摘 要: 介绍了约束设置与逻辑综合在SoC设计中的应用,并以一款SoC芯片ZSU32的设计为例,详细讨论了系统芯片的约束设置与逻辑综合策略。
系统芯片SoC是目前超大规模集成电路设计的发展趋势,其集成度高、功能复杂、时序要求严格。逻辑综合是SoC设计不可缺少的一环,它是将抽象的以硬件描述语言所构造的模型转化为具体的门级电路网表的过程。逻辑综合的质量直接影响芯片所能达到的性能,因而在综合过程中必须根据设计要求在时序、面积和功耗方面设置正确的约束。
本文针对中山大学ASIC设计中心自主开发的一款系统芯片ZSU32,以Synopsys公司的Design Compiler为综合工具,探索了对SoC芯片进行综合的设计流程和方法,特别对综合过程的时序约束进行了详细讨论,提出了有效的综合约束设置方案。
1 时序约束原理
同步电路是大多数集成电路系统的主流选择。同步电路具有工作特性简单、步调明确、抗干扰能力强等特点。但是,因为所有的时序元件受控于一个特定的时钟,所以数据的传播必须满足一定的约束以便能够保持与时钟信号步调一致。
图1是一个典型的局部路径,它需要满足两方面的条件:防止数据太迟到达目的寄存器导致数据不能正确保存;防止新的数据过早到达导致覆盖了前一数据。

设置建立时间(setup time)约束可以满足第一个条件:
 [page]
[page]
2 ZSU32系统芯片的结构
ZSU32芯片内置32 bit MIPS体系处理器作为CPU,具备两路独立的指令和数据高速缓存,CPU内部有独立的DSP协处理器和浮点协处理器,同时集成了LCD控制器、MPEG硬件加速器、AC97控制器、SRAM控制器、NAND Flash控制器、SATA高速硬盘控制器、以太网MAC控制器等,并具有I2C、I2S、SPI、、UART、GPIO等多种接口模块。图2是ZSU32的总体结构。

3 ZSU32系统芯片的约束设置与逻辑综合
采用Design Compiler工具对ZSU32进行逻辑综合的基本流程如图3所示。
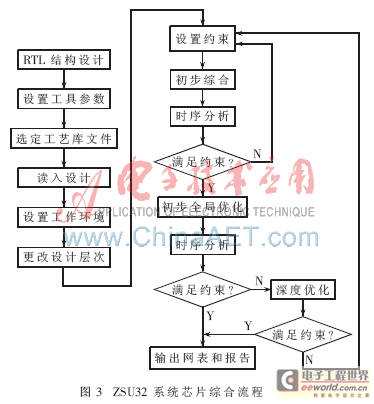
ZSU32系统芯片的综合采取自底向上的策略,先局部后整体。首先将当前工作层次设置为系统芯片的某个子模块,然后对该子模块添加各项具体约束,接着完成子模块的综合。依次对各子模块重复上述综合流程,当各个模块都顺利通过了初次综合后,通过set_dont_touch_
network命令将模块中的关键路径和时钟线网保护起来,然后做一次全局优化,检查是否满足时序等各方面的设计要求,达到要求就可以输出最终的网表和各项综合报告。[page]
3.1 设定工艺库和参考库
设置Design Compiler运行所使用的库:目标库(target_library)、链接库(link_library)、可综合库(synthetic_library)、符号库(symbol_library)。其中的目标库中包含了标准单元库、RAM单元库、I/O单元库、PLL单元库等,通常是由芯片代工厂家提供。系统芯片ZSU32采用的是中芯国际的0.18 ?滋m CMOS工艺库,所以在设置时就把目标库指向该工艺库。
#设置目标工艺库
set target_library SMIC.db
3.2 读入RTL设计与设置工作环境
读入RTL设计通常有自顶向下或者自底向上2种方式。因为ZSU32模块众多,所以采用自底向上的读入方式。首先读入各个子模块,并分别编译;然后更改层次,编译上一层的模块;最后会合成整个系统。
读入设计后,首先设置芯片的工作环境,根据采用的工艺库提供的环境和线网负载模型,可以通过set_operating_condition和set_wire_load_model命令进行设置。以下是ZSU32综合环境的顶层环境设置:
#设置工作环境
set_operating_condition smic18_typ;
#设置线网负载模型
set_wire_load_model smic18_wl30;
3.3 时序约束
3.3.1 时钟定义
时钟是整个时序约束的起点。系统芯片ZSU32将外部输入时钟和PLL模块输入时钟作为源时钟:ext_clk_i和pll_clk_i。通过对这2个源时钟信号的分频或者倍频,产生了各个子模块的时钟信号。
#定义源时钟ext_clk,周期16 ns
create_clock-name ext_clk-period\\
16 [get_ports {ext_clk_i}];
在SoC芯片内部,子模块的时钟实际是经过源时钟分频或者倍频得到的,使用create_generated_clock命令来建立子模块时钟。
#设置一个2倍频时钟clk_main,
#其源时钟是pll_clk_i
create_generated_clock -name clk_main\\
-multiply_by 2 -source pll_clk_i;[page]
3.3.2 多时钟域约束
时序检查默认以一个时钟周期为界,但对于ZSU32系统芯片,存在着一些多周期路径,在这些路径上,数据不需要在单时钟周期内到达终点。例如,clk30mhz和clk10mhz是同源的同步时钟,前者频率是后者的3倍,对从clk10mhz时钟域向clk30mhz时钟域传输数据的路径,采用如下命令:
#按照3个周期(clk30mhz)进行
#建立时间约束
set_multicycle_path 3 -setup -start \\
-from clk10mhz -to clk30mhz;
对于异步时钟域之间的路径,不用进行同步的时序检验,应该将其定义为伪路径(false path),这样在逻辑综合时就不必浪费资源去优化。
#将异步时钟e_clk和p_clk 之间的路径设置为伪路径
set_false_path -from e_clk –to p_clk;
set_false_path -from p_clk -to e_clk;
3.3.3 时钟偏移
芯片中时钟经过不同的传输路径,由于每条路经延时不一,导致从时钟源到达各个寄存器的始终输入端的相位差。这种由于空间分布而产生的偏差叫做时钟倾斜(clock skew)。此外,由于温漂、电子漂移的随机性,使时钟信号的边沿可能超前也可能滞后。这种具有时间不确定性的偏移称为时钟抖动(clock jitter)。偏移导致时钟信号到达各个触发器的时钟引脚的时间不一致,需要给予约束。
#设置时钟偏移为0.4 ns
set_clock_uncertainty 0.4 [all_clocks];
3.4 端口约束
SoC芯片通过大量输入和输出端口与外界进行信息的传输,端口约束主要用于约束顶层端口相连的片内组合逻辑,包括确定输入延时、输出延时、输出负载、输出扇出负载、输入信号跃迁时间等。
3.4.1 端口延时
输入延时是指外部逻辑到电路输入端口的路径延时。输出延时是指输出端口到外部寄存器的路径延时。图4是输入输出延时示意图。

