DFT(离散傅里叶变换)作为将信号从时域转换到频域的基本运算,在各种数字信号处理中起着核心作用,其快速算法FFT(快速傅里叶变换)在无线通信、语音识别、图像处理和频谱分析等领域有着广泛的应用。用大规模集成电路FPGA(现场可编程门阵列)来实现FFT算法时,需要重点考虑的不再是算法运算量,而是算法的复杂性、规整性和模块化,因为算法的简单性和规整性将更适合大规模集成,更方便于版图设计,而算法的模块化更有利于FFT处理器的灵活扩展。组合数FFT算法和CORDIC(坐标旋转数字计算机)算法结合起来,在计算长点数、可扩展FFT时具有较大的优越性[1,2]。而面向高速、大容量数据流的FFT的实时处理,可以通过VLSI(超大规模集成电路)器件的并行处理或多级流水线处理等来达到。特别是多级流水线处理的FFT结构使得基于FPGA器件的FFT处理器完成不同点数的FFT计算时可以通过增减模块级数很容易地实现。
二、组合数N=r1r2点混合基FFT原理
计算N点DFT:
![]()
式中k=0,1,…,N-1。
若N=r1r2的组合数,可将n(n<N)表示为
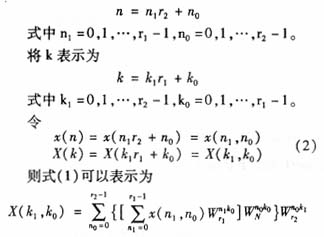
式(2)的意义在于,计算组合数N=r1r2点DFT,等价于先求出r2组r1点的DFT,其结果经过对应旋转因子的相位旋转后,再计算r1组r2点的DFT。实际应用中,DFT往往用它的快速算法FFT实现,因而式(2)中的r1点DFT和r2点DFT都用r1点FFT和r2点FFT实现。
三、可扩展FFT处理器实现结构
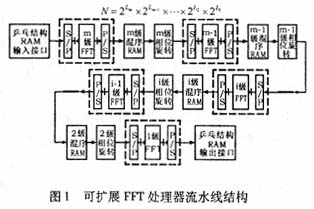
根据式(2)的FFT算法原理设计FFT处理器的可扩展结构如图1所示。
采用流水线模块化级联结构,把FFT处理器划分成短点数FFT、级间混序RAM和相位旋转等功能模块,设计的各功能模块可以重复利用,通过复用或增减各功能模块可以灵活改变FFT处理器的计算规模,而且不增加设计量。在图1结构中,当Li=1时,就演变成了基2 FFT;当Li=2时,就演变成了基4 FFT;同理,当Li≠Lj时,就演变成了高组合数的混合基FFT。
1.短点数FFT阵列结构

-Tukey算法结构实现时,有大量的复数乘法实际上转化为加减运算,所以用阵列结构实现不但具有速度快的优点,而且所用器件资源也减少很多,通过对阵列结构短点数FFT进行时分复用,可以提高运算单元的使用效率。
2.相位旋转运算单元
实现短点数FFT级间相位旋转,采用ROM存储旋转因子与数据复乘的传统方法,不仅涉及乘法运算,而且会消耗大量存储器资源。
利用CORDIC算法实现组合数FFT级间数据的相位旋转,把乘法转化成加减法运算,适合FPGA的大规模集成。可以设计出统一结构的CORDIC处理器模块,重复利用于不同级间实现相位旋转,而且其控制逻辑非常简单。
(1)CORDIC算法原理
如果旋转角度θ可以分解成n个小角度φi之和,即:
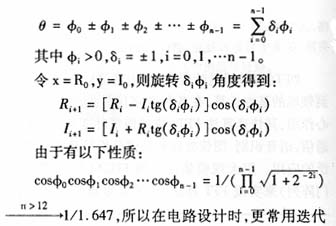
公式:

(2)CORDIC处理器结构设计
本文提出了一种流水线CORDIC处理器结构的解决方案。实现式子(4)的迭代运算时采用补码移位和补码加减运算,可以减少大量求补运算,其迭代结构如图2所示。
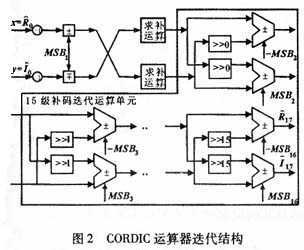

