0 引言
在航空航天、医疗服务、地质勘探等复杂应用领域,需要处理的数据量急剧增大,需要高性能的实时计算能力提供支撑。与多核处理器相比,众核处理器计算资源密度更高、片上通信开销显着降低、性能/功耗比明显提高,可为实时系统提供强大的计算能力。
在复杂应用领域当中,不同应用场景对计算的需求可能不同。例如,移动机器人在作业时,可能需要同时执行路径规划、目标识别等多个任务,这些任务需要同时执行;在对遥感图像处理时,需要对图像数据进行配准、融合、重构、特征提取等多个步骤,这些步骤间既需要同时执行,又存在前驱后继的关系。因此,基于众核处理器进行计算模式的动态构造,以适应不同的应用场景和应用任务成为一种新的研究方向。文献[1]研究了具有逻辑核构造能力的众核处理器体系结构,其基本思想是基于多个细粒度处理器核构建成粗粒度逻辑核,将不断增加的处理器核转化为单线程串行应用的性能提升。文献提出并验证了一种基于类数据流驱动模型的可重构众核处理器结构,实现了逻辑核处理器的运行时可重构机制。文献 提出了一种支持核资源动态分组的自适应调度算法,通过对任务簇的拆分与合并,动态构建可弹性分区的核逻辑组,实现核资源的隔离优化访问。
GPGPU(General - Purpose Computing on GraphicsProcessing Units)作为一种典型的众核处理器,有关研究多面向单任务并发执行方面的优化以及应用算法的加速。本文以GPGPU为平台,通过研究和设计,构建了单任务并行、多任务并行和多任务流式处理的多计算模式处理系统。
1 众核处理机
1.1 众核处理机结构
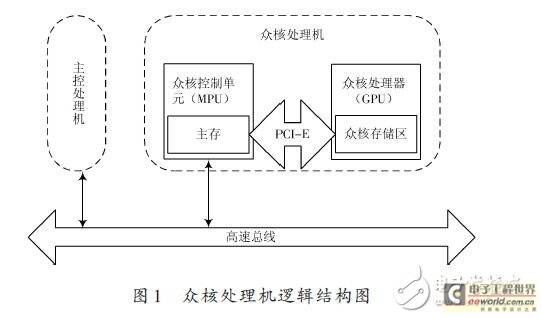
众核处理机是基于众核控制单元(MPU)与众核处理器(GPGPU)相结合的主、协处理方式构建而成,其逻辑结构如图1所示。众核处理机由众核控制单元和众核计算单元两部分组成,其中众核控制单元采用X86结构的MPU,与众核计算单元之间通过PCI-E总线进行互连。
1.2 CUDA流与Hyper-Q
在统一计算设备架构(Compute Unified Device Ar-chitecture,CUDA)编程模型中,CUDA流(CUDA Stream)表示GPU的一个操作队列,通过CUDA流来管理任务和并行。CUDA 流的使用分为两种:一种是CUDA 在创建上下文时会隐式地创建一个CUDA流,从而命令可以在设备中排队等待执行;另一种是在编程时,在执行配置中显式地指定CUDA 流。不管以何种方式使用CUDA流,所有的操作在CUDA流中都是按照先后顺序排队执行,然后每个操作按其进入队列的顺序离开队列。换言之,队列充当了一个FIFO(先入先出)缓冲区,操作按照它们在设备中的出现顺序离开队列。
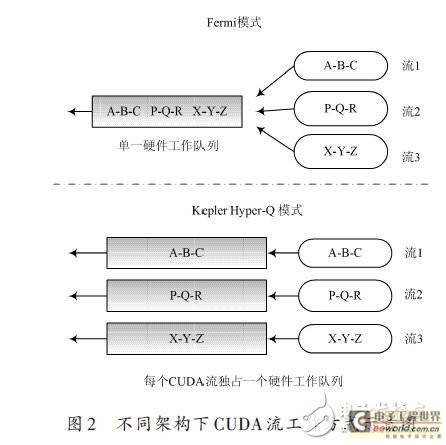
在GPU 中,有一个CUDA 工作调度器(CUDA WorkDistributor,CWD)的硬件单元,专门负责将计算工作分发到不同的流处理器中。在Fermi架构中,虽然支持16 个内核的同时启动,但由于只有一个硬件工作队列用来连接主机端CPU 和设备端GPU,造成并发的多个CUDA 流中的任务在执行时必须复用同一硬件工作队列,产生了虚假的流内依赖关系,必须等待同一CUDA流中相互依赖的kernel执行结束,另一CUDA流中的ker-nel才能开始执行。而在Kepler GK110架构中,新具有的Hyper-Q特性消除了只有单一硬件工作队列的限制,增加了硬件工作队列的数量,因此,在CUDA 流的数目不超过硬件工作队列数目的前提下,允许每个CUDA流独占一个硬件工作队列,CUDA流内的操作不再阻塞其他CUDA流的操作,多个CUDA流能够并行执行。
