长沙智能驾驶研究院产品研发总监 黄英君
Apollo集中运行感知、决策、控制模块,对资源、实时性、可靠性需求是不同的,对计算平台、操作系统、运行环境的要求也各不相同。黄英君将这些模块进行解耦,分布式集成运行在不同的计算平台和操作系统上,即在一个高可靠的双机备份低成本平台上运行决策与控制模块,在多个低成本高性能技术平台上运行感知模块,实现一个分布式可扩展的解决方案。
以前要搭建Apollo开发平台的初期投入不菲,至少需要几万元。根据他提供的低成本方案,只需5000元左右(最新的价格是教育机构299美元),就能搭建起Apollo的开发平台,大大降低了自动驾驶开发的门槛。(提示:目前还只是能够部署,让Apollo的所有模块跑起来,还无法做到很流畅的实时的跑,这里有待大家一起去努力完善)。
以下是分享的全部内容。
作为一名普通的开发者,我在接触Apollo几个月的时间里,一直把Apollo作为学习的平台和工具。
首先Apollo代码更新很快,但是最近一次大规模的更新是在3月25日左右,后面几天发现有十几个到二十几个文件在更新---建议大家每天早上上班之后先查看GitHub一下。
第一个值得关注的文件是perception_lowcost.sh,这个名字非常有意思,脚本内容如下:
1 | run perception "$@"--flagfile=modules/perception/conf/perception_lowcost.conf |
这个加载了一个配置文件,打开后发现:
1234567 | #Camera node subnodes { id: 3 name: "CameraProcessSubnode" reserve: "device_id:camera;" type: SUBNODE_IN } |
上面这个subnode是新增加的摄像机节点;原来的配置文件中的两个信号灯摄像机节点、激光雷达节点都没有出现:
12345678910111213141516171819 | #TrafficLight Preprocess node.subnodes { id: 41 name: "TLPreprocessorSubnode" type: SUBNODE_IN } #TrafficLight process node.subnodes { id: 42 name: "TLProcSubnode" type: SUBNODE_OUT } #64-Lidar Input nodes.subnodes { id: 1 name: "LidarProcessSubnode" reserve: "device_id:velodyne64;" type: SUBNODE_IN } |
关于这几个摄像机,我们可以在驱动目录里面查看更详细的信息:
2.0版本有两个摄像机。打开目录:pollo\modules\drivers\usb_cam\launch的start_leopard.launch文件,定义了三个摄像机。
123 |
前两个是用来针对交通信号灯的,第三个针对障碍物,推测这个摄像机就是用来检测障碍物的。
打开源码perception目录,有一个camera目录,这个目录变化最大,也是开放代码量最多的一个目录,增加了车道线功能。我们是不是就可以得出结论,第三个摄像机将是执行障碍物检测和车道线检测。
综上所述,最新版本的Apollo,特别强调低成本,具体的方式是在高速场景下弱化了弱化了激光雷达和两个信号灯检测摄像机,增加了一个摄像机,专门执行障碍物检测和车道线检测。这个变化跨度非常大,一个激光雷达的价格就是70多万(64线),可以说是非常大的一个跨越。
另外说一句题外话,Apollo这个代码写的特别好,写代码的是很资深的架构师,所以Apollo这套代码有非常浓重的谷歌风格,并使用了大量的谷歌系工具,看它的架构非常舒服的,可以作为一个经典的大型c++工程demo,来学习他的c++编程和大型项目的构建。为什么考虑对Apollo进行分布式扩展?
为什么考虑对Apollo进行分布式扩展?