前者在于左移补零的位数的不同,这样,只需要改变n0k0的放大倍数(改变左移低位补零的位数),就可以把同一方向向量功能模块级联到图1 FFT处理器的不同级间来计算CORDIC处理器的MSBi,这就大大地减小了重复设计,其迭代结构如图3所示。
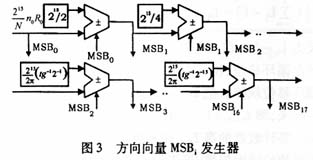
3.RAM结构及其级间数据混序用流水线读/写RAM地址发生器的设计
设计的RAM,每个存储单元为32 bit,高16位为复数的实部,低16位为复数的虚部。输入输出数据接口用RAM设计为乒乓结构,用两块相同的RAM交替读出或交替写入数据,这样就放宽了对I/O操作速度的要求,使得外围电路可以不必工作于FPGA系统时钟。
级与级之间数据混序用RAM设计为读/写RAM,对RAM同一存储单元用两个时钟完成一次读/写操作,即用流水线读/写同一块RAM来实现级与级之间的数据混序。此结构取代了用两块RAM完成数据混序的乒乓结构的传统方法,不涉及存储器之间的读写切换,控制逻辑非常简单,而且消耗的存储器资源节省一半,这是实现结构可灵活扩展的高速FFT处理器的关键和难点。可以通过理论推导,求得第i级FFT与第i-1级FFT级间混序用RAM的奇次读/写地址为

的基础上向左循环移位,位长为Li-Li-1位;同时,后者又表示在前者的基础上向左循环移位,位长为Li-Li-1位,从而形成地址的循环移位规律。把Li-1=Li和Li-1Li-1位和低Li-1位进行交替。利用此地址发生规律,可以设计基于图1结构的基2、基4等任意基x FFT以及混合基FFT级间数据混序用流水线读/写RAM地址发生器。
4.8×4×2点组合数FFT处理器的实验结果及其分析
我们利用FPGA实现的各功能模块按图1实现结构组装了8×4×2点组合数FFT处理器,通过仿真验证了其设计的正确性后,又在FPGA实验板上对它进行了硬件验证,其实验验证平台如图4所示。
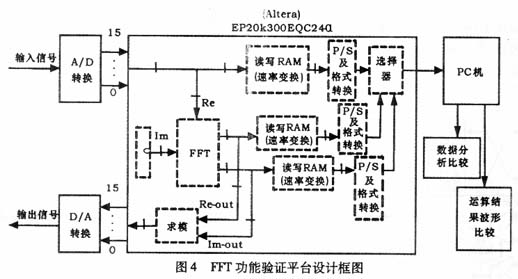
硬件验证时采取的实验方法是,用相同的抽样频率fs等间隔地抽取不同频率单频正弦信号相同点数64点,即固定FFT的频率分辨率fr,利用设计的64点FFT处理器计算其幅度谱,观察其幅度谱中直流分量谱线和谐波分量谱线间隔大小的变化,把实验结果和理论分析结果进行对照,以确认FFT处理器工作的正常与否。
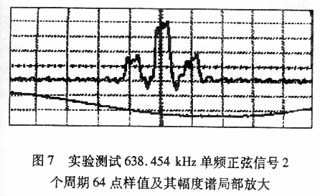
系统时钟工作在 40.861 MHz 时,抽样频率为 40.861/2=20.4305 MHz,抽样周期为1/20.4305 MHz="48".9 ns,抽取64个点的时间是48.9×64=3.13μs。因为每个采样数据间隔时间是48.9μs,所以用设计的流水线方式工作的6 4点FFT处理器计算其幅度谱的谱线间隔也为48.9 ns。当输入单频正弦信号的频率约为638.454 kHz时,其周期为1/638.454 kHz=1.567μs。用20.4305 MHz频率抽样,3.13μs时间内刚好在正弦信号的2个周期内抽取64点,输入单频正弦信号的频率是频率分辨率319.227 kHz的2倍,直流分量为幅度谱的第1根谱线,一次谐波分量为幅度谱的第3根谱线,其理论计算结果波形如图5所示,实验测试结果波形及其的局部放大波形如图6和图7所示。
从示波器上可以看出,横坐标单元格间隔为1μs,FFT变换周期间隔约为3格,即约为3μs,抽取了信号波形的2个周期,64点FFT计算时间也约为3μs。
输入单频正弦信号的频率是频率分辨率319.227 kHz的2倍,直流分量为幅度谱的第1根谱线,一次谐波分量为幅度谱的第2根谱线。由于幅度谱的谱线间隔为48.9 ns,也就是说,直流分量和一次谐波分量间隔约为100 ns。从示波器上可以看出,横坐标单元格间隔为100 ns,直流分量和一次谐波分量间隔约为100 ns,和理论分析结果一致。