如图2 所示,当利用Hyper-Q 和CUDA 流一起工作时,虚线上方显示为Fermi模式,流1、流2、流3 复用一个硬件工作队列,而虚线下方为Kepler Hyper-Q 模式,允许每个流使用单独的硬件工作队列同时执行。
2 众核多计算模式处理框架
为了充分发挥众核处理器的计算能力,众核处理系统面对不同的计算任务的特点,可构建三种计算模式,即单任务并行计算、多任务并行计算、多任务流式计算。
2.1 众核多计算模式处理系统结构
众核多计算模式处理系统结构如图3 所示。众核处理系统包括数据通信、任务管理、形态管理、资源管理和控制监听模块。
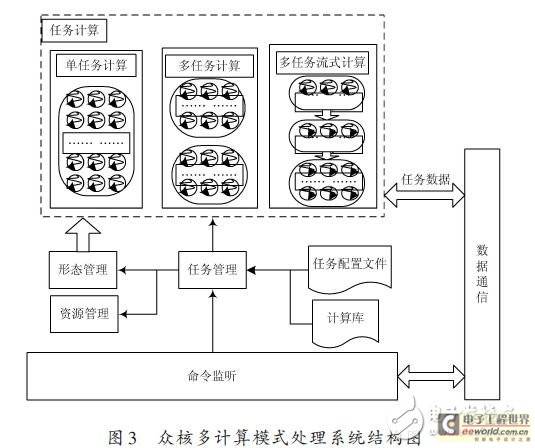
数据通信模块:提供接口给主控机,负责接收从主控机发送来的任务命令和任务计算所需的任务数据,并且最终将众核处理机运算完成的计算结果通过该模块返回给主控机。
控制监听模块:在众核处理系统运行时,实时获取主控机发送给众核处理机的任务命令,将其传送给任务管理模块,并接收任务管理模块返回的任务命令执行结果。
任务管理模块:负责计算任务的加载过程,将控制监听模块发送来的任务命令存于任务队列,当众核计算单元需要加载任务进行计算时,从任务队列中获取任务命令,根据任务命令从任务配置文件中获取任务计算所需的任务信息,该任务信息包含了计算任务运行时所需的存储空间大小、适合于该任务的计算模式、执行函数(即CUDA中的kernel函数)等内容,在计算任务在被加载前,需要通知形态管理模块把众核计算单元切换到指定的计算模式下,并通知资源管理模块分配存储空间,通过数据通信模块获取任务数据,然后读取任务计算库,加载执行函数进行计算。
形态管理模块:接收任务管理模块发送来的目标计算模式,切换到该种计算模式。
资源管理模块:根据任务管理模块发送的参数分配存储空间,包括众核控制单元的存储空间和众核计算单元的存储空间,众核控制单元的存储空间用于对任务数据进行缓存,然后通过数据传输的API接口把缓存在众核控制单元的数据传送到众核计算单元的存储空间,在计算时由从众核计算单元存储空间加载数据进行计算。
2.2 计算模式构建与切换
计算模式构建是形态管理模块根据接收到的命令动态构建出被指定的目的计算模式的过程。众核处理系统在初始化时,就已经创建了指定数目的CUDA 流(CUDA流的最大数目取决于GPU中硬件工作队列的数目),并采用空位标记法对创建的CUDA流进行管理,通过标记位的有效性描述CUDA 流的可用性。当目的计算模式为单任务计算时,只需将首位的CUDA流标记设置为有效,其他全部标记为无效,在对计算任务加载时,将计算任务放入该CUDA流中进行计算;当目的计算模式为多任务计算时,需要将指定数目CUDA流的标记位设置为有效,在对计算任务加载时,通过轮询的方式将计算任务放入到相应的CUDA 流中,利用CUDA 流的Hyper-Q特性,同时加载多个计算任务到众核计算单元;当目的计算模式为多任务流式计算时,需要将指定CUDA 流的标记设置为有效,从构建第一个计算步开始,将第一个计算步放入第一个CUDA 流中进行计算,当第一个计算步首次完成计算后,利用二元信号量通知众核控制单元中的任务管理模块开始构建第二个计算步,并重新构建第一个计算步,以此类推,完成对多任务流式计算中每个计算步的动态构建过程。