设置范例如下:
#设置端口pci_ad13的输入延时为4.8 ns
set_input_delay 4.8 -clock clk_main \\
[get_ports {pci_ad13}];
#设置端口pci_ad16的输出延时为3.6 ns
set_output_delay 3.6 -clock clk_main \\
[get_ports{pci_ad16};[page]
3.4.2 端口的驱动与负载
端口的驱动和负载特性通过设置输入驱动单元、输入输出负载值以及信号跃迁时间等来描述。范例如下:
#设置端口a7的驱动单元是BUFX2
set_drive_cell -lib_cell BUFX2 -pin \\
[get_ports {a7}];
#设置端口d17的负载值为20 pf
set_load -pin_load 20 [get_ports {d17}];
#设置端口d0的输入信号上升时间是0.5 ns
set_input_transition -rise -min 0.5 \\
[get_ports {d0}];
3.5 面积和功耗约束
Design Compiler的综合以时序优先,即优化完约束后才根据约束优化面积和功耗。初次综合时很难对面积进行评估,所以在第一次综合时设置优化目标为0,表示在满足时序约束的情况下最大努力地减小面积。待综合报告出来之后,根据初步的面积和功耗报告,修改数值,从而进一步优化。
#面积设置
set_max_area 0;
#功耗的约束做类似的处理:
set_max_total_power 0;
3.6 综合结果
根据上述综合流程和约束设置,ZSU32系统芯片在逻辑综合后满足了时序约束,同时为后续物理设计提供了较好的起点。图5是ZSU32时序分析报告的一部分。
 [page]
[page]
从报告中看到,该路径起点是i_ZSU32_top/i_eth2_top/miim1/clkgen/U42/Y,终点是i_ZSU32_top/i_eth2_top/miim1/shftrg/ShiftReg_reg_1_,路径的时序裕量是2.96 ns。
ZSU32采用中芯国际0.18 μm CMOS标准单元库进行了逻辑综合和版图设计实现,6层金属布线,已成功流片。电路综合规模为200万门,所有cell的面积为19 195 460 μm2,芯片总面积小于5 mm×5 mm。
参考文献
[1] Synopsys.Design Compiler User Guide,Version Y-2008.06,Synopsys.
[2] BHATNAGAR H.Advanced ASIC chip synthesis using synopsys design compiler physical compiler and prime time (second edition).Kluwer Academic Publishers,2002.
[3] RABAEY J M.Anantha chandrakasan,borivoje nikolic.Digital Integrated CircuitsA Design Perspective(Senond Edition)(影印版).北京:清华大学出版社,2004,3.
上一篇:Actel FPGA现可配合加密内核对抗DPA攻击
下一篇:一种基于SoPC的低应变反射波检测系统
推荐阅读最新更新时间:2024-05-02 21:08

 电动汽车SOC估算方法
电动汽车SOC估算方法 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用










 京公网安备 11010802033920号
京公网安备 11010802033920号