0 引言
当今社会已经步入信息时代,传统的信息载体和通信方式已经无法满足人们对信息的需求。而实验表明:相比较语音和抽象数据,人类接受的信息更多是以图片和视频方式为载体的。其中视频信息具有直观、具体和高效的特点,这也就决定了视频通信技术将成为信息时代的重要技术之一。
由于视频的数据量巨大,而存储视频的资源通常是非常有限的,因而对视频进行压缩编码,以减少存储资源的消耗,非常必要。然而,通常情况下,使用的压缩算法的复杂度越高,压缩比率越高,视频播放时的解码速度就会越低。因而在提高编码压缩率的同时,也需要对解码器进行相应的优化,以提高视频解码器在目标平台上的性能。本文就实现了ffmpeg解码器在龙芯3B上的移植与向量化,提高了该解码器在龙芯3B上的性能。
1 视频编/解码与龙芯3B
1.1 视频编/解码
目前,成熟的压缩编/解码方法有很多。其中H.261、MPEG-1、MPEG-3和H.263采用了第一代压缩编码方法,如预测编码、变换编码、熵编码以及运动补偿;而MPEG-4和H.264采用了第二代的压缩编码方法,如分段编码和基于模型或对象的编码等。
视频压缩编码的主要目的是减少存储视频所占用的资源,而解码技术的目标则是提高解码的速度,从而提高视频播放的流畅性。常见的基于H.264编码方法的软解码器包括CoreAVC、ffmpeg和JM等。其中JM是H.264官方网站提供的编/解码器,集合了各种编/解码算法,而且代码的结构清晰,很适合应用于对视频编/解码技术的研究。而CoreAVC解码器则主要用于商用,其解码速率比ffmpeg快50%以上。ffmpeg是开源的解码器,而且性能相对较好,很多开源项目都直接或间接地使用了ffmpeg,如mplayer播放器等。通过对性能以及开源特性的综合考虑,本文选择ffmlpeg作为移植和向量化对象。
1.2 龙芯3B体系结构
龙芯3B处理器在兼容了MIPS64指令集的同时,实现了针对多媒体应用的向量扩展指令,这对视频编/解码应用性能的提升有很大的帮助。
龙芯3B提供了256位的向量寄存器并实现包括256位向量访存在内的向量扩展指令。使用向量指令可以一次完成32个字节宽度数据的操作。而这样的结构和指令集设计,使得龙芯3B非常适合于实现大规模相同类型数据的相同运算,比如矩阵乘法运算和FFT运算,以及视频编/解码运算等。
不过由于ffmpeg并未实现对龙芯3B平台的支持,因而需要完成ffmpeg到龙芯3B的移植工作。本文之前也有一些ffmpeg到其他平台的移植工作和针对龙芯平台的移植与优化工作,都取得了不错效果。
2 基于龙芯3B的ffmpeg移植
2.1 ffmpeg的移植
ffmpeg解码器提供了对不同目标平台的支持,而与这些平台相关的文件都保存在以该目标平台命名的目录下。例如,ffmpeg解码器实现了对arm和sparc平台,以及x86平台的支持。
对于实现ffmpeg解码器对龙芯3B的支持,主要完成以下5个步骤:
(1)修改configure配置文件,增加与龙芯体系结构相关的配置选项;
(2)新建龙芯专用文件夹godson,将龙芯体系结构相关的文件都存放于该文件夹中;
(3)将godson文件夹下新增的需要编译的文件添加到Makefile中;
(4)增加与dsputil_init类似的新的初始化函数dsputil_init_godson;
(5)在头文件中添加新增函数的声明。
针对龙芯3B的ffmpeg移植工作相对比较简单,因而本文重点介绍针对龙芯3B的向量化工作。
2.2 移植后的ffmpeg的性能比较
本节对移植后的ffmpeg解码器进行了性能测试,对使用龙芯3B向量扩展指令和不使用龙芯3B扩展指令两种情况下的性能进行了比较。测试时使用支持龙芯3B扩展指令集的GCC编译器进行编译,并且开启-ftree-vectorize和-march=godson3b编译选项来支持龙芯 3B扩展指令。使用的测试用例为视频“walk_vag_640x480_qp26.264”,测试结果如表1所示。
从表1的测试结果中可以看出,使用龙芯3B的向量扩展指令可以提高ffmpeg解码器在龙芯3B上的性能,用来测试的视频的解码时间减少了约466s。尽管如此,由于GCC编译器本身自动向量化能力的限制,ffmpeg解码器的性能提升还是比较有限的,因而针对龙芯3B的指令集对移植后的ffmpeg解码器进行向量化,就成为了进一步提高性能的重要工作。

