概述
近二十年来,全球半导体产业的飞速发展带动相关的软件、硬件设计达到新的水平,使得很多比较复杂的数字信号处理算法可以实时实现并且得到广泛应用。突出的代表就是数字信号处理器(DSP)与语音信号压缩编码算法相结合,并且在日常通信系统中得到广泛应用,例如数字移动电话、IP电话等。随着网络通信的发展、微处理器和信号处理专用芯片的发展,也为语音处理技术的应用提供了更加广阔的平台。所有这些因素都促进了对更加有效、可靠、高质量的语音编码系统的需要,从而促进了语音编码技术的持续发展。在最近一些年内,语音压缩编码技术有了很大的发展。最早的标准化语音编码标准是70年代CCITT公布的G.711 64kb/s脉冲编码调制PCM。此后ITU又先后公布了G.721 32kb/s自适应差分编码(ADPCM)、G.728 16kb/s短延时码本激励线性预测编码(LD-CELP)。此外还有一些政府和组织制定的语音标准,例如用于西欧数字移动通信的13kb/s具有长时预测规则码激励(RPE-LPT)的线性预测方案,北美数字移动通信标准8kb/s矢量和激励线性预测(VSELP)方案等。1999年欧洲通信标准协会(ETSI)推出了基于码激励线性预测编码(CELP)的第三代移动通信语音编码标准自适应多速率语音编码器(AMR),其中最低速率为4.75kb/s,达到通信质量。1995年ITU公布G.723.1,编码算法有两种,5.3kb/s的ACELP和6.3kb/s的MP-MLQ算法,主要用于IP电话。1996年ITU公布了G.728 8kb/s的CS-ACELP算法,可以用于IP电话、卫星通信、语音存储等多个领域。目前,ITU正在致力于制定4kb/s的语音编码国际标准,该算法将达到长途质量。针对一些特殊应用,如保密通信、军用通信、应急通信等,许多国际组织、国家也研制了各种不同速率的语音压缩编码速率,例如美国政府为保密通信用开发的2.4和1.2kb/s MELP算法。我国近几年也研制了0.6、1.2、2.4kb/s及其它速率语音压缩编码算法,达到并且超过了国外同速率编码的质量。
DSP在近20年内一直在高速发展,运算能力不断提高,片上资源和接口更加丰富,而单位运算所需功耗不断降低。下面给出几个主要厂家的DSP产品。
TI的DSP主要有四大系列:
C5000系列(定点,低功耗):适合
个人与便携上网及无线通信应用。80-400MIPS。
C2000系列(定点,控制器):针对
控制进行优化的DSP。
C6000系列(高性能):适合宽带
网络和数字影像应用。
OMAP系列(双核芯片):适合低
功耗移动设备和多媒体PDA。
ADI的DSP主要有四大系列:
21xx系列:16定点DSP,内部REM
大,外围接口多,适合作为控制类芯片使用。
SHARC系列:32位浮点DSP,21160 21161提供与大内存容量结合的简单浮点算法,具有高水平的浮点性能。
TigerSHARC系列:比SHARC具
有更高的浮点运算功能TS101,TS201
Blackfin系列:高性能16位DSP
信号处理与通用微控制器易使用的性能结合。
Motolora的DSP:
DSP56800,16BIT定点DSP,通用型DSP。
DSP563XX,24bit定点DSP, 通用型DSP。
本文将介绍使用TI公司C5000系列实现ITU-T G.729A 8kb/s CS-ACELP语音压缩编码算法,并对TI公司的TMS320C54x系列DSPITU-T G.729A语音编码算法做简单介绍,以及软件编程、调试和实现结果。

图1 C54xDSP结构框图(略)
TMS320 C54x系列DSP芯片简介及硬件设计
TMS320 C54x系列DSP芯片是使用静态CMOS技术制造的。其方框图见图1,从图中可以看出C54x系列DSP芯片具有以下功能单元:
总线
C54x共有八条总线分别是:
PB: 程序读取总线
CB: 数据读取总线1
DB: 数据读取总线2
EB: 数据写入总线
PAB: 程序读取地址总线
CAB: 数据读取地址总线1
DAB: 数据读取地址总线2
EAB: 数据写入地址总线
中央处理器(CPU)
CPU由以下几个部件组成:
先进的多总线结构: 包括三个独立的数据总线和一个程序总线
40位的算术逻辑单元: 包括一个40位移位器和两个独立的40位累加器