为什么考虑对Apollo进行分布式扩展?因为去年9月份我安排一个实习生,他开始做了几天,就说目录挺多,但是总装不上。后来我发现坑越来越多,问题越来越多。
去年9月份我们订购了PX2,但却缺货。后来代理商把他们自己的一块给我们用了,左边是Apollo推荐的计算平台,是台湾一家公司的,这个工控机非常小巧和紧凑,它的散热做得非常好,但是价格还是有点贵,而且订货周期比较长,还有就是PX2价格是十万。
上图是TX2,256个GPU核,一般性能好的计算机的开发环境对程序员非常友好,东西全,资料非常多,很快上手。最重要的是TX2非常便宜,教育用户版不到三百美元,可以用它做台式机做不了的事情,供应充足,我们公司用TX2做了非常漂亮紧凑的车载盒子。
其他还有一些性能、定位差不多的芯片,比如NXP,它在车企用的非常多,可靠性、安全性都很好。现在新推出的i.MX8性能稳定,是六核的架构,带GPU,但也有供货问题。它在车载和智能仪表领域的占有率非常高。
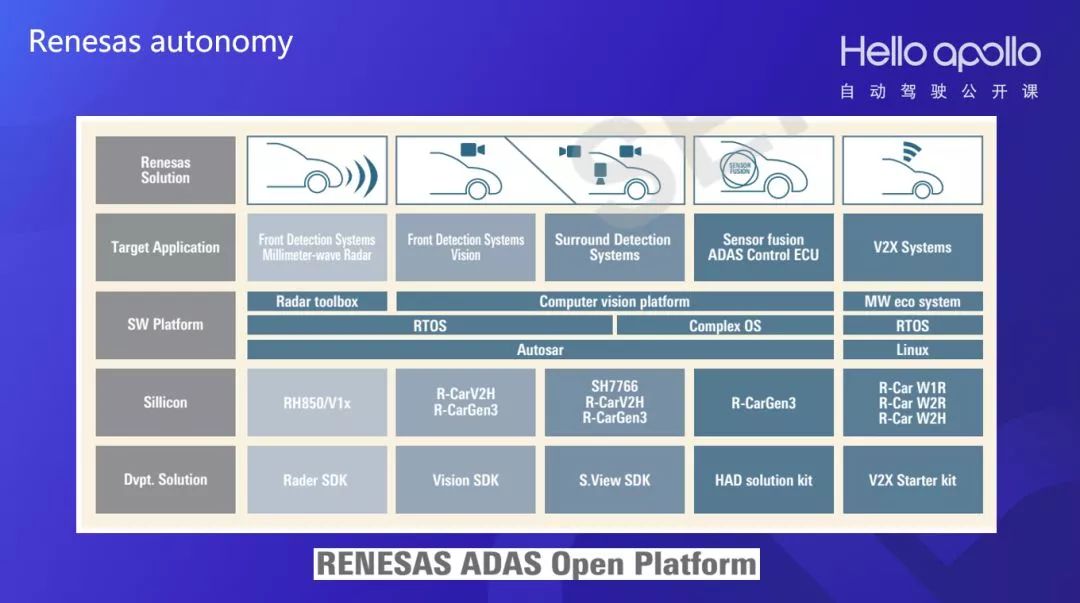
另一个是Renesas,一家汽车电子老牌厂家,在自动驾驶计算平台占有一席之地。
为什么我要把它做成分布式的?分布式部署真正是由功能和性能决定的。我们把自动驾驶模块划分一下,有两种分法。一种是Apollo分法,分成四个模块:感知、规划、决策和控制,另一种从性能区分,Sensor、Planning和Action。
现在智能驾驶计算平台的现状如何呢?目前没有一个芯片、计算平台、操作系统能够同时满足上述4个指标。
我们让控制模块跑在可靠的、安全的芯片上,但是满足了安全条件,计算力就跟不上了。感知模块要求强大的计算力,但是这种情况下再做安全,可能成本无法承受。所以最好的办法就是让合适的芯片运行合适的模块,让合适的操作系统来承载合适的模块。