3 ffmpeg的向量化
3.1 ffmpeg的oprofile测试
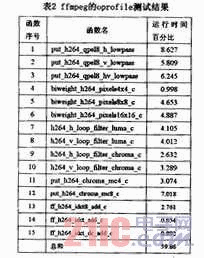
使用oprofile对ffmpeg解码视频“问道武当002.mkv”的过程进行测试,测试结果如表2所示。表2列出了各个函数的调用过程以及运行时间所占的比重。而针对ffmpeg解码器进行的向量化工作,则主要是针对oprofile测试结果中执行时间较长、运行比重较大的几个函数的向量化。
[page]
上述函数的执行时间几乎占据了ffmpeg解码器执行时间的60%,因而针对上述几个函数进行向量化,就完全可以达到提升ffmpeg整体解码速度的目的。
3.2 针对龙芯3B的ffmpeg向量化
3.2.1 向量化方法
实现ffmpeg解码器在龙芯3B上的向量化主要是使用龙芯3B扩展的向量指令来改进3.1节中oprofile测试结果中执行时间比重较大的几个函数。而且在向量化的同时,同样可以使用一些优化策略,来提高向量化后的函数的性能。主要使用到的优化方法包括:
(1)循环展开。循环展开是一种循环变换技术,将循环体中的指令复制多份,增加循环体中的代码量,减少循环的重复次数。需要说明的是,循环展开本身并不能直接提升程序的性能。
使用循环展开的主要目的是充分挖掘指令或者数据间的并行性。其中向量扩展指令的使用就是利用了展开后的循环体内数据的并行性;而在展开后的循环内使用指令调度和软件流水技术则是为了充分利用指令间的并行性。
(2)指令调度。循环展开后的循环体内的指令数目增多,因而可以进行指令调度,将不存在操作数相关性和不存在运算部件相关性的指令调度到一起,这样可以充分发挥龙芯3B的流水线性能,从而提高代码在龙芯3B上的执行速度。
除了使用龙芯3B的向量扩展指令和使用上述两种优化方法以外,同样还可以根据具体函数的特点,使用其他一些优化方法进行优化,比如使用逻辑运算和移位运算来代替乘法运算等。针对每个函数的向量化优化在3.2.2小节中介绍。
3.2.2 针对具体函数的向量化
3.2.1小节概述了向量化时用到的一些优化方法,本节则针对oprofile测试中比重较大的几个函数进行有针对性的优化。
对于表2中的函数,我们可以根据函数名将其分类,函数命名类似的函数基本上都可以使用类似的优化方法。
(1)简单向量化。对于1号和2号函数的优化,本文都采用了使用移位运算来代替乘法运算的策略,并且针对循环内部运算的有界特性,使用饱和向量运算来改进。不过对于2号函数的访存操作,由于存在着数据非对齐的情况,因而使用额外的向量指令对数据进行打包和回写。而3号函数则是1号和2号函数的混合,因而对1号和2号函数的优化间接提升了3号函数的性能。
而对于4号、5号和6号函数,本文仅对其内层循环使用了循环展开和指令调度策略,就能够取得不错的运算效果。
同样,对于11和12号函数也可以比较直观的进行向量化,在此就不做详述了。
(2)间接向量化。而对于比较难于向量化的7号和8号函数,本文分别采用了使用掩码和使用矩阵转置运算的策略来间接实现向量化。
其中针对函数h264 v loop filter luma的C语言实现中有很多判断语句的问题,本文使用构建掩码的方式来消除这些判断语句。

以图1(a)中的循环为例介绍掩码的构建。而图1(b)所示为代替该循环的向量指令。具体的运算结果如图1(c)所示:将p向量(数组)和q向量做饱和减法(结果为负的都置为0),得到的结果向量如Vsub所示。使用Vsub与零向量进行比较来设置掩码:结果为真,掩码值为0xFF;反之,结果为假,掩码为0。最后将掩码值与p向量进行与操作,就可以得到该循环的运算结果。
使用构建掩码的方法来消除判断语句,不但减少了由判断引起的时间开销,而且重要的是间接将循环进行了向量化,提高了函数性能。而对于9号和10号函数,可以使用同样的方法来改进。
而对于8号函数,由于运算处理的是连续的数据,因而无法进行向量化。使用矩阵转置的方式,将数据重新打包后,就可以进行相应的向量运算。