17bit 17bit的并行乘法器同一个专用的加法器相配合: 用来执行不经流水线的单周期乘加(MAC)运算
指数译码器: 可以在一个周期里计算出一个40位累加器的指数值
两个地址生成器: 包括8个辅助寄存器和两个辅助寄存器算术单元
程序控制器: 对指令进行解码、管理流水线和程序流程
片上存储器
C54x共有192K字的寻址能力(64K字的程序区,64K字的数据区,和64K字的I/O区)。
表1给出了部分C54x芯片的片上资源、运算能力、工作电压等。运算能力用MIPS来度量,即每秒能执行一百万条指令的数量。

片上其它资源
C54x系列中不同产品具有不同的片上外设配置。这些外设有:
软件可编程的等待状态发生器
可编程的库转换
片上锁相环时钟发生器(包括一个内部振荡器或一个外部时钟源)
一个16比特定时器
通用输入输出管脚
同步串行口
异步串行口
C54x系列DSP芯片具有以下主要特点:
采用改进哈佛结构,对程序内存和数据内存使用分离的总线。这样可以同时取指令和操作数,提高了运行效率和通用性
先进的CPU设计和为应用设计的硬件逻辑提高了芯片的性能
为快速的后续发展设计的模块化结构
先进的IC处理技术提供了高性
能和低功耗
采用5V或3V静态CMOS技术
可以进一步降低功耗
Power-down模式可以进一步降
低功耗
能源消耗控制: 使用IDLE1,IDLE2,和IDLE3指令进入Power-down模式
使用CLKOUT-off控制来禁止CLKOUT信号
高度专门的指令结构提供了快速运算和优化的高阶语言操作
单指令循环和块指令循环功能
块内存移动指令提供了更好的程序和数据管理
32位操作数指令
拥有两个或三个操作数读取能力的指令
可以并行存储和并行读取的算术指令
条件存储指令
从中断快速返回的指令 拥有多种片上外设和内存配置方案
40位算术运算器(ALU)
17bit 17bit单周期并行乘法器
六级流水线操作提高程序执行效率
支持比特倒置寻址方式和循环寻址方式。
对于语音压缩编码,通常所需要的DSP运算能力不会超过50个MIPS,程序和数据所占用的容量大约几十K字,AD/DA的精度保持就可以满足使用要求,语音输入输出、信码输入输出各需要一个双向串口。但考虑在通信领域中应用,往往一片DSP不仅要实现语音压缩编解码,还需要实现自适应回声抵消、加解密、信道编解码,甚至基带调制解调算法等。因此我们选用了TMS320VL5416设计硬件平台。AD/DA芯片采用TI公司的TLV320AIC10,它是德州仪器公司(TI)推出的一款通用型低功耗16位A/D、D/A音频接口芯片,适用于语音以及宽带音频处理。采用3.3V或5V供电,片内集成了FIR滤波器,可以达到最高88KHz的采样频率,集成了输入放大器和输出放大器,支持多路芯片串连,提供低功耗、ADC与DAC单独三种工作模式。TLV320AIC10的数字接口采用同步串口方式,可以非常方便的与DSP同步串口(McBSP)相连。FLASH采用SST39VF800A芯片,该芯片有512K 16容量,可以将多种应用程序固化在该芯片中。开机后DSP的加载程序自动将FLASH中的程序拷贝到DSP片上RAM中,以便能够全速运行程序,充分发挥DSP的处理能力。
ITU-T G.729 8kb/s CS—ACELP简介
国际电信联盟(ITU-T)于1995年11月正式通过了G.729。 ITU-T建议G.729也被称作“共轭结构代数码本激励线性预测编码方案”(CS-ACELP),它是当前较新的一种语音压缩标准。96年ITU-T又制定了G.729的简化方案G.729A,主要降低了计算的复杂度以便于实时实现,因此目前使用的都是G.729A。
G.729是由美国、法国、日本和加拿大的几家著名国际电信实体联合开发的。它需要符合一些严格的要求,比如在良好的信道条件下要达到长话质量,在有随机比特误码、发生帧丢失和多次转接等情况下要有很好的稳健性等。这种语音压缩算法可以应用在很广泛的领域中,包括IP电话、无线通信、数字卫星系统和数字专用线路。
G.729算法采用“共轭结构代数码本激励线性预测编码方案”(CS-ACELP)算法。这种算法综合了波形编码和参数编码的优点,以自适应预测编码技术为基础,采用了矢量量化、合成分析和感觉加权等技术。