我们把Apollo的四个模块拆分开,感知模块可以跑在高性能的感知平台上,控制模块可以跑在高可靠性的操作系统上。
我们提出一个构想,把控制模块跑在高可靠性的芯片上,感知模块用低成本的处理器。即使一台车要接十二个摄像机,一块芯片不能用了,感知部分摄像机宕掉,问题也不大,车还在控制中。但是控制模块出现问题就不行了。
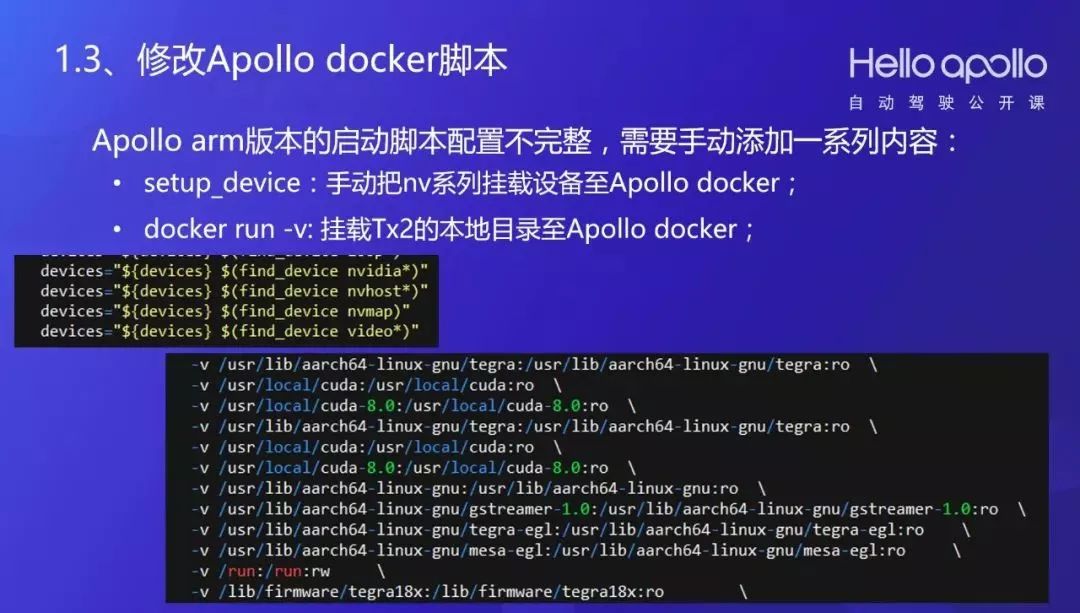
我们增加了TX2对Docker的支持,使用JetPack3.1刷机。内核缺少containers运行所需的支持,这是我们定制刷新内核的文件,这些都是在网上公开的。编译之后更新,然后重启,重启以后只要带container就说明这个内核已经可以安装到Apollo上了。
增加TX2对Docker的支持
Docker onTegra本身有下面的问题:
• TX-2 or other Tegra devices 不支持nvidia-docker
• 使用JetPack3.1刷机,内核缺少containers 运行所需的支持
• JetPack3.2解决了这个问题(我还没验证)
• nvidia-docker wrapper在TX2上不能正常运行,无法获取GPU设备
解决方法是:
• 定制内核,增加对containers 的支持
• 传递所需的参数给Docker,使之能够获取GPU设备
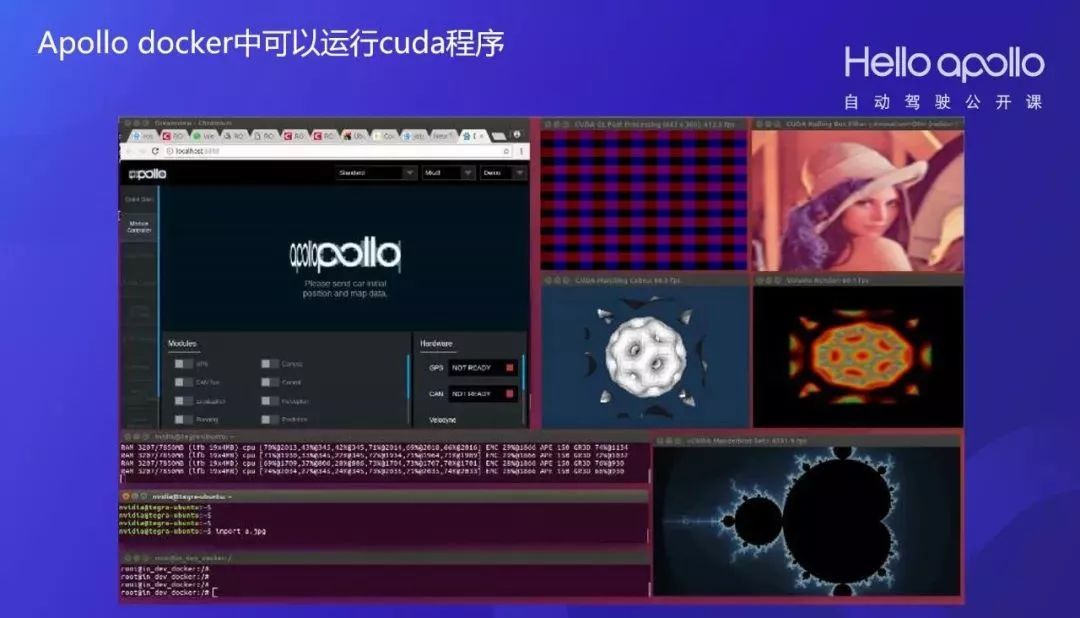
通过如上面几幅图中所述,增加TX2对docker的支持、定制内核配置文件、编译内核、修改Apollo docker脚本后,Apollo docker中可以运行cuda程序了。
