包处理机的目标也是没有矛盾的,完全不必拘泥陈规。实时系统只是追求平均的响应时间较短,而在最差情况下则远低于平均水平。
上一篇:0FDM系统非线性失真自适应补偿技术
下一篇:嵌入式TCP/IP的优化设计与硬件实现
推荐阅读最新更新时间:2024-05-07 15:58

 电力系统谐波(第二版)
电力系统谐波(第二版) 零基础学电子与Arduino:给编程新手的开发板入门指南
零基础学电子与Arduino:给编程新手的开发板入门指南










 京公网安备 11010802033920号
京公网安备 11010802033920号