对于图2(a)中的运算,原始计算是P向量内部的运算,因而无法向量化,我们用向量指令将p向量转置为q,其中q0存放p中标号为1的数据,q1存放P中标号为2的数据,依此类推。转置得到的q向量就可以用图2(b)中的向量指令运算,得到的运算结果与原来的运算相同。
[page]
对于13~15号函数的优化,同样使用到了上面的转置方法。而4.1节的测试结果则说明了各个函数的优化效果。
4 实验结果
4.1 ffmpeg各函数加速比
本文分别对向量化后的各个函数进行了测试,并且与未向量化之前的函数进行了比较,各个函数向量化优化后的加速比如图3所示。其中图中横坐标所示函数序号与表2中的各个函数一一对应。
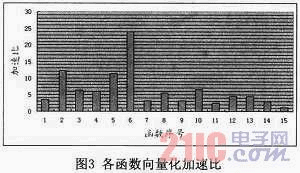
图3中的函数的加速比所跨越的范围较大,比如6号函数的加速比约有23.9左右,而最后一个函数的加速比只有1.2左右。之所以会出现上述情况,除了与改进后的函数所使用的向量指令的数量和修改代码的比重有关以外,也与运算所使用的操作数的类型有关。对于6号函数,其循环内的运算所使用的操作数的类型为字节类型,因而仅仅使用向量指令进行优化,理论加速比就可以达到32,不过本文仅仅对该函数的内层循环进行了向量化,而向量化后的内层循环一次仅仅处理了 16个字节类型的数据,即并未充分使用256位的向量寄存器。因而理论的加速比应该为16,但是由于结合了循环展开和指令调度等其他优化策略,因而实际的加速比可以达到23.9左右。同样,对4号、5号和6号这三个同类型的函数进行分析,我们也可以发现:后一个函数的加速比均约为前一个函数加速比的两倍。这是因为对于4号函数,内层循环向量化后一次可以同时计算4个字节类型的数据,而5号函数可以同时计算8个字节类型的数据,因而理论上的加速比也应该是两倍的等比数列形式,而实际结果与理论分析是一致的。
对于3.3.2小节中重点介绍的7号函数和8号函数,其原函数无法进行简单向量化,而本文使用了掩码以及矩阵转置等优化方法,使其能够使用龙芯3B的向量扩展指令,因而尽管性能提升不大,但是加速比也分别有3.2和5.5。
4.2 不同平台上的向量化比较
本文同样将ffmpeg解码器分别在不同的平台上进行了测试,使用的两个测试视频分别为是“问道武当002.mkv”(视频A)和“walk_vag_ 640x480_qp26.264”(视频B)。其中视频A是问道武当视频(720p)中截取的片段,而后者是通过x264对walk_vag.yuv(480p)编码生成的,编码时选用的qp值为26。而测试平台则分别选择了AMD和Intel处理器平台。

从表3的测试结果可以看出对于视频A,在龙芯3B上的性能提升比其他两个平台上都高很多;而对于视频B,在龙芯3B上的性能提升也与其它两个平台接近。实验结果表明:在龙芯3B上实现ffmpeg解码器的向量化,对性能提升有很大帮助,而且解码某些视频时,性能的提升甚至高于性能优越的商用处理器。而通过与表1中使用GCC向量化编译的结果进行比较,也可以看出:手工对ffmpeg解码器进行向量化比使用GCC进行向量化,性能有更大的提升。
5 总结和展望
本文实现了ffmpeg解码器到龙芯3B的移植,并针对龙芯3B实现了对向量扩展指令支持的特点,对ffmpeg解码器进行了手工向量化。实验结果表明:手工向量化后的ffmpeg解码器的性能比使用GCC向量化编译后的ffmpeg解码器性能要好很多,而且性能的提升也比Intel和 AMD平台更多。
本文仅仅从代码级实现了针对龙芯3B的ffmpeg解码器的向量化移植,为了进一步提高性能,还需要从整个算法层面上进行优化。另外,由于龙芯3B的多核特性,还可以考虑使用多核进行解码。
上一篇:基于微控制器的数控DC电流源系统设计
下一篇:基于Blackfin533的CCSDS图像压缩算法编码优化
推荐阅读最新更新时间:2024-03-16 10:55

 机器学习实战:基于Scikit-Learn、Keras和TensorFlow:原书第2版
机器学习实战:基于Scikit-Learn、Keras和TensorFlow:原书第2版 嵌入式网络那些事:LwIP协议深度剖析与实战演练
嵌入式网络那些事:LwIP协议深度剖析与实战演练










 京公网安备 11010802033920号
京公网安备 11010802033920号