编译Apollo
接下来编译Apollo:
• 构建缺少的依赖库:caffe(GPU版),vtk,需要自己写build文件,修改workspace配置文件;
• 重新编译arm版本的依赖库:QPSASES,IPopt,libfastcdr,libfastrtps;
• 重新编译版本不一致的依赖库:glog,gflags,protobuf;
• 修改Apollo中某些不兼容的代码;
感知模块Trafficlight中,caffe只提供了X86平台动态库,X86架构下SSE系列,arm平台无法使用,要么改写,要么直接跳过。
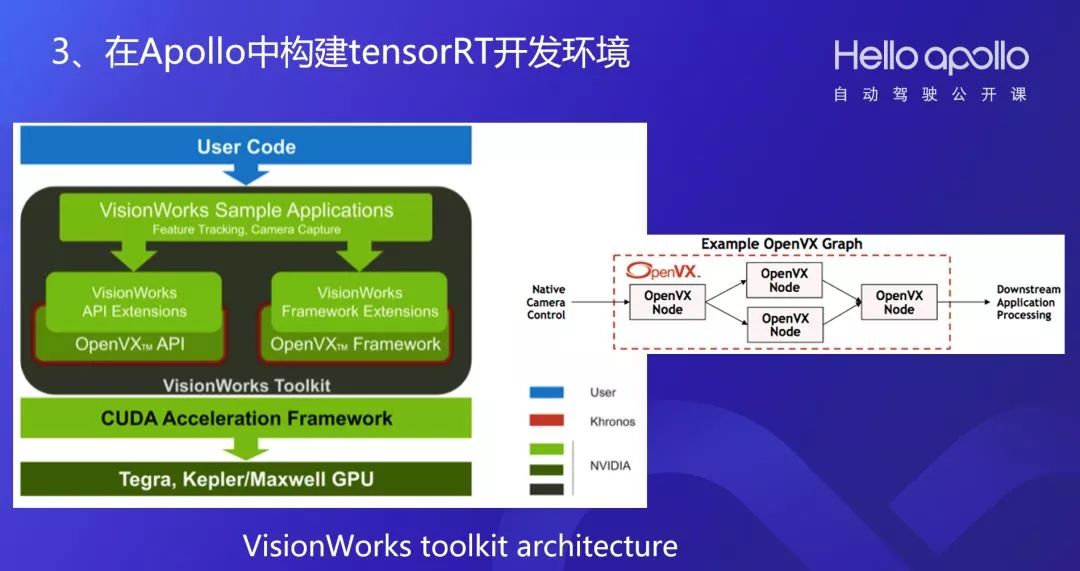
在Apollo中构建tensorRT 开发环境
在Apollo中构建tensorRT,存在以下问题:
• docker内缺少一系列的库;
• 缺少tx2相机驱动;
• 需要使用tegra定制的libGL.so;
• libgbm版本不匹配;
• 摄像机守护进程在主机端,docker内无法驱动;
解决办法如下:
1、用挂载或者copy的形式准备好所需的动态库,接近100多个;
12345678 | cp host /var/nvidia/nvcam/settings -> dockercp host /var/nvidia/nvcam/input -> docker-v/usr/lib/aarch64-linux-gnu:/usr/lib/aarch64-linux-gnu:ro \-v/usr/lib/aarch64-linux-gnu/gstreamer-1.0:/usr/lib/aarch64-linux-gnu/gstreamer-1.0:ro \-v/usr/lib/aarch64-linux-gnu/tegra-egl:/usr/lib/aarch64-linux-gnu/tegra-egl:ro \-v/usr/lib/aarch64-linux-gnu/mesa-egl:/usr/lib/aarch64-linux-gnu/mesa-egl:ro \-v/run:/run:rw \-v/lib/firmware/tegra18x:/lib/firmware/tegra18x:ro \ |
2、使用libdrm-2.4.80以上版本重新编译;
3、为tegra版本libGL.so建立软连接;
4、修改主机配置,让摄像机守护进程在docker内启动;
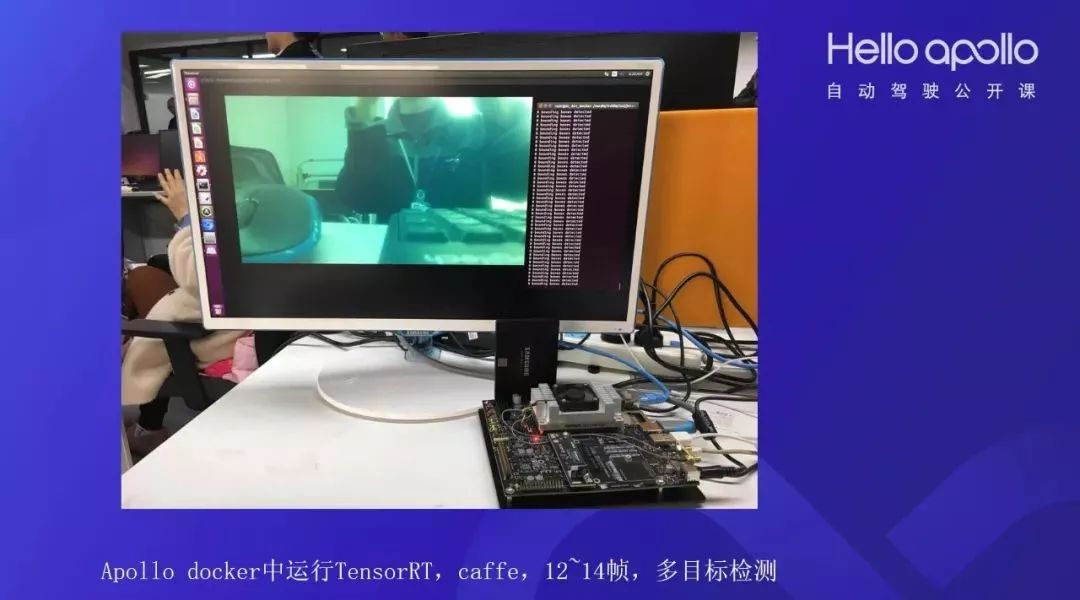
构建tensorRT完成后,就可以在Apollo Docker中运行tensorRT,实现12-14帧的多目标检测。
目前成果和后续工作
为大家说一下我们的阶段性成果,目前已发布部分资源供测试:
• Apollo docker on TX-2的完整镜像;
• 使用不同操作系统重刷Jetpack时会遇到编译错,这里提供完整的内核源码,无需自行下载并执行xconfig;
• 一些需要在arm下单独编译的库;
• 修改的Apollo的docker脚本文件;
• 基于Bazel构建的cuda应用程序开发模板
后续我们将做的工作有:
解决ROS跨版本通信问题
全面使用Nvidia Visionworks对图像操作进行改写
使用TensorRT对深度学习相关的功能模块进行inference优化
