“Hotchips”每年8月举行,去年在斯坦福大学纪念礼堂开幕时,大约有1200人参加了这次活动,参加人数创了历史记录,这使得斯坦福大学会场的容量更加庞大。此次2020年的Hotchips将会在形式上有很大的不同,但在内容上不会有任何的精简。期间许多牛叉的芯片公司将带来最新的处理器创新。
大规模数据中心机器学习
8月16日的专题报告涵盖了大规模数据中心机器学习部署,百度、Cerebras、谷歌和Nvidia都会参加。在下午的会议上,来自Facebook、谷歌、IBM、英特尔、微软和UCSB的研究人员进行了演讲,探讨了量子计算机。两者都应该对广泛的群体感兴趣。
两个主题演讲
今年的两个keynote包括英特尔高级副总裁、首席架构师和架构、图形和软件总经理Raja M. Koduri,演讲题目《No Transistor Left behind》。
在强调机器学习处理的会议上,来自DeepMind的杰出工程师Dan Belov,进行了精彩的演讲。
服务器处理器
周一的会议从服务器处理器开始,其中,最有意思的可能是IBM POWER 10。该芯片是对POWER架构的一次重大重新设计,因为它为更先进的三星芯片厂7nm EUV工艺保留了12nm内嵌DRAM。IBM还将对z15大型机系列进行更新。在会议的最后,英特尔公布了更多关于10nm+ Icelake-SP Xeon扩展处理器的细节,而Marvell提供了更多关于其即将推出的基于arm的ThunderX3服务器处理器的细节。所有主流服务器处理器都装载了10个高性能CPU核,具有大量的内存带宽和I/Os。
Ice Lake-SP技术细节大揭秘
其中Intel带来的Ice Lake-SP,也是他们的首款10nm制程服务器处理器的架构详情。

Ice Lake-SP将作为第三代Xeon可扩展处理器登场,是Whitley平台的组成部分,只有单路或双路,四路和八路是前不久发布的Cooper Lake独占。它在内核上换用了Sunny Cove微架构,相比起原本各种基于Skylake的衍生微架构,Sunny Cove在IPC上面有很大的提升。

Ice Lake-SP处理器使用10nm+制程,就是宣传名为10nm SuperFin的制程,单个处理器最多应该能够集成28个核心,其基础架构仍然沿用Skylake-SP开始的Mesh架构。
随着新内核到来的是一系列新的指令集,这里面有一些我们在消费级的Ice Lake上面就已经见到了。

通过专用指令集,Ice Lake-SP在诸多加解密计算上的性能相比起Cascade Lake要高出很多,最夸张的有8倍。不过如果想要享受到性能增幅,软件需要针对新的指令集进行重新编译。
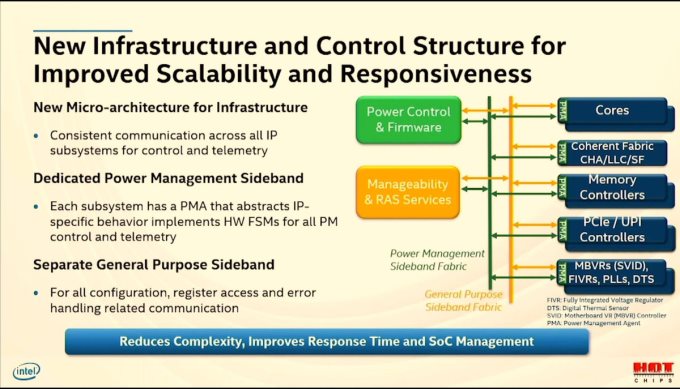
看完内核,再来说说SoC上面的周边模块。Ice Lake-SP引入了新的“基础设施”,一条新的通用目的总线,将管理端和RAS服务与内部相连,另一条电源管理总线,同样连接到内部的核心、IO单元等元器件上。两条新总线的加入使得Ice Lake-SP的所有IP Core与外界有一个不间断的通讯,能够更好的被控制、管理。此外所有的子系统均有自己专用的一套电源管理单元。
Intel还在Ice Lake-SP上引入了新的速度选择技术(Speed Select Technology),允许用户重新对处理器的频率进行重新配置,可以进行配置的规格有性能Profile、基础频率、核心功率和睿频频率。这项技术将会在部分Ice Lake-SP处理器上可用,同时它可以在处理器运行时进行动态修改。
微软Xbox Series X系统架构闪亮登场
此外,微软公布了Xbox Series X系统架构,公开SoC细节。微软这次给到了非常详尽的资料,详细描述了Xbox Series X上面所用SoC的架构。

官方介绍了一番这台主机新支持的诸多特性,诸如DXR、VRS、Mesh着色等等,这些我们大多都烂熟于心,而右边的某些特性则是首次公开,尤其是在音频方面,Xbox Series X支持了许多新特性。