四、结论
本文以高组合数混合基DFT算法为基础,设计并用FPGA实现了变换点数可灵活扩展的流水线FFT处理器。输入/输出数据速率为20 MHz时,读/写RAM工作在40 MHz时钟,计算出1 024点FFT的运算时间约为52μs。本设计采用模块化设计结构,便于系统调试和实现,而且各设计模块可以重复利用,避免重复相同的设计,从而缩短芯片设计开发时间,更易于FFT处理器的结构扩展。整个FFT设计结构新颖,实现容易,具有一定实用价值。
参考文献
[1]程佩清.数字信号处理教程[M].北京:清华大学出版社,2001.
[2]侯伯亨,顾新.VHDL硬件描述语言与数字逻辑电路设计[M].西安:西安电子科技大学出版,1999.
[3]Stephan W.Mondwurf.BENEFITS OF THE CORDIC-ALGORITHM IN A VERSATILE COFDM MODULATOR/DEMODULATOR DESIGN[A]. Fourth IEEE International Caracas Conference on Devices, Circuits and Systems[C].Aruba, April 17~19, 2002.
[4]赵忠武,陈禾,韩月秋.基于FPGA的32位浮点FFT处理器的设计[J].电讯技术,2003,43(6).
[5]Y.Ma,L.Wanhammar.A Hardware efficient control of memory addressing for high performance FFT processors[J].IEEE transactions on signal processing, 2000,48(3):917~921.
[6]J.E.Volder.The CORDIC Trigonometric Computing Technique[J]. IRE Trans. on Electronic Computers,1959,8(3):330~334.
[7]韩颖,王旭,吴嗣亮.FPGA实现高速FFT处理器的设计[J].电讯技术,2003,43(2):74~78.
[8]A.M.Despain.Fourier Transform Computers Using CORDIC Iterations[J].IEEE Trans.on Computers,1993,C-23(10):993~1001.
上一篇:CEVA在上海举办DSP与多媒体技术研讨会
下一篇:基于DSP的人体皮肤测量仪的设计
推荐阅读最新更新时间:2024-05-02 20:37

 人工智能算法(卷2)-受大自然启发的算法
人工智能算法(卷2)-受大自然启发的算法 Verilog HDL数字集成电路设计原理与应用
Verilog HDL数字集成电路设计原理与应用






- Power Integrations面向800V汽车应用推出新型宽爬电距离开关IC
- 打破台积电垄断!联电夺下高通先进封装订单
- Ampere 年度展望:2025年重塑IT格局的四大关键趋势
- 存储巨头铠侠正式挂牌上市:首日股价上涨超10%
- Vishay 推出新款精密薄膜MELF电阻,可减少系统元器件数量,节省空间,简化设计并降低成本
- 芯原推出新一代高性能Vitality架构GPU IP系列 支持DirectX 12和先进的计算能力
- NXP 2.5亿美元收购Aviva,但车载SerDes领域依然处于战国时期
- 应对 AI 时代的云工作负载,开发者正加速向 Arm 架构迁移
- 沉浸式体验漫威宇宙,英特尔锐炫显卡为《漫威争锋》提供Day 0支持
- 艾迈斯欧司朗与法雷奥携手革新车辆内饰,打造动态舱内环境




 京公网安备 11010802033920号
京公网安备 11010802033920号