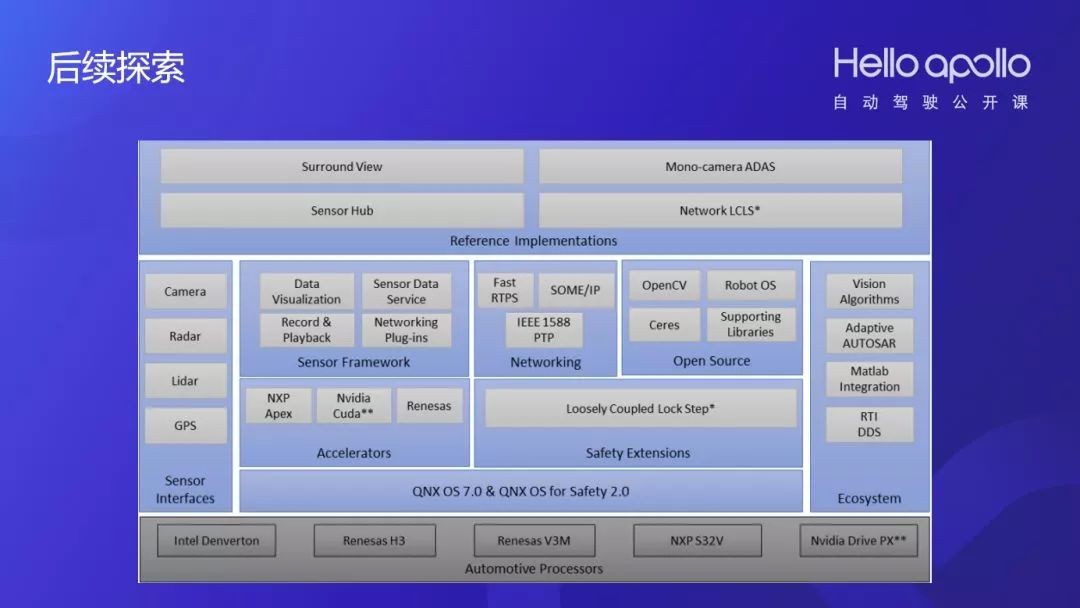
对其他车载计算平台的测试和验证
针对QNX的移植适配工作
车载嵌入式设备的封装
到2018年5月份,我们会提出专门针对ADAS的QNX开发包。如果说可以解决ROS跨版本通信的问题,那么我们把Apollo往QNX发展是可行的。
上一篇:2020年智能汽车及硬件芯片走势及市场分析
下一篇:自动驾驶迎来它的黄金时代_制造一台激光雷达仅用8分钟
推荐阅读最新更新时间:2024-11-14 20:37

 纯电动汽车动力电池及管理系统设计 (董艳艳,王万君主编)
纯电动汽车动力电池及管理系统设计 (董艳艳,王万君主编)
Vishay线上图书馆

- ADP2442 降压型 DC 至 DC 稳压器,1 A 输出电压为 5 V
- 适用于M24LR16E-R的45 mm x 75 mm天线参考板,仅供参考
- 使用 IXYS 的 Z86L33 的参考设计
- 一种用于花园照明的 LED 室内和室外 LED 驱动器
- 黄淮学院立创杯电子设计大赛-10019221A-韩世轩
- 使用 Analog Devices 的 ADP3304AR-2.7 的参考设计
- EDA技能大赛
- hp Windows Hello摄像头模组 焊盘转接 降压
- LT1308BCS8 锂离子至 12V/300mA 升压型 DC/DC 转换器的典型应用电路
- 使用 Diodes Incorporated 的 MAX749 的参考设计






 京公网安备 11010802033920号
京公网安备 11010802033920号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}