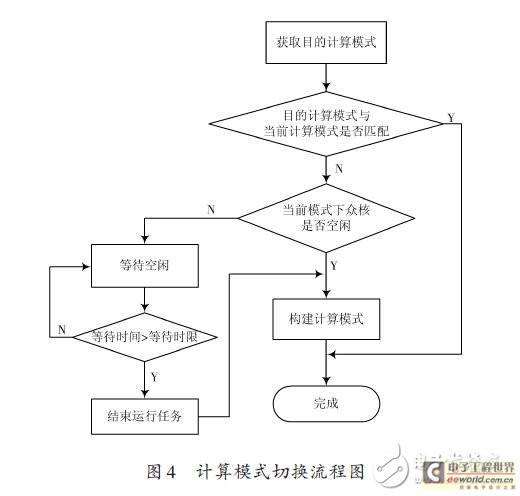
计算模式的切换是当众核计算单元的当前计算模式与计算任务执行需要的计算模式(即目的计算模式)不匹配时,需要对众核计算单元的计算模式进行切换,以适应计算模式变化的需求。
在从任务配置文件中获取适应于计算任务执行的目的计算模式后,首先与当前计算模式进行比较,若匹配成功则不需要进行计算模式的切换;若匹配失败则进一步判断众核在当前计算模式下是否空闲,如处于忙碌状态则需要等待,对于不同优先级的任务设有不同的等待时限,以保证对计算任务的及时响应,当大于这一时限时强制结束正在运行的任务以释放计算资源,从而构建新的计算模式,完成计算模的切换过程,流程图如图4 所示。
2.3 共享内存缓冲技术
众核计算单元在对主控机请求的计算任务加载前,必须获取来自主控机的任务数据,为了实现对任务数据的接收和发送,需要建立相应的数据缓冲区。传统的方法是采用消息队列和基于共享内存信号灯的方式来建立和管理数据缓冲区,但当数据的写入和读取速度差别较大时,容易造成数据缓冲区的阻塞。因此采用一种可滑动动态共享内存缓冲技术,如图5所示。
在众核控制单元的存储空间中申请存储空间作为存放数据的缓冲池,按需要建立指定数量的单向指针链表,每个指针链表代表一个数据缓冲区,在众核处理系统的计算模式切换时,可根据并行任务数目的变化修改指针链表的节点数,使每个数据缓冲区占用的存储空间按需滑动,以提高整个数据缓池数据的传递效率。
2.4 计算库动态加载
在对计算任务的执行函数进行加载时,采用动态共享库的方式,因为动态链接的共享库具有动态加载、封装实现、节省内存等优点,可以把众核计算单元的执行函数与逻辑控制程序相隔离,降低了众核计算与逻辑控制的耦合度,增加了可扩展性和灵活性。
在动态加载计算库前,需要将执行函数编译生成动态共享库,进而在程序中进行显示调用。当调用时使用动态加载API,该过程首先调用dlopen以打开指定名字的动态共享库,并获得共享对象的句柄;而后通过调用dlsym,根据动态共享库操作句柄与符号获取该符号对应的函数的执行代码地址;在取得执行代码地址后,就可以根据共享库提供的接口调用与计算任务对应的执行函数,将执行函数发射到众核计算单元,由众核计算单元根据执行函数的配置参数组织计算资源进行计算;当不会再调用共享对象时调用dlclose关闭指定句柄的动态共享库。
3 结语
针对复杂应用领域计算任务对多种计算模式的需求,本文研究了众核处理机结构,根据NVIDIA KeplerGK110架构中Hyper-Q 与CUDA 流的特性,构建了可单任务并行计算、多任务并行计算、多任务流式计算间动态切换的众核多计算模式系统,能够提高实时计算平台的灵活性,以适应不同的任务计算需求。下一步的研究方向是挖掘GPU中硬件工作链路与SM(Streaming Mul-tiprocessor)间的映射机制。
上一篇:我该选择哪一个?DSP与DSP功能的ARM
下一篇:众核多计算模式系统的构建
推荐阅读最新更新时间:2024-05-02 22:58

 电力工程设计手册 19 火力发电厂节能设计
电力工程设计手册 19 火力发电厂节能设计 控制系统计算机辅助设计 — MATLAB语言与应用
控制系统计算机辅助设计 — MATLAB语言与应用










 京公网安备 11010802033920号
京公网安备 11010802033920号