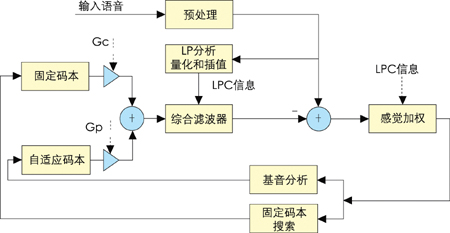
图1 G.729A编码器原理图
编码器(图1)对10ms长的语音帧进行处理,每帧分为两个子帧。输入语音首先要在预处理模块中经过高通滤波和幅度压缩变换,以去除低频干扰及防止在后面运算中出现溢出。每帧进行一次线性预测(LP)分析,并将LPC参数转换到线谱,对(LSP)形式进行预测式二阶段矢量量化(VQ)。然后使用分析合成法,按照合成信号和原始信号间感觉加权失真最小的准则来提取激励参数。激励参数(包括固定码本和自适应码本参数)要每子帧(5ms)计算一次。每帧要利用感觉加权语音进行一次开环整数基值基音延时估计,然后进行闭环的分数值基音分析,确定自适应码本的延时和增益,下面再进行固定码本的搜索。固定码本是使用交织单脉冲排列设计的代数码本。在搜索时使用迭代式深度优先树型搜索算法。这种算法的运算量比较小,并且具有固定的运算复杂度,比较有利于使用硬件实现。自适应码本和固定码本的增益使用预测式二阶段共轭结构码本进行矢量量化。
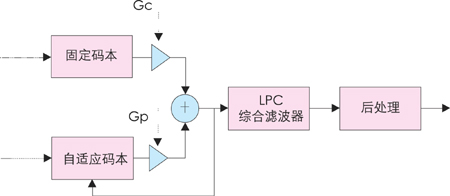
图2 G.729A解码器原理图
图2给出了解码算法的框图。首先要从接收到的码流中提取LSP系数和两个分数基音延时、两个固定码本矢量以及两套自适应码本和固定码本增益等参数。然后,对LSP参数进行插值,并转换到线性预测滤波器系数的形式。接下来,将自适应码本和固定码本矢量分别乘以各自的增益再相加,得到激励信号。激励信号通过LPC综合滤波器后,就得到了合成语音信号。最后还要对合成语音信号进行后处理,以提高合成语音的质量。
程序的编制及调试
程序编制
DSP开发工具一般都提供C编译器,可以直接将写好的C语言程序转换成DSP汇编语言程序,但效率非常低。G.729A算法C语言程序用编译器转成汇编语言程序运行所需要的运算量超过2000个MIPS(每秒百万条指令),根本无法实时运行,因此必须手工编写汇编程序。
由于编解码的程序规模很大,又是在DSP的汇编语言级别上实现,因此保持原定点C语言程序所具有的模块化、结构化的特点对于汇编程序的编写、检查、调试和阅读都是非常有利的。所以在编程时尽量保持DSP程序与C语言程序在流程上的一致,具体是使DSP程序与C程序之间保持函数一一对应关系,保持循环、分支等结构的一一对应。只有为了避免使DSP程序产生过大的不必要开销时,才对结构进行一定的修改,但仍然要保持程序的模块化和结构化。由于C程序的结构清晰,所以要想作到这一点并不困难,只要为C程序中的if、else、for、while等结构设计出相应的结构化的DSP汇编程序结构,在编程时按照这种固定对应关系对C语言程序进行转换就可以了。
程序的调试
程序的调试也是一项很费时的工作。ITU-T针对G.729A提供了8组测试码,只要通过了这8组测试码,就可以认为程序基本正确了,这8组测试码分别针对程序中的不同位置而设定如下:
algthm - 算法中的条件部分
erasure - 帧删除恢复
fixed -固定码本搜索
lsp -LSP系数量化
overflow -合成器中的溢出检查
parity -奇偶校验
pitch -基音周期搜索
speech -一般语音文件
tame -训练过程
采用的调试步骤是首先针对测试码中最短的algthm.in的第一帧边编程边调试,也就是每编好一个函数,就将algthm.in的第一帧通过该函数后的输出数据和C语言的相应输出数据相比较,并针对出现的错误修改函数内容,由于对刚编完的函数进行调试,对函数结构和指令记忆会比较清晰。这样,当编码器完成后,algthm.in的第一帧也就基本通过了。然后再继续调试第二帧,当第二帧也通过后,程序中所剩的错误也就不多了。等到通过了第10帧,就可以开始大规模地进行仿真了。对于解码部分,由于程序比较短,就采用了先把全部程序编完,再进行调试的方法。
程序的优化
编码模块与解码模块是按照G.729编解码器的C语言定点源程序改写的,虽然定点的C语言程序已经为DSP的实现作了一定的优化,但为在一个DSP芯片上实现尽量多路的编解码,必须根据C54x芯片的功能和特点对程序进行一定的优化。在编写DSP程序时,要想提高运行效率,就要充分利用C54x DSP芯片具有的各种硬件资源,并适当地对程序结构进行一定调整,采用的主要方法有以下几种:
充分利用各种延时
C54x芯片指令中的跳转、循环、调用子函数等指令都有延时的格式如B[D],BC[D],RPT[D],RPTB[D],CALL[D],CC[D],RET[D],RC[D]等,这些指令允许利用他们执行过程中的等待周期预先执行一两条其他指令,适当调整程序结构就可以充分利用这些等待周期,从而提高程序执行速度。
充分利用块指令循环功能
C54x DSP芯片还提供了块指令循环功能,此功能可以大大地提高执行循环的速度,但是此功能只能在一重循环中使用,因为它只提供了一个循环记数寄存器BRC,所以在遇到多重循环时就要尽量把这个功能用在最里层的循环中,最里层循环是执行次数最多的循环。
利用DSP芯片提供的各种寄存器
适当地利用各种寄存器也能显著地提高程序的执行速度。特别是当一个函数在程序中被频繁地调用,它的赋值可以减少执行时钟周期。
利用指令中的移位功能
C54x DSP在做赋值和数值运算之前可以自动对操作数进行一定位数的移位,这样就可以将移位运算和其它运算结合到一条指令中。另外,利用这种移位功能可以代替一些乘数为2的幂乘法,虽然有这样的限制,但是在许多滤波器和函数中确实有这样的运算,带立即数的乘法需要两个指令周期,而移位只需一个指令周期,并且如果条件允许还可以将其结合到其它指令中,从而大大节省运算量。
利用DELAY指令进行赋值操作
另外,在程序中有大量的赋值操作,即将一个内存变量的值赋给另一个内存变量。特别是在搜索码本的时候有大量的赋值操作,并且赋值的两个变量是固定的。一般的方法是将第一个变量读入到累加器或寄存器TREG中,再将累加器的值赋到第二个变量中。此过程要用两条单周期指令。C54x提供了一个移动缓冲区的指令DELAY,可以在一个指令周期内将内存单元的值复制到它后面的相邻的内存单元内。虽然DELAY指令一般是用来移动缓冲区的,但只要在给变量分配内存时将需要赋值的变量相邻分配,就可以在一个指令周期内完成赋值操作。
利用寄存器代替某些临时变量
程序中往往有很多的临时变量,有的临时变量应用到自始至终,但是有的临时变量只是在程序中的某段区域使用,只是暂时做数据存储之用,对这类变量就可以酌情使用寄存器代替。由于对寄存器可以直接进行操作,而不需要进行取数、存数操作,从而可以大大提高程序运行速度。
尽量利用寻址寄存器
C54x提供了八个寻址寄存器AR0-AR7,使用它们可以进行寻址操作,并且可以控制它们的值随着指令执行而增减。充分利用它们进行寻址可以显著提高运行速度。
实现结果
运算量统计
在对某一帧实际语音的处理过程中,编解码器算法的,各个部分运算量所占比例显示在表1中。运算量较大的部分是LSP系数的矢量量化与激励码本(自适应码本和随机码本)的搜索。这两个部分的运算量大约占全部编解码运算量的80%以上。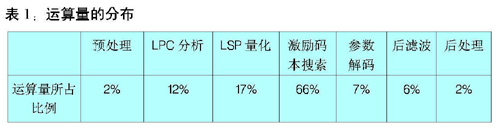
由于G.729A算法中的LSP系数的量化、自适应码本和随机码本的搜索等运算量较大的部分的计算复杂度都是固定的,对于不同的输入所用的指令周期数目只有很小的改变,所以整个编解码器的运算量也是基本固定的,在帧与帧之间只有很小的波动,基本在15MIPS附近波动,其中编码部分约占13MIPS,解码部分约占2MIPS。
储量统计
G.729a算法所用的存储量情况见表2。
编码器和解码器的存储量是分别统计的,它们有很多的共同区域,如数据区中的表格部分和程序区的公用函数部分,所以合并后的数据区和程序区总存储量应分别为约7K字。

结束语
本文介绍了采用TI公司TMS320VC5416实现ITU-T G.729A 8kb/s CS-ACELP语音压缩编码,所采用的设计思路、程序调试和程序优化的方法对用其它DSP芯片实现语音压缩编码算法也有参考意义。
上一篇:G.729A语音编码TMS320VC5416 DSP实时实现
下一篇:数字信号处理器在多媒体通信中的应用
推荐阅读最新更新时间:2024-05-02 20:24
 通信基础以及汽车总线技术概述
通信基础以及汽车总线技术概述 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用











 京公网安备 11010802033920号
京公网安备 11010802033920号