对于我们这帮架构爱好者来说,最兴奋的莫过于这张Die Shot。这是Xbox Series X上所使用的SoC的Die Shot,它使用台积电的N7e工艺(与N7P之间有什么关系有待考察),集成有153亿个晶体管,核心面积高达360.4mm2,SoC与AMD合作开发。
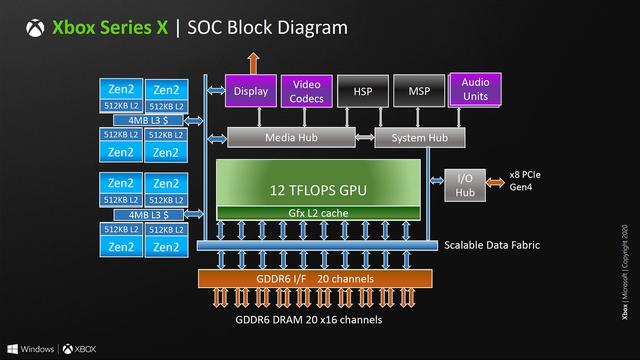
简化一下就是上面这张图,可以看到其整体结构仍然类似于AMD近几年的APU,不过相比起Renoir,它还是有很大的不同。CPU部分跟Renoir比较相近,同样是两组Zen 2 CCX,每组CCX带有4MB的三级缓存。CPU在关闭超线程的情况下可以跑到3.8 GHz,开启超线程会降低0.2 GHz的最高频率。
CPU和SoC的其他部分通过一条可扩展的数据总线进行互联,推测是基于IF总线。总线上面连接了显示控制单元、媒体编解码单元、安全模块、存储加密解密解压缩单元、GPU、IO Hub和内存控制器。

GPU部分设计了28组Dual CU单元,其中有两组被屏蔽,实际会有26组工作的Dual CU,也就是52组CU。由于GPU部分基于RDNA 2架构,我们也由此可以一窥RDNA 2架构的细节。

从Dual CU单元的组成来看,RDNA 2的基础单元架构与RDNA没有太大的区别,比较亮眼的是每个Dual CU中集成了两个硬件加速光线追踪的处理单元,也就是每CU有一个,这也是RDNA 2支持硬件光追的秘诀所在。
移动处理器
在这次的移动处理器会议中,x86处理器的竞争对手AMD的7nm Ryzen 4000 APU将与英特尔的Tiger Lake移动客户端CPU展开竞争。这已经成为一场真正的角逐,因为AMD的移动处理器有了很大的改进。
中国阿里巴巴公司就RISC-V在云计算和边缘计算中的应用进行了演示。这是关于RISC-V设计的两个报告之一,揭示了生态系统的告诉发展。Arm对它的高性能Cortex-M55微控制器核心和Ethos ML加速器进行了详细介绍,证明了与它的高度相容性。
FPGA
周二的会议以最新的FPGA和可重构逻辑开始,老牌英特尔(Agilex)和Xilinx (Versal Premier)以及新面孔Tenstorrent将悉数登场。后者正在研究机器学习应用程序,使用芯片和软件为ML数据流配置小型处理元素。
SOC,可替代的DPU
在网络和分布式系统上有一个更加开放的会议,包括一个用于数据中心的Intel/Barefoot高性能以太网交换机。这是阿里巴巴关于裸金属云存储扩展SoC的第三次发布会。随后DPU(分散处理单元)将会登场。
谷歌会带来惊喜吗?
在大数据中心机器学习会议上,没有Nvidia(它在GPU会议上展示了A100)的身影。谷歌又回到了TPUv2和TPUv3的话题上,看起来这是在倒退,因为他们已经为TPUv4预置了一些MLPerf数据。也许谷歌会带来一些惊喜。此外,苏黎世联邦理工学院的第二个RISC-V展示了采用4096核的芯片设计,用于高效浮点处理。
去年Hotchips最大胆的设计是Cerebras Wafer Scale Engine。黑马MegaChips是一个集成逻辑和内存的芯片,面积为46225平方毫米,拥有40万个核心和18GB内存。该公司今年将会带来下一代设计蓝图——预计至少会从第一代产品的16nm工艺缩减到7nm工艺。
会议以ML推理为主题,共计四个演讲,其中三个来自中国公司:阿里巴巴、百度和商汤科技。最激进的ML推理设计是Lightmatter,它使用硅光子学进行ML加速。
虽然普通消费者不会关注Hot Chips,但是对芯片架构等相关技术感兴趣的朋友,可以从这次会议中了解很多新芯片的技术架构。虽然Hot Chips是一个学术性会议,但也不是你想的那样拘谨,
这是一个可以和朋友聊聊天、了解最新行业八卦的好机会。但是现在会议是虚拟的。但另一方面,由于有了三天的打包内容,包括实时视频和录制回放,现在比以往任何时候都更容易访问。没有活动场地和食物的费用,世界各地的工程师、教授和学生也更能负担得起这个会议。幸运的是,这次会议的赞助商一直在支持这次活动,这也使会议的费用保持在可承受的水平。
上一篇:助力汽车智能化发展,纳芯微传感器信号调理芯片问市
下一篇:新一代硅光子芯片Lightmatter Mars问市
推荐阅读最新更新时间:2024-11-20 23:45

 现代编译原理 C语言描述 (安佩尔)
现代编译原理 C语言描述 (安佩尔) 零基础学电子与Arduino:给编程新手的开发板入门指南
零基础学电子与Arduino:给编程新手的开发板入门指南

- 1.8V DC 至 DC 单输出便携式电源
- AM3GW-2405SZ 5V 3 瓦 DC-DC 转换器的典型应用
- 适用于汽车类电池组监控的隔离式分流/电压测量参考设计
- DC1788B-A,使用 LT4275AIDD PoE+ PD 控制器的演示板,符合 IEEE 802.3at/IEEE 802.3af
- DC2026B-KIT,Linduino 一款隔离式 Arduino 兼容演示板,带有 LTC2607/LTC2422 (DC934A) 演示板
- 使用 Analog Devices 的 LT3470IDDB 的参考设计
- LT1086CT-5 用于改善纹波抑制的低压差正稳压器的典型应用
- 使用 Microchip Technology 的 LX1682 的参考设计
- makerPower Solar:面向物联网的智能太阳能发电系统
- 使用 Analog Devices 的 LTC2607IDE-1 的参考设计












 京公网安备 11010802033920号
京公网安备 